六大挑战下,如何利用云原生数据战略打造数据驱动型企业?

在刚刚落幕的2022亚马逊云科技中国峰会上,亚马逊云科技大中华区战略业务发展部总经理顾凡带来《亚马逊云科技 成为探路者,成就探路者》主题演讲,总结了数据驱动型企业面临的六大挑战,并提供了解决思路。

IDC预测,仅在2022年,人类将创建超过97ZB的数据。在数据采集变得越来越容易的当下,收集数据是成功的第一步,但数据量的剧增,并不等于数据带来的价值增加,68%的公司无法从数据中实现可以量化的价值,成为数据驱动型企业,面临六大挑战:
1、大多数企业缺少明确的数据平台战略;
2、高速的数据增长带来了存储、分析与数据创新成本的压力;
3、难以找到发挥数据价值的场景;
4、不清楚应该使用什么新技术或产品来支持业务创新;
5、企业人员技能不足难以支撑创新型数据项目;
6、企业缺乏数据的治理和安全保护的能力。
针对这六大挑战,亚马逊云科技结合众多成功的数据驱动型企业的经验,推出云原生数据战略,简单来说,它有“3个支柱”和“1个基石”。

 第一大支柱:云原生的数据基础设施
第一大支柱:云原生的数据基础设施
2004年, Amazon.com 网站在高峰期出现几小时中断,原因是当时的关系数据库 Oracle 已无法支持业务规模,这让工程师重新思考底层数据存储,并研发了的非关系数据库 Dynamo 。基于此,2007年亚马逊云科技发表了 Dynamo 论文,2012年进而发布 DynamoDB 服务,开启了亚马逊电商全面迁移到云原生数据库的历程。
应用和数据库架构变迁是不分家的,亚马逊电商从单体应用到SOA再到拆分为微服务架构,同时做了数据拆分,基于每个微服务不同的数据类型,数据访问特点各开发团队开始选择最适合自己的云原生数据库或分析服务,从应用到数据库整体架构做到弹性、敏捷。如今,亚马逊云科技已逐步完善了不同类型的云原生数据库,数据分析服务,来满足不同的应用场景,并利用Aurora Babelfish将迁移时间从数年压缩至几周,节约数据库成本。

除了云原生数据库,云原生数据基础设施的另一个技术趋势就是向无服务器化演进。Servereless的数据库/分析服务具有易于自动扩容、成本更加灵活等优势,能进一步减少管理的成本开销。从Aurora Severless V1/V2,再到Redshift/EMR/MSK的Serverless版本,亚马逊云科技的云原生无服务器数据服务,帮助客户实现业务敏捷。


第二大支柱:数据一体化融合
亚马逊云科技智能湖仓架构能够打破数据孤岛,构建数据湖,然后建立跨数据湖,数仓,数据库等不同数据源的一体化分析能力。
智能湖仓架构1.0
能将数据以任何规模存储在S3数据湖,并针对不同的分析场景,采用专门构建的亚马逊云科技分析服务,以达到最极致的性能,最后进行跨不同数据源的统一分析。
数智联动 智能湖仓架构2.0
在智能湖仓在基础上,增加数据分析和人工智能联动能力,为客户解决数智联动的挑战。首先,所有用来做数据预加工的数据分析服务,都有无服务器版本,工程师只需专注于数据处理的代码效率和质量;其次,亚马逊云科技分享的最佳实践能为大数据和算法团队提供统一的数据治理底座,来解决两边在数据的发现和理解各自为战的问题;第三,用好SageMaker Studio的新功能,算法团队在一个统一的界面下,可以访问数据加工和模型开发调试的工具,算法团队能够充分利用大数据团队在数据处理方面已经取得的成果,避免重复劳动。

第三大支柱:数据驱动智能创新
利用机器学习重塑创新引擎怎么做?顾凡总结为以下四点:

一、找到合适业务场景。建议从个性化推荐、供需预测、工业自动化、图像/视频自动分析、智能语音助手等场景开始尝试,可以更好提高工作效率、直接创造业务价值;
二、利用亚马逊云科技的许多开箱即用、训练好的 AI SaaS模型去做场景的快速验证。其覆盖文档处理,机器视觉,聊天机器人,搜索,推荐,语音,呼叫中心等7个横向领域,以及工业,医疗健康,代码开发等3个垂直领域;
三、亚马逊云科技的提供众多工具和最佳实践,助力企业要将机器学习应用到更多场景时。机器学习基础设施方面,亚马逊云科技支持所有主流机器学习框架,也提供了最丰富的加速器实例。机器学习工具方面,SageMaker极大的降低了机器学习开发的门槛,让开发者可以更快速,更容易的完成机器学习开发的每一步工作,而MLOps借助SageMaker 的强大功能与丰富的 SDK 与 API,可以把机器学习开发的流程串联,并与企业内部的工作审核流程相集成,去实现端到端的机器学习自动化。
四、利用机器学习打造创新引擎,需要赋能更多人构建机器学习应用。亚马逊云科技与全球300多所高校展开合作,开展机器学习大学的项目。同时,通过DeepRacer将机器学习的能力交到更多人手中,其次,在工具层面,SageMaker Canvas可以让更多人通过可视化的方式构建机器学习应用,而无需编写代码或有机器学习的经验。

一个基石:数据安全与数据治理
当数据系统变得复杂,难以实现价值时,企业面临数据治理的挑战。顾凡指出,企业不仅难以在海量且繁杂的数据中发现有价值的数据,数据质量低也会导致错误的洞察和决策,同时,还面临既要数据合规又要支持数据创新,二者难以兼得。
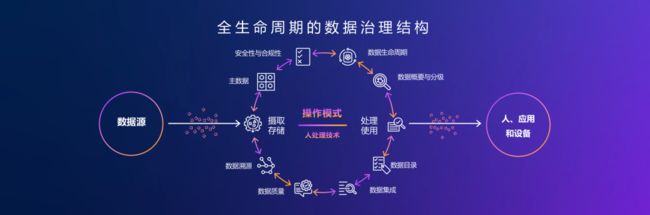
亚马逊云科技提供全生命周期的数据治理结构,企业可以用Lake Formation实现数据的统一授权和安全管控,采用亚马逊云科技丰富的合作伙伴解决方案,来解决数据分级,数据质量,数据血缘等各种治理需求;Data Mesh数据网格能满足企业全球数据安全合规和支持本地创新两者兼得的需求,为云原生数据库战略提供坚实保障。

Canva 可画通过云原生数据战略,用科技赋能世界设计的力量
Canva 可画中国企业事业部负责人于颖,带来亚马逊云科技助力 Canva 可画进行数据管理、构建可靠稳定的云原生数据战略,实现高效的决策与创新的实践分享。

开利消防构建云原生数据基础设施,摆脱了传统架构的桎梏
峰会上,顾凡分享了开利消防的故事,借助Babelfish,他们摆脱了商业数据库的绑定,在5周内就完成SRM系统从SQL Server向Amazon Aurora的业务改造及切换,降低高达70%的数据库成本。
如您想了解更多关于亚马逊云科技云原生数据战略内容,请点击『阅读原文』观看主题演讲精彩回放,也可登陆亚马逊云科技中国峰会官方网站了解更多亚马逊云科技前瞻技术、战略部署及创新案例,与我们一同,自由构建 探索无限!