MySQL索引原理剖析
MySQL索引原理
- 索引实现
-
- 索引存储
- B+树
- B+ 树层高
- 关于自增id
- 最左匹配原则
- 覆盖索引
- 索引下推
- innodb体系结构
-
- Buffer pool
- change buffer
- 索引失效
- 索引原则
- 总结
- 后言
索引实现
索引存储
innodb 由段、区、页组成。段分为数据段、索引段、回滚段等。
区大小为 1 MB(一个区由 64 个连续页构成)。页的默认值为 16。页为逻辑页,磁盘物理页大小一般为 4K 或者 8K。
为了保证区中的页的连续,存储引擎一般一次从磁盘中申请4~5 个区。

页是 innodb 磁盘管理的最小单位;默认16K,可通过innodb_page_size 参数来修改。B+ 树的一个节点的大小就是该页的值。
B+树
B+树是多路平衡搜索树;多路就是有很多分叉,平衡就是平衡多路树的高度,搜索就是有序(中序遍历有序)。和平衡二叉搜索树一样,通过比较key来排序,而key就是显式创建的索引,比较列的值进行排序。
B+树全称:多路平衡搜索树,是为了减少磁盘访问次数。用来组织磁盘数据,以页为单位,物理磁盘页一般为 4K,innodb 默认页大小为16K;对页的访问是一次磁盘 IO,缓存中会缓存常访问的页。
innodb中的B+树的特征:
(1)多路平衡搜索树。
(2)所有的叶子节点都在同一层。
(3)并且叶子节点构成一个双向链表。
(4)节点的大小是固定的,都为数据页大小(16K)。
(5)非叶子节点只记录索引信息,叶子节点记录数据信息。
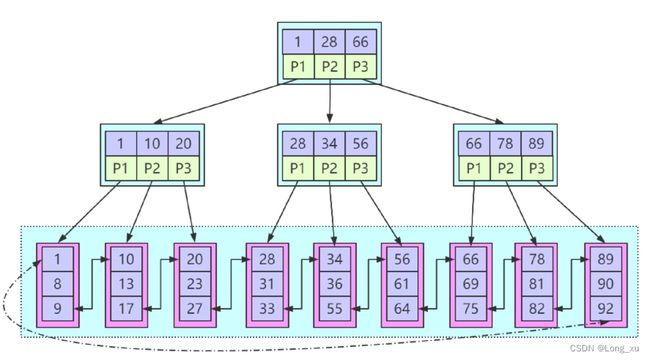
B+ 树层高
B+ 树的一个节点对应一个数据页。B+ 树的层越高,那么要读取到内存的数据页越多,IO 次数越多。innodb 的B+树中一个节点 16KB。
假设: key 为 10byte 且指针大小 6byte,假设一行记录的大小为1KB。
那么一个非叶子节点可存下 16 KB / 16 byte=1024 个 (key+point);每个叶子节点可存储 1024 行数据。
结论:
(1)2层B+树叶子节点1024个,可容纳最大记录数为: 1024 × 16 = 16384 1024 \times 16 =16384 1024×16=16384.
(2)3层B+树叶子节点 1024 × 1024 1024 \times 1024 1024×1024,可容纳最大记录数为: 1024 × 1024 × 16 = 16777216 1024 \times1024 \times 16 = 16777216 1024×1024×16=16777216。
(3)4层B+数叶子节点 1024 × 1024 × 1024 1024 \times 1024 \times1024 1024×1024×1024,可容纳最大记录数为 1024 × 1024 × 1024 × 16 = 17179869184 1024 \times1024 \times1024 \times 16 = 17179869184 1024×1024×1024×16=17179869184。
关于自增id
超过类型最大值会报错。
类型 bigint 范围:( − 2 63 , 2 63 − 1 -2^{63}, 2^{63}-1 −263,263−1) 。
假设采用 bigint,1 秒插入 1 亿条数据,大概需要 5849 年才会用完索引。
最左匹配原则
主要针对组合索引。从左到右依次匹配,遇到模糊匹配(>、<、between、like等)时就停止匹配;如果没有第一个索引也停止匹配。
示例:
DROP TABLE IF EXISTS `left_match_t`;
CREATE TABLE `left_match_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `left_match_t` (`name`, `cid`, `age`)
VALUES
('FLY', 10001, 12),
('fly', 10002, 13),
('cc', 10003, 14),
('ff', 10004, 15)
SHOW INDEX FROM `left_match_t`;
# 作用优化器
EXPLAIN SELECT * FROM `left_match_t` WHERE `name` = 'mark';
# 优化器
EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1 AND `name` = 'mark';
# 不会走索引
EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1;
覆盖索引
覆盖索引是一种数据查询方式,主要针对辅助索引。从辅助索引中就能找到数据,而不需通过聚集索引查找;利用辅助索引树高度一般低于聚集索引树, 可以较少的磁盘 IO。
也就是,如果查询的字段是辅助索引,那么查询过程中就不需要回表查询,直接使用辅助索引B+树就可以查询到数据。
示例:
DROP TABLE IF EXISTS `covering_index_t`;
CREATE TABLE `covering_index_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
`score` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `covering_index_t` (`name`, `cid`, `age`, `score`)
VALUES
('FLY', 10001, 12, 99),
('fly', 10002, 13, 98),
('cc', 10003, 14, 97),
('ff', 10004, 15, 100);
SHOW INDEX FROM `covering_index_t`;
-- 需要回表查询
SELECT * FROM `covering_index_t` WHERE `name` = 'FLY';
-- 查询字段是辅助索引(`name`, `cid`, `id`),不需要回表查询
SELECT `name`, `cid`, `id` FROM `covering_index_t` WHERE `name` = 'FLY';
在使用中,尽量不要使用select * …来获取数据;因为里面有些字段可能没有创建索引,没有创建索引就需要回表查询,这会增加磁盘IO。所以,在select中尽量写所需的字段。
索引下推
索引下推的目的是为了减少回表次数,提升查询效率。在 MySQL 5.6 的版本开始推出。
MySQL 架构分为 server 层和存储引擎层。
没有索引下推机制之前,server 层向存储引擎层请求数据,在server 层根据索引条件判断进行数据过滤。
有索引下推机制之后,将部分索引条件判断下推到存储引擎中过滤数据;最终由存储引擎将数据汇总返回给 server 层。
innodb体系结构
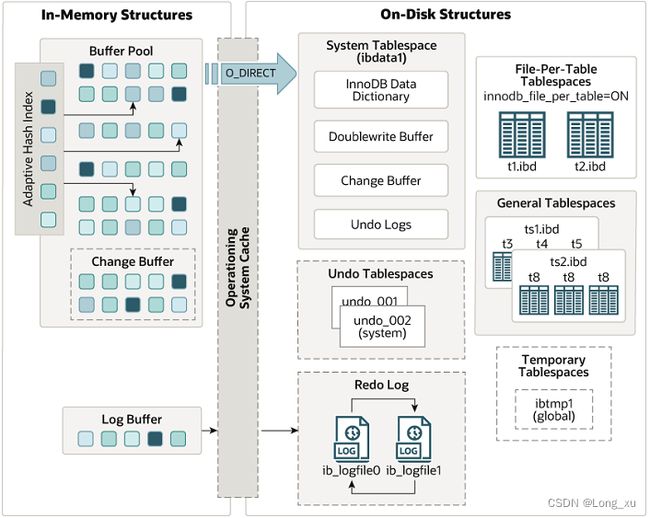
Buffer pool
Buffer pool 缓存表和索引数据;采用 LRU 算法(原理如下图)让 Buffer pool 只缓存比较热的数据。
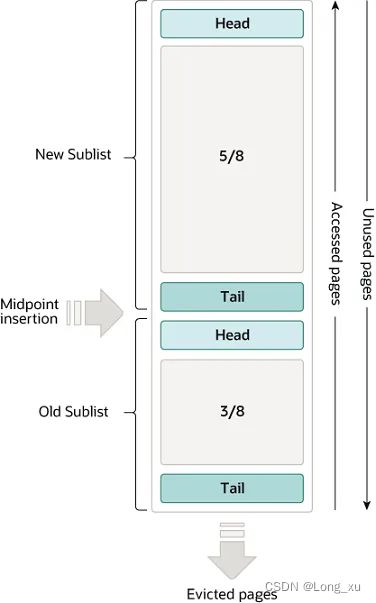
进行数据操作时,首先通过自适应hash索引查询数据是否在buffer pool中;如果数据不在,则通过mmap将磁盘数据映射到buffer pool中;如果数据存在buffer pool中就直接操作。
buffer pool 用于缓存若干数据页,降低磁盘IO次数。
change buffer
Change buffer 缓存非唯一索引的数据变更(DML 操作),Change buffer 中的数据将会异步 merge 到磁盘当中。
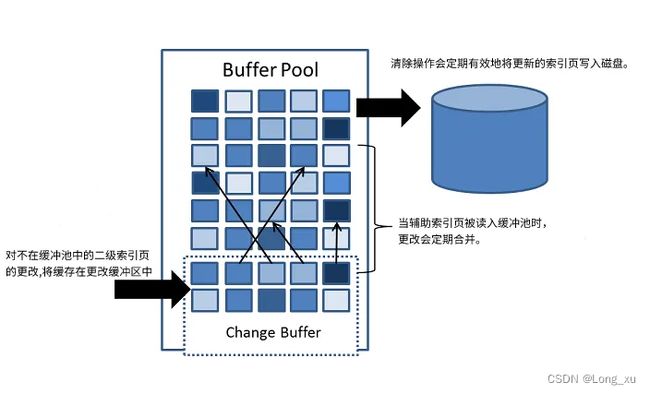
change buffer目的是将DML数据合并到buffer pool。
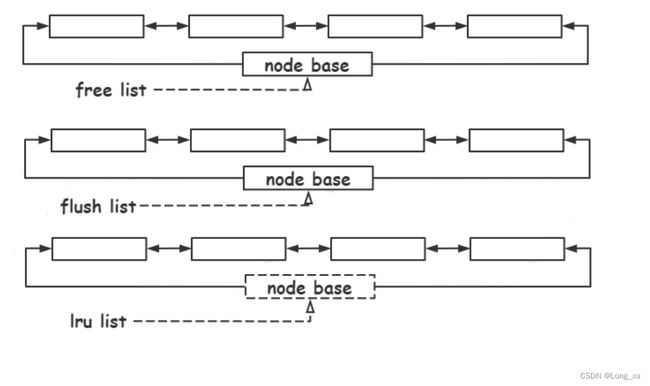
(1)free list 组织 buffer pool 中未使用的缓存页;
(2)flush list 组织buffer pool 中脏页,也就是待刷盘的页;
(3)lru list 组织 bufferpool 中冷热数据,当 buffer pool 没有空闲页,将从 lru list 中最久未使用的数据进行淘汰。
索引失效
(1)select … where A and B 若 A 和 B 中有一个不包含索引,则索引失效。
(2)索引字段参与运算,则索引失效;例如:from_unixtime(idx)= ‘2021-04-30’; 。
(3)索引字段发生隐式转换,则索引失效;例如:将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数。
(4)LIKE 模糊查询,通配符 % 开头,则索引失效;例如:select * from user where name like ‘%Mark’; 。
(5)在索引字段上使用 NOT <> != 索引失效;如果判断 id <> 0则修改为idx > 0 or idx < 0。
(6)组合索引中,没使用第一列索引,索引失效。
示例:
DROP TABLE IF EXISTS `index_failure_t`;
CREATE TABLE `index_failure_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
`score` SMALLINT DEFAULT 0,
`phonenumber` VARCHAR(20),
PRIMARY KEY (`id`),
KEY `name_idx` (`name`),
KEY `phone_idx` (`phonenumber`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `index_failure_t` (`name`, `cid`, `age`, `score`, `phonenumber`)
VALUES
('谢某某', 10001, 12, 99, '13100000000'),
('廖某某', 10002, 13, 98, '13700000000'),
('吴某某', 10003, 14, 97, '17300000000'),
('王某某', 10004, 15, 100, '13900000000');
select * from `index_failure_t`;
explain select * from index_failure_t where name like '%谢';
explain select * from index_failure_t where length(name) = 9;
explain select * from index_failure_t where id = 3-1;
-- MySQL 遇到字符串和数字比较时,会自动将字符串转换为数字;
explain select * from index_failure_t where phonenumber = 13700000000;
-- <=> explain select * from index_failure_t where cast(phonenumber as signed int) = 13700000000;
explain select * from index_failure_t where id = 3 or age = 18;
索引原则
(1)查询频次较高且数据量大的表建立索引。索引选择使用频次较高,过滤效果好的列或者组合。
(2)使用短索引。节点包含的信息多,较少磁盘 IO 操作;比如:smallint,tinyint。
(3)对于很长的动态字符串,考虑使用前缀索引。有时候需要索引很长的字符串,这会让索引变的大且慢,通常情况下可以使用某个列开始的部分字符串,这样大大的节约索引空间,从而提高索引效率,但这会降低索引的区分度,索引的区分度是指不重复的索引值和数据表记录总数的比值。索引的区分度越高则查询效率越高,因为区分度更高的索引可以让 MySQL 在查找的时候过滤掉更多的行。对于BLOB , TEXT , VARCHAR 类型的列,必要时使用前缀索引,因为 MySQL 不允许索引这些列的完整长度,使用该方法的诀窍在于要选择足够长的前缀以保证较高的区分度。
select count(distinct left(name,3))/count(*) as sel3,
count(distinct left(name,4))/count(*) as sel4,
count(distinct left(name,5))/count(*) as sel5,
count(distinct left(name,6))/count(*) as sel6,
from user;
alter table user add key(name(4));
-- 注意:前缀索引不能做 order by 和 group by
注意:前缀索引不能做 order by 和 group by。
(4)对于组合索引,考虑最左侧匹配原则和覆盖索引。
(5)尽量选择区分度高的列作为索引;该列的值相同的越少越好。
(6)尽量扩展索引,在现有索引的基础上,添加复合索引。最多6个索引。
(7)不要使用 select * …。 尽量只列出需要的列字段;方便使用覆盖索
引。
(8)索引列,列尽量设置为非空。
(9)可选:开启自适应 hash 索引或者调整 change buffer。
select @@innodb_adaptive_hash_index;
set global innodb_adaptive_hash_index=1; -- 默认是开启的
select @@innodb_change_buffer_max_size;
-- 默认值为25 表示最多使用1/4的缓冲池内存空间 最大值为50
set global innodb_change_buffer_max_size=30;
总结
- 一定要确定一个主键索引的原因是 主键索引对应的是聚集索引B+树,所有的数据要存储在主键对应的B+树中。
- innodb中的B+树 非叶子节点只存储索引信息,叶子节点存储具体数据信息;叶子节点之间互相连接,方便范围查询。每个索引对应一个B+树。
- MySQL的索引实现使用B+树而不是使用其他树的原因是 降低磁盘IO以及方便范围查询。
- 覆盖索引是一种数据查询方式,主要针对辅助索引;直接通过辅助索引B+树就能获取查询的值,而无需通过回表查询。
- 根据覆盖索引的原理,在select中尽量写所需要的字段,不要写select * … 。
- 没有索引下推机制时,server层向存储引擎层请求数据,在server层根据索引条件判断进行数据过滤。有了索引下推机制,将索引条件下推到存储引擎中过滤数据,最终由存储引擎进行数据汇总返回给server层。
- B+树的页是通过mmap映射到磁盘的数据块,以此来组织数据。
- MySQL通过自适应hash索引快速判断某个页是否在缓存中(buffer pool)。
- MySQL中的explain用于制作执行计划,作用在优化器阶段。
10.工作中不要使用age字段,而是使用生日(年月日)。
后言
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对c/c++linux系统提升感兴趣的读者,可以点击链接,详细查看详细的服务:C/C++服务器课程