深度学习初步,全连接神经网络,MLP从原理到实现(三)实现部分,用java实现MLP
原理部分完全参照另外2篇:
深度学习初步,全连接神经网络,MLP从原理到实现(一)原理部分,反向传播详细解释和实际计算例子
深度学习初步,全连接神经网络,MLP从原理到实现(二)原理部分,过拟合,激活函数,batchsize和epochs,训练DL模型的建议
说明:这个实现全部用java实现,依赖矩阵运算库jblas和画图的一个库jfree(不需要画学习率衰减曲线的可以不用这个库),无论是预测还是反向传播求梯度都是基于矩阵/向量运算的,这样更简洁明了。使用了多线程来并行的预测和训练,但是速度仍然比GPU跑的慢好多,项目 用eclipse构建,导入到eclipse可直接使用。完整源码见我的GitHub:https://github.com/colin0000007/MLP4j,如果觉得可以,点个star啊!!
这篇文章我会挑一些重要部分的源码说明,主要是反向传播,参数更新等。整体的源码设计参照了keras。使用new Sequential,然后添加layer,最后train,完整的例子参照源码中的MinistExample(测试Minist数据集)。
public static void main(String[] args) {
loadData();
Sequential model = new Sequential();
//必须首先设置Input
model.setInput(new Input(x[0].length));
model.addLayer(new Dense(400,ActivationFunction.RELU));
model.addLayer(new Dense(400,ActivationFunction.RELU));
model.addLayer(new Dense(10,SoftMax.SOFTMAX));
System.out.println("x_train:("+x.length+","+x[0].length+")");
//衰减可以使用默认的ExponentialLearningRateDecay.defaultDecay,默认lr初始0.2可以修改
//model.trainParallel(x, y, 400, 20, ExponentialLearningRateDecay.defaultDecay);
//衰减使用ExponentialLearningRateDecay.noDecay可以不进行lr的衰减,lr默认0.2可以修改
//model.trainParallel(x, y, 400, 20, ExponentialLearningRateDecay.noDecay);
ExponentialLearningRateDecay decay =
new ExponentialLearningRateDecay(2, 0.2, 0.8, false);
model.trainParallel(x, y, 400, 20, decay);
//以上参数迭代20个epoch后训练集acc=0.9860282
}好了,下面直接说说源码中比较重要的部分:
前向传播的源码:
/**
* 前向传播计算a和z这两个list
* 每个list保存了每一层的a或者z
* 只计算单个样本
* 每个样本的forwardPropagation可以并行,单个样本的forwardPropagation矩阵运算可以并行
* @return
*/
public ArrayList[] forwardPropagation(double[] x) {
ArrayList[] za = new ArrayList[2];
za[0] = new ArrayList<>(layers.size());
za[1] = new ArrayList<>(layers.size());
double[] input = x;
for(int i = 0; i < layers.size(); i++) {
double[][] weights = layers.get(i).getWeights();
double[] biases = layers.get(i).getBiases();
DoubleMatrix w = new DoubleMatrix(weights);
DoubleMatrix a = new DoubleMatrix(input);
DoubleMatrix b = new DoubleMatrix(biases);
// z = w*input + b
DoubleMatrix zMatrix = w.mmul(a).addi(b);
double[] zs = zMatrix.toArray();
//计算这一层的输出
ActivationFunction sigma = layers.get(i).getActivationFunction();
double[] as = sigma.functionValue(zs);
za[0].add(zs);
za[1].add(as);
input = as;
}
return za;
} 这里的forwardPropagation是针对单个样本计算的,前向传播就是要计算一个样本输入经过每一层的z值和a值,所以这里就是遍历所有layer,计算z和a,z和计算直接对应原理部分的矩阵运算,w*input+b,w就是一个权重矩阵,b是偏置向量,参照Dense(全连接层)的设计:
/**
* 全连接层
* @author outsider
*
*/
public class Dense extends Layer{
//wij 指的时当前层第i个单元到上一层的j个单元连接的权重。
//所以weights的行数是本层的单元个数,列数是上一层单元的个数
private double[][] weights;
//偏置
private double[] biases;
//当前层的单元个数
private int units;
//激活函数
private ActivationFunction activationFunction;
public Dense(int units, ActivationFunction activationFunction) {
this.units = units;
this.activationFunction = activationFunction;
}
/**
* 初始化权重参数
* @param lastUnits
*/
public void init(int lastUnits) {
this.biases = new double[units];
//权重随机初始化
this.weights = DoubleMatrix.randn(units, lastUnits).divi(10).toArray2();
DoubleMatrix doubleMatrix = new DoubleMatrix();
}
}
a的计算是把计算后的z送到对应层的激活函数中一个个计算a值。这里所有layer的a和z都要保存。保存z是因为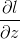 中计算
中计算![]() 需要用到,保存a在计算
需要用到,保存a在计算![]() 会用到,和原理部分对应的。
会用到,和原理部分对应的。
反向传播计算部分源码:
/**
*
* @param x 单个样本的x
* @param y 单个样本的y
* @return 每一层的梯度矩阵,注意是一个3维数组,每一个矩阵的尺寸不一样
*/
public Gradient backPropagation(double[] x, double[] y) {
//(1) 前向传播
ArrayList[] za = forwardPropagation(x);
ArrayList z = za[0];
ArrayList a = za[1];
//(2) 反向传播计算 partial L / partial Z,这直接是偏置的梯度
double[][] LZ = new double[layers.size()][];
//计算最后一层的 partial L / partial z
LZ[LZ.length - 1] = layers.get(layers.size() - 1).getActivationFunction()
.partialLoss2PartialZ(null, a.get(a.size() - 1), y);
//计算其他层的 partial L / partial z
for(int i = LZ.length -2; i >=0; i--) {
Dense layer = layers.get(i);
//1.求激活函数的一阶导数
double[] sigmaP = layer.getActivationFunction().firstDerivativeValue(z.get(i));
//2.后一层的权重矩阵的转置乘以 partial L / partial z 向量
DoubleMatrix m1 = new DoubleMatrix(layers.get(i + 1).getWeights()).
transpose().mmul(new DoubleMatrix(LZ[i+1]));
// 1和2得到的向量对应元素相乘即为结果
LZ[i] = new DoubleMatrix(sigmaP).muli(m1).toArray();
}
//(3).计算梯度
//partial L / partial Z的 列向量乘以上一层的输入a行向量
double[] input = x;
double[][][] gradients = new double[layers.size()][][];
for(int i = 0; i < gradients.length; i++) {
DoubleMatrix aVec = new DoubleMatrix(input);
DoubleMatrix lzVec = new DoubleMatrix(LZ[i]);
aVec = aVec.reshape(aVec.columns, aVec.rows);
gradients[i] = lzVec.mmul(aVec).toArray2();
input = a.get(i);
}
Gradient gradient = new Gradient(gradients, LZ);
return gradient;
} 计算需要倒着来,最后一层的在激活函数中被计算,也就是partialLoss2PartialZ,然后从倒数第二层开始计算,先求这一层的激活函数的一阶导数,这时候需要用到forwardPropagation中对应层的z值,计算后是一个double[] sigmaP向量,然后计算一个中间结果,后一层权重矩阵的转置和后一层向量的乘积得到一个向量,最后将这2个向量对应元素相乘得到该层的,对应原理部分的公式:

迭代完所有的layer即可求得全部层的。
求梯度源码:(求梯度实在train中实现的所以直接看train,为了便于理解这里不看并行训练的方法)
/**
* 训练
* @param x
* @param y 每一个标签必须one-hot编码,所以是二维数组
* @param lr 学习率
* @param batchSize 每次梯度下降的更新参数用到的样本个数
* @param epochs 在整个样本集上做多少次的训练
* @param lrDecay 学习率指数衰减
*/
public void train(double[][] x, double[][] y,
int batchSize, int epochs, ExponentialLearningRateDecay lrDecay) {
//一个epoch中的各个batch可以并行,一个batch之间各单个样本之间可以并行
double lr = lrDecay.lr;
DoubleMatrix yM = new DoubleMatrix(y);
int[] yTrue = yM.rowArgmaxs();
this.classNum = layers.get(layers.size() - 1).getUnits();
//1.划分样本
int sampleNum = x.length;
//分多少批
int batchNum = sampleNum / batchSize;
System.out.println("batchNum:"+batchNum);
int left = sampleNum % batchSize;//样本余数
//保存样本的索引位置
List sampleIndices = new ArrayList<>(x.length);
for(int i = 0; i < sampleNum; i++) {
sampleIndices.add(i);
}
// epoch循环
for(int i = 0; i < epochs; i++) {
//对学习率衰减
lr = lrDecay.decayLR(i);
System.out.println("epoch "+(i+1)+"/"+epochs+",lr="+lr);
//batch循环
for(int j = 0; j < batchNum; j++) {
int c = left *((j+1)/batchNum);
double[][] batchX = new double[batchSize + c][];
double[][] bathcY = new double[batchSize + c][];
System.out.println("epoch..."+(i+1)+"/"+epochs+",batch..."+(j+1)+"/"+batchNum+","+"batchSize="+batchX.length);
int offset = j * batchSize;
for(int k = j * batchSize; k < (j+1)*batchSize + c; k++) {
batchX[k-offset] = x[sampleIndices.get(k)];
bathcY[k-offset] = y[sampleIndices.get(k)];
}
//训练,一个一个样本计算梯度,这个过程可以同时进行。
//将每个样本的梯度累加
Gradient gradient = backPropagation(batchX[0], bathcY[0]);
double[][][] totalWeightsGradient = gradient.weightsGradient;
double[][] totalBiasesGradient = gradient.biasesGradient;
for(int m = 1; m < batchX.length; m++) {
Gradient gradient2 = backPropagation(batchX[m], bathcY[m]);
double[][][] weightsGradient = gradient2.weightsGradient;
double[][] biasesGradient = gradient2.biasesGradient;
for(int f = 0; f < weightsGradient.length; f++) {
totalWeightsGradient[f] = new DoubleMatrix(totalWeightsGradient[f]).
addi(new DoubleMatrix(weightsGradient[f])).toArray2();
totalBiasesGradient[f] = new DoubleMatrix(totalBiasesGradient[f]).
addi(new DoubleMatrix(biasesGradient[f])).toArray();
}
}
//梯度除以N
for(int k = 0; k < layers.size(); k++) {
totalBiasesGradient[k] = new DoubleMatrix(totalBiasesGradient[k])
.divi(batchX.length).toArray();
totalWeightsGradient[k] = new DoubleMatrix(totalWeightsGradient[k]).
divi(batchX.length).toArray2();
}
//更新参数
for(int f = 0; f < layers.size(); f++) {
Dense dense = layers.get(f);
double[][] oldW = dense.getWeights();
double[] oldBia = dense.getBiases();
// w = w - lr * gradient
double[][] newW = new DoubleMatrix(oldW).
subi(new DoubleMatrix(totalWeightsGradient[f]).mul(lr)).toArray2();
double[] newBia = new DoubleMatrix(oldBia).
subi(new DoubleMatrix(totalBiasesGradient[f]).mul(lr)).toArray();
dense.setWeights(newW);
dense.setBiases(newBia);
}
//每20倍批次输出一次训练信息
/*if((j+1) % 20 == 0) {
int[] yPredicted = predictAndReturnClassIndex(x);
//训练集上的准确率
float acc = accuracy(yPredicted, yTrue);
System.out.println("\n"+(j+1)*batchSize + "/" + x.length+"........acc:"+acc+"\n");
}*/
}
double[][] yPre = predictParallel(x);
int[] yPredicted = new DoubleMatrix(yPre).rowArgmaxs();
double loss = loss(yPre, y);
float acc = accuracy(yPredicted, yTrue);
String print = "epoch " +(i+1)+ " done"+"........acc:"+acc+",total loss:"+loss;
System.out.println(print);
//打乱数据位置
//acc会有一些不稳定,估计也和这个操作有关系。
//测试后发现,shuffle有利用梯度下降
Collections.shuffle(sampleIndices);
}
} 重点看//batch循环中的代码,再说说epoch和batchsize,指定了epoch和batchsize和,需要对训练样本划分成多少个batch对应源码中的batchNum,然后每一个batch计算梯度,更新一次参数。训练过程中每次batch的划分后每个batch里的样本是随机的,sampleIndices保存了最初的样本索引位置,每一轮epoch这些位置被打乱,我已经验证过,打乱后的效果更好。接下来有了一个batch的数据,batchX和batchY就需要计算分别计算里面样本的梯度,先进行一次forwardPropagation然后backPropagation就有了a,z和,然后梯度的公式是:

列向量乘以a向量的转置就可以得到梯度,最后将所有样本的梯度累加起来,最后更新梯度w=w-lr*gradient
这些过程只要理解了理论部分就能实现。注意这里梯度总和一定要除以样本的个数。我之前没有除出现了准确率一直维持再0.1左右。至于原因我大概猜测了下,如果不除以N,那么优化的总的loss,如果除以N那么优化平均loss,想象loss的是一个曲面,这时候从较高部分到较低部分地势相差很高,梯度下降学习率足够大才可能会有效果,如果优化平均loss,那么最大的loss值也不过是单个样本的最大的loss,远远小于多个样本的loss总和,这时候较高部分与低洼部分距离不会相差很大,所以优化时学习效率小一点依然效果显著。
预测过程和forwardPropagation一样,只是我们不需要保存中间层的a和z,只需要最后一层softmax的a向量作为结果。
感受:实际上我觉得只要理解了反向传播和梯度计算,就很简单,我觉得写起来比CRF那种模型还简单些。
下面是实现过程中的一些问题记录:
1.遇到的问题:nn参数初始化
如果参数初始太大,而且没有负数,会造成溢出的情况,
因为softmax作为输出层,里面存在着指数,输入太大则
会溢出。建议初始化较小的参数,并且必须有正负,比如
-0.25到0.25之间,关于参数初始化也有很大的学问,好的
参数初始化可以使收敛更快。
2.遇到的问题
//之前不work主要有两个原因:
//(1)梯度最后一步计算的矩阵化公式有错
//(2)损失函数没有除以N(我不知道为什么这个影响这么大,这直接导致了效果完全不行)
//目前存在的问题
//(1)效率不够高
//(2)收敛不够快,前面设置的参数情况下,epoch 2才达到0.82左右的acc
//3.23更新:
//使用了学习率指数衰减,效果好多了
//参数建议,如果epochs比较小,那么lr也要小一点
3.关于并行
之前使用call(),或者线程的join()来实现主线程等待子线程完成后继续
发现效果都不好,比串行都慢,但使用countDownLatch这个对象后发现
竟然速度快了2倍左右
3.线程级别的计算基于单个样本还是多个样本?
在我自己的实现中,单个线程就是单个样本的计算,因为线程池最大也就处理器个数+1,
所以如果直接将样本划分为处理器个数份,来并行,可能效果会好一些,不用涉及到大量
线程的管理。
实验了下:差不多能快个1000毫秒
4.并行对比
//train_parallel:4m22s one epoch
//train:7m07s
//train_parallel 比 train快1.63倍
使用并行预测大约快出2倍
5.关于并行训练的实现
将每个batch拆分成处理器个数这么多份,然后并行,每个线程保存了该线程计算的所有样本的梯度和
最后将这些线程中的梯度加起来就可以求得这个batch的梯度
不能单个样本作为一个线程,这样保存梯度会占用很大的内存
不能并行去修改总的梯度变量,这样互斥使得并行效果不那么有效了
6.使用方法
借鉴了keras的设计,
model = new Sequential()
model.add(layer)
.....
model.train()