情感计算 - 情感倾向性分析
目录
1 背景及意义
2 文本情感分析词典与数据库
3 文本情感特征
4 文本情感识别
5 舆情分析
6 总结
1 背景及意义
1. 概念: 情感倾向性分析:是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程;识别用户对事物或人或一句话的看法、态度,即判别用户对评价对象所持有的情感倾向。
2. 文本情感分类:
情感分析粒度(篇章级、句子级、短语级、词语级);
情感信息抽取(观点持有者, 评价对象,评价词或短语,主观性关系),找到预料中情感的来源和受体;
情感信息分类(主客观分类,情感极性分类),最常见的褒贬二元分类,以及更细致的多元分类,按照极性分类:正向,负向,中性;
3. 文本情感分析应用
商品评论,电影评论,个性化观点挖掘,用户兴趣挖掘
2 文本情感分析词典与数据库
1. 情感词典包括: 情感词典(高兴、悲伤等)、程度词典(非常、稍微)、否定词典(没有、木有)、连词词典(然而、不过)
2. 现有情感词典
General Inquirer(GI)词典:1996年开发,英文文本情感词典
HowNet知网: 中、英文词语所代表的概念为描述对象
SentiWordNet:是WordNet中英文词典中用于情感分析的词典
主观词典:OpinionFinder系统
3. 情感词典获取:
手工方法: wordnet, hownet
词典方法:先从种子词典开始(人工标注的少量情感词典),通过语义相似度找到种子词典的同义词、反义词
基于语料库:从种子词典开始,通过共现度、关系词、Latent Semantic Analysis等方法扩展词典
4. 英文情感语料
MPQA: 535 news articles(subjective, objective; P, N, O)
Movie review data: IMDB, Document-level 2000, Sentence level 5000
Custom review data: Product reviews
Multi-product reviews: Book, Electronic, Kitchen, DVD; 2000 in each domain
TREC Blog corpus: Blog data, 3,000,000 Webpages
Multiple-aspect restaurant reviews: 4,488reviews, Each review labeled as 1-5 stars
5. 中文情感语料
ChnSentiCorp_htl_all数据集
7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
waimai_10k数据集
某外卖平台收集的用户评价,正向4000 条,负向约 8000 条
online_shopping_10_cats数据集
10 个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、
酒店),共 6 万多条评论数据,正、负向评论各约 3 万条
weibo_senti_100k数据集
10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条。
simplifyweibo_4_moods数据集
36 万多条,带情感标注 新浪微博,包含 4 种情感,其中喜悦约 20 万条,愤怒
、厌恶、低落各约 5 万条
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/ https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/
https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/
3 文本情感特征
1. 常见的文本表示模型有:
向量空间模型(如one-hot,维度灾难,词汇鸿沟);
布尔模型(将向量空间模型中的权重限制为0或1,0表示特征不存在,1表示存在,不能反应特征词语对文档的贡献程度);
词向量模型(文本内容处理,简化为向量空间中的向量运算,Word2vec, Gensim, Glove);
2. 文本特征提取方法
文档频率法:TF-IDF(词频term frequency-逆文档频率法 inverse document frequency)
词频(TF) = 某个词在文章中出现的次数 / 文章的总词数
逆文档频率(IDF) = log(collection总文档数 / (包含该词的文档数 + 1))
TF-IDF = TF x IDF
也就是说如果一个词在某一文档中出现次数较多,在整体文档中出现次数较少,则其TF-IDF值就大;
信息增益法:依据某特征项为整体分类所能提供的信息量多少来衡量该特征项的重要程度,从而决定该特征项的取舍;
信息增益是不考虑任何特征时文档的熵,与考虑该特征时文档的熵的差值。
熵:表示随机变量的不确定性;
条件熵: 在一个条件下,随机变量的不确定性
信息增益: 熵 - 条件熵,表示在一个条件下,信息不确定性减少的程度
卡方统计法:
卡方值可以衡量词与类别的相关程度
观察实际值与理论值的偏差来确定理论正确性;
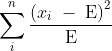
假设理论值为E,实际值为x,xi 表示样本
如果差值很大,则认为与原假设(独立假设)不符合,认为词与类别很相关
4 文本情感识别
1. 分为四种
基于情感词典
基于统计的机器学习
基于深度学习
基于预训练模型
2. 基于情感词典的文本情感识别
主要以情感词典为基础,通过判断文本中是否出现该情感词,来判断文本情感;
需要考虑:不同领域下,相同情感词表达有差异;
不能有效处理带有否定词的情况;
隐含情感信息的文本效果较差;
情感词典的系统框架:

3. 基于统计的机器学习文本情感识别
用机器学习算法对已标记的语料进行训练,再将训练过的分类器用于未知文本的情感分类
朴素贝叶斯;
支持向量机;
最大熵模型;
不仅考虑情感关键词和其他词汇的倾向性,而且对文本中的标点以及多个词汇出现的频率特征自动学习
4. 基于深度学习的文本情感识别
FastText 模型
TextCNN模型
TextCNN模型
TextRNN + Attention模型
FastText模型: 句子中所有的词向量进行平均,然后接一个softmax层分类,完全没有考虑词序信息
TextCNN模型: 利用CNN来提取句子中类似n-gram的关键信息

TextRNN模型: 双向LSTM从某种意义上可以理解为可以捕获变长且双向的n-gram信息
对此结果的贡献。
5. 基于预训练的文本情感识别
基于Bert模型的文本情感识别
基于XLNet模型的文本情感识别(XLNet 是在Bert模型基础上的改进,提出的一种泛华自回归预训练方法)
5 舆情分析
1. 舆情分析,又称为社交媒体情感分析,基于新闻媒体的情感分析多用于舆论分析,服务于政府部门;
2. 舆情分析与情感分析区别:
用途不同:基于产品评论的情感分析多用于商业,舆情分析多用于政府部门;
复杂性不同: 舆情分析是个比较复杂的系统,涉及更多的技术;
舆情分析信息来源更广泛:新闻评论,BBS,聊天室,博客,RSS等;
舆情分析具有突发性、直接性、偏差性:
直接性:通过BBS,新闻点评和博客网站,网民可以立即发表意见,下情直接上达,民意表达更加畅通;
突发性:网络舆论的形成往往非常迅速,一个热点事件的存在加上一种情绪化的意见,就可以成为点燃一片舆论的导火索;
偏差性:由于发言者身份隐蔽,并且缺少规则限制和有效监督,网络自然成为一些网民泄愤情绪的空间;
3. 舆情分析系统框架
数据采集层:负责从社交媒体中采集资源;
数据处理层:对采集的原始数据进行预处理
报告展示层:舆情分析的结果最终以报告、统计图表等形式展示给用户,为用户下一步决策提供指导依据。
4. 舆情具有突发性,通常会用到网络爬虫技术,在社交媒体网站上爬取开源数据
首先从社交媒体网页中抓取用户的链接地址并存放如网页链接地址队列中;
从网页链接地址队列中依次读取待抓取链接地址,访问并下载该页面;
通过解析下载页面,把需要的文本数据以及对应图片保存,同时检测是否有其他用户链接地址;
跳转步骤(2),直到网页链接地址队列为空。
5. 基于概率图模型的舆情分析
通过分析训练语料建立一种具有先验概率的图模型,来计算语料中词语的情感概率值,再利用信息熵将概率值归一化为情感特征值,最后用分类器来分类

6. 舆情分析应用: 热点敏感话题识别; 主题跟踪;突发事件分析;可视化统计分析;
6 总结
1. 文本倾向性分析,在商业和政府舆情上都有很好的应用前景;
2. 情感信息抽取需要充分考虑预警信息;
3. 进一步探索融合语义信息的情感分析;
4. 面向开源碎片化文本的情感倾向性分析仍具挑战。