【邢不行|量化小讲堂系列56-实战篇】量化策略回测表现好,但实盘却很差?可能是底层数据就错啦!
引言:
邢不行的系列帖子“量化小讲堂”,通过实际案例教初学者使用python进行量化投资,了解行业研究方向,希望能对大家有帮助。
【历史文章汇总】请点击此处
【必读文章】
【邢不行|量化小讲堂系列27-Python量化入门】EOS期现套利,一周时间,15%无风险收益
【邢不行|量化小讲堂系列20-Python量化入门】10年400倍策略分享(附视频逐行代码讲解)
个人微信:xbx9585,有问题欢迎交流
量化策略回测表现好,但实盘却很差?可能是底层数据就错啦!

这是邢不行第 54 期量化小讲堂的分享
经常有人跟我说他发现了一个很厉害的策略,年化收益有多高云云;或者看到策略研报、金融论文上面展现某结论非常非常显著等等。
但是对于这些,我一般是持怀疑态度的。其中很重要的一个原因是,它们用来产生结论的原始数据可能是有问题的。
因为我自己知道,整理一份干净、可用的历史数据有多么的难、有多少坑。
还有很多人在量化投资过程中会发现自己的策略明明历史回测表现很好,但实盘却不理想。这也很有可能是因为底层数据有问题导致的。
俗话说:rubbish in,rubbish out。原始数据都是垃圾,策略怎么能不是垃圾呢?
本文就讲讲在整理股票历史数据中经常遇到的坑,来帮大家避免这些问题。

国内最有名的商业金融数据库是万得Wind。
在万得客户端的股票行情序列中,可以导出全部A股每天的行情数据:
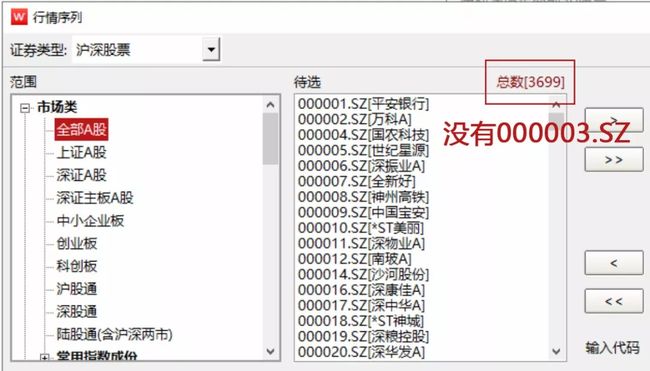
截止目前A股共有3699只股票
很多没有经验的同学下载了这个数据,就兴冲冲的开始研究量化策略,甚至写学术论文了。
但其实这是有问题的。
因为这些股票当中没有包含那些已经退市的股票。比如图中000001、000002之后就是000004了,那请问怎么没有000003?因为它已经退市了。
当你策略的回测是基于这样不完整的股票数据做出的,就会存在误差。因为在今天我们知道这些股票已经退市,但在当时,我们选股时并不知道哪些股票未来会退市。
并且往往退市的股票表现会很差,所以不包含退市股票,相当于提前开“天眼”删除了部分垃圾股,间接的用到了“未来函数”,会让你的策略表现的“更好”。
关于这种偏差, 有个专业术语叫做“幸存者偏差”。
A股目前退市股票有一百多只,比例不高。但在美股、港股中,退市情况就非常普遍,如果没有加入退市股票的数据,那么策略结果会严重失真。
所以我们不管从哪里获取股票数据,都一定要去检查下它是否包含退市的股票。

二战期间,人们发现幸存的飞机中,机翼中弹数量多,而机身中弹的却很少,因此认为应该加固机翼。但其实刚好相反,因为机身中弹的飞机都没能飞回来,所以应该加强的是机身。这也是典型的“幸存者偏差”

A股的上市公司经常会变更名字。更名常见的一个原因是当业绩不达标时,被动在名字前冠上ST,简称ST股。
下图是600053这个股票,从上市以来的更名历史。其中很长一段时间被叫做ST江纸,后来陆续改名为中江地产、九鼎投资。

下面是从万得客户端的行情序列中下载的600053从2003-5-12到30日之间的股票数据。可以看到这段时间股票名称应该为“*ST江纸”,但是万得只是简单的用下载数据时的最新名称“九鼎投资”代替。
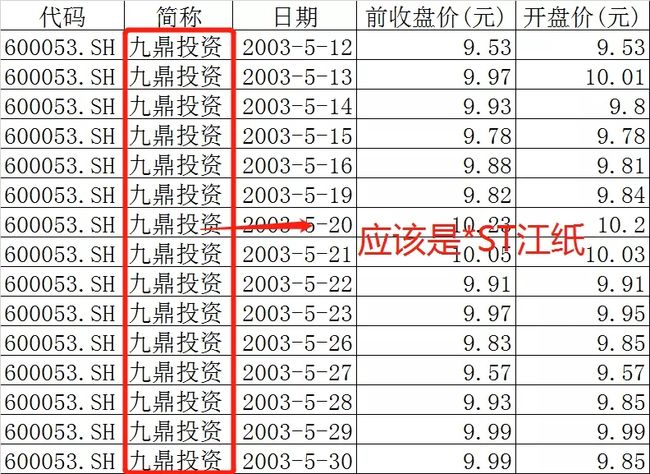
万得江西纸业的数据截图
那么这样的数据就是有问题的。
股票如果名称中带有ST字样,每日涨跌停限制就会由10%降为5%。但是Wind的行情数据中,600053股票名称一直是九鼎投资,并没有标记出哪天是ST。
那用这样的数据统计涨跌停情况,都只会按照10%来算。那么有些时候,明明5%触发了ST涨停,仍然会被当做没涨停来对待。
这就会导致我们的一些交易策略失真。比如选中了某个股票,以为当时可以买入,但其实当时该股票处于ST涨停状态,其实根本无法买入。
我之前就看到过有些策略的选股记录,选择的全是连续涨停的ST股,这样的策略结果看上去“很美丽”,但实际根本无法实现。
所以我们在获得一份股票数据的时候,一定要看下它的历史名称是否正确,不然策略回测结果的真实性就要大打折扣。

上市公司一年要发四次财报,交易所规定了发布的时间段:
1季报:4月1日——4月30日。
2季报(中报):7月1日——8月30日。
3季报:10月1日——10月31日
4季报 (年报):1月1日——4月30日。
比方说2018年第二季度财报。最早的博腾股份在7月31日就发布了,而最晚的格力电器在8月31日才发布。

再比如目前2019年10月,是发布三季报的时候。可以发现还没有出报告的企业是没有办法获得相关财务数据。

万得数据数据界面截图
但是去看历史数据会怎么样呢?在万得的行情序列中下载万科的每股收益数据,会发现在2019-01-02的时候就已经更改了每股收益。
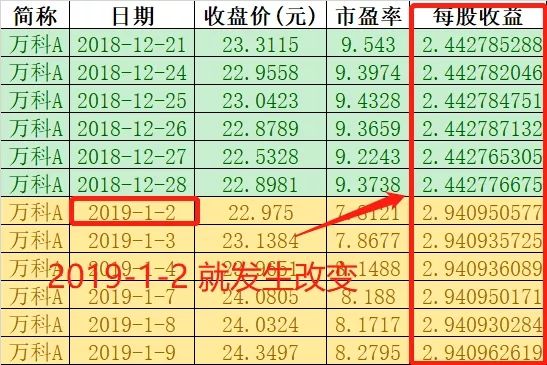
万德的行情序列中下载的万科数据截图
但是万科的年报上可以看到,万科2018年的年报在2019-03-26才发年报。所以万得数据比年报发布的数据足足早了2个月!

万科的2018年年报发布时间截图
那这样的数据就有相当大的问题!
如果我用这个数据来进行回测,相当于我在2019年1月2日,就知道了万科在2019年3月26日才发布的年报数据。我能预测这么久的未来,开发的策略能“不赚钱”吗?
所以我们在使用财报数据的时候一定要注意财报发布的时间。不然策略的年化结果再高也没用。

我们用来回测交易策略的数据,时间不能太短。
回测时间太短会有什么影响呢?
一方面,股票市场通常是周期性变化的。我们的数据最好至少包含一轮完整的牛熊周期,这样才可以评价我们的交易策略在不同周期的表现。
针对A股的话,回测数据一般从2006、2007年开始。从那之后已经有两轮完整牛熊。并且07年股股权分制改革、财务报表改革,从那之后的财务数据都比较统一。

上证指数及其2006年之后的两轮牛熊
tushare这个Python第三方库,是很多人的数据来源。安装方便、免费,是他的优点。
但它的一个缺点是,目前只能获取近3年的日线数据。
下面获取新湖创业股票历史数据的代码,可以看到他只获取了最早到2017-05-02的数据。
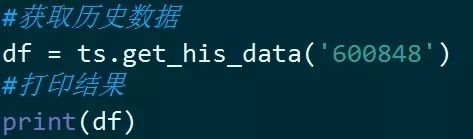
获取数据的代码

代码运行结果
另一方面,股票数据中会有很高的噪声。在回测时间比较短的情况下,还会出现在数据挖掘中经常遇到的一个情况:“过拟合”。

过度拟合示意图
什么是过拟合呢?举个例子来说就是,我们的策略过于复杂,并且在用于寻找最优参数的样本数据中表现很好。但是将优化好的模型应用在非样本数据中表现却很差。
增加样本数量,也就是增加股票历史数据的长度,可以帮助解决过拟合的问题。

在股票市场里,因为分红派息、拆股送股等原因,股价会发生异常变化。
比如十送十的股票,在送完之后,股价会从原来的价格直接变为一半。
为了消除这些异常变化,大家往往会对股票数据进行复权处理。
如果没有经过复权处理会发现有时候股票价格从30块变为15块,一下子就跌了50%。所以未复权数据作为回测策略输入的时候,回测结果和实际情况会有很大的出入。
可以看下图享通光电2015年9月中旬有一个巨大的价格缺口的情况。可以很好的说明复权和未复权的差别。

未复权(上图)和复权(下图)比较
可以再看看万得数据库中享通光电的数据。

享通光电未复权数据截图
可以发现如果没有选择复权选项,那么2015-9-23 到 2015-9-24 收盘价的变化将会非常大。
所以我们在获取一份股票数据的时候,一定要去关注下,它的股票价格是否复权,如果没有复权,这个数据是不能用的。
更详细的有关股票复权的信息可以看邢不行之前的这篇公众号文章:量化投资中,计算技术指标时常见的8个坑
如果对如何计算复权价格感兴趣,可以加邢不行微信讨论:xbx9585。

到目前我们已经看了这么多准备数据的过程中可能会踩的坑。其实避免这些坑的目的都是为了尽可能的还原历史的真实情况。这样我们的回测结果和对模型的评价才更加可靠。
为了帮助《Pyhton股票量化投资》课程的同学解决数据准备中的这些问题,我也提供了我自己清洗整理的股票历史数据,包含了完整、干净的数据。

长按识别上面的二维码,进入量化小讲堂网站,按照GIF的步骤做就可以获取历史数据。

![]()
联系邢不行

推荐阅读
2018量化炒币7大玩法复盘 | 视频、PPT分享
收藏!量化小讲堂前50篇合集(含代码)
量化投资中经常使用Excel,可能会被同事打
警惕!数字货币交易所排名陷阱:到底哪家交易最活跃?(下)
历年排名前10的基金,在第2年表现如何?Python告诉你答案
在量化投资中,原来K线还能这么画(附画K线代码)