When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanis
文章目录
- Abstract
- Introduction
- Related Work
-
- Shift Block
- Architecture Variants
- Experiment
- Ablation Study
-
- MLP中的展开比 τ \tau τ
- 移位通道的百分比 Percentage of shifted channels
- 移位的像素数 Shifted pixels
- 训练方案 ViT-style training scheme
- conclusion
Abstract
论文地址:AAAI2022-https://arxiv.org/abs/2201.10801
代码地址:https://github.com/microsoft/SPACH
注意力机制并不是ViT必不可少的部分。提出将注意力机制简化为zero FLOP and zero parameter,具体来说是重新讨论了移位操作shift operation,它不包含任何参数或者算术计算,唯一的操作是再相邻特征之间交换一小部分通道。基于这种操作提出一种新的backbone, shiftViT。
Introduction
ViT为什么起作用?
一些作品认为是注意力机制促进了VIT强大的表达能力,因为它提供了一种灵活而强大的空间关系建模方法。具体而言,注意机制利用自注意矩阵来聚合任意位置的特征。与CNN中的卷积运算相比,它有两个显著的优点。
-
首先,这种机制为同时捕获short-和long-ranged依赖性提供了可能,并消除了卷积的局部限制。
-
其次,两个空间位置之间的交互 动态地取决于它们自身的特征,而不是固定的卷积核。
一些研究觉得即使没有这些特性,ViT变体仍能很好地工作。
-
对于第一种情况,fully-global dependencies是可以避免的。比如SwinTransformer, Local ViT都提出一种局部注意机制,试图用一个小的local region来限制attention范围,实验表明,性能并没有因局部约束而下降。
-
此外,另一个研究方向是研究动态聚合的必要性。MLP-Mixer提出用线性投影层代替注意层,其中线性权重不是动态生成的。在这种情况下,它仍然可以在ImageNet数据集上达到领先的性能
既然全局和动态属性对ViT框架可能都不是至关重要的,那么ViT成功的根本原因是什么?为了解决这个问题,作者进一步将注意力层简化为一个非常简单的情况:没有全局感受野,没有动态性,甚至没有参数和额外计算量。本文想知道在这种极端情况下,ViT是否能保持良好的性能。
本文贡献:
- 提出了一种类似ViT的backbone, 其中原始注意层被一种极其简单的shift操作代替,该模型可以获得比Swin更好的性能。
- 分析了ViTs成功的原因。这暗示注意机制可能不是ViT发挥作用的关键因素,在今后的ViTs研究中,应认真对待其它组件。
Related Work
Swin Transformer的架构图:

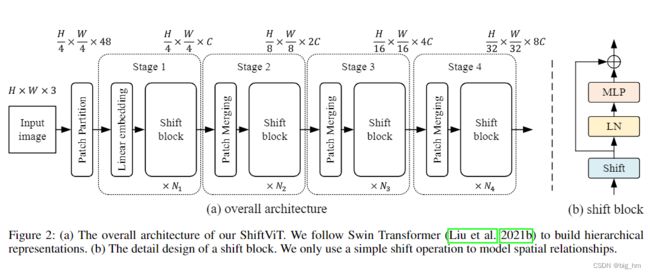
给定一个 H ∗ W ∗ 3 H*W*3 H∗W∗3的输入图像,也将图像分割为不重叠的patch,每个patch的大小为4x4像素,经过patch partition输出 H 4 \frac H 4 4Hx W 4 \frac W 4 4Wx48的token.
接下来的模块可以分为4个stage,每个stage包含两部分:embedding生成和堆叠的 shift blocks。
对于第一个stage的embedding生成,使用线性投影层将每个token映射到通道数为C的embedding中,对于其余的stage,通过2x2的卷积合并相邻的patch,将token大小调整为原来的一半,通道大小为输入的两倍,C to 2C。
ShiftViT的patch merging代码
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Conv2d(dim, 2 * dim, (2, 2), stride=2, bias=False)
self.norm = norm_layer(dim)
def forward(self, x):
x = self.norm(x)
x = self.reduction(x)
return x
堆叠的shift blocks由一些重复的基本单元构成,每个shift block的详细设计如图2(b)所示。它由移位操作、Layer Normalization和MLP组成。此设计几乎与标准transformer块相同。唯一的区别是,本文使用的是移位操作,而不是注意层。
对于每个stage,shift block的数量可以是不同的,分别表示为N1、N2、N3、N4。在实现过程中,作者仔细选择 N i N_i Ni的值,以便整体模型与baseline Swin Transformer有着相似数量的参数。
Shift Block

给定一个输入张量,一小部分通道将沿4个空间方向移动,即左、右、上和下,而其余通道保持不变。移位后,只需删除超出范围的像素,并对空像素进行零填充。在这项工作中,移位步长设置为1像素。
形式上,我们假设输入特征 z z z的shape为H×W×C,其中C是通道数,H和W分别是空间高度和宽度。输出特征 z ^ \hat z z^与输入的shape相同。它可以写为:

γ \gamma γ是一个比率因子,用于控制通道移动的百分比,在大多数实验中 γ \gamma γ被设置为 1 12 \frac 1{12} 121
值得注意的是,移位操作不包含任何参数或算术计算。唯一的实现是内存复制。因此,shift操作效率高,易于实施。伪代码在下图算法1中给出。与自我注意机制相比,移位操作干净、整洁,对TensorRT等深度学习推理库更友好。shift block的其余部分与ViT的标准构建块相同。

def shift_feat(x, n_div):
B, C, H, W = x.shape
g = C // n_div
out = torch.zeros_like(x)
out[:, g * 0:g * 1, :, :-1] = x[:, g * 0:g * 1, :, 1:] # shift left
out[:, g * 1:g * 2, :, 1:] = x[:, g * 1:g * 2, :, :-1] # shift right
out[:, g * 2:g * 3, :-1, :] = x[:, g * 2:g * 3, 1:, :] # shift up
out[:, g * 3:g * 4, 1:, :] = x[:, g * 3:g * 4, :-1, :] # shift down
out[:, g * 4:, :, :] = x[:, g * 4:, :, :] # no shift
return out
MLP网络有两个线性层。第一层将输入特征的通道增加到更高的维度,例如从 C C C增加到 τ C \tau C τC。然后第二层线性层将高维特征投影到原始通道大小C。在这两层之间,本文采用GELU作为非线性激活函数。
Architecture Variants
为了和Swin公平比较,构建了几个具有不同参数数量和计算复杂度的模型。其中,Shift-T(iny) , Shift-S(mall), Shift-B(ase)分别对应Swin-T, Swin-S and Swin-B. 具体的通道数C和blocks 数 N i N_i Ni如下:
- shift-T: C = 96, { N i N_i Ni} = {6, 8, 18, 6}, γ \gamma γ = 1/12
- shift-S: C = 96, { N i N_i Ni} = {10, 18, 36, 10}, γ \gamma γ = 1/12
- shift-B: C = 96, { N i N_i Ni} = {10, 18, 36, 10}, γ \gamma γ = 1/16
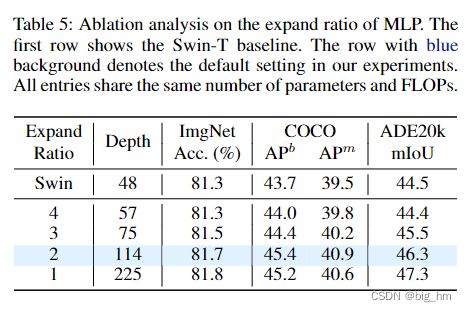
除了模型大小之外,我们还可以更仔细地查看模型深度。在我们提出的模型中,几乎所有参数都集中在MLP部分。因此,我们可以控制MLP的扩展比 τ \tau τ,以获得更深的网络深度。如果未指定,则膨胀比 τ \tau τ设置为2。我们进行了消融实验,以表明更深的模型可以获得更好的性能。
Experiment
作者在三个主流视觉识别基准上进行了实验:ImageNet-1k数据集上的图像分类、COCO数据集上的目标检测和ADE20k数据集上的语义分割。
其中, 后缀light为ShiftViT的轻量级版本,在这个版本中,只使用shift操作替换注意层,并保持其余部分不变。
对于小型模型,Shift-T比Swin-T的表现要好得多。对于大型模型,它似乎已经饱和。但性能仍基本与Swin一致。


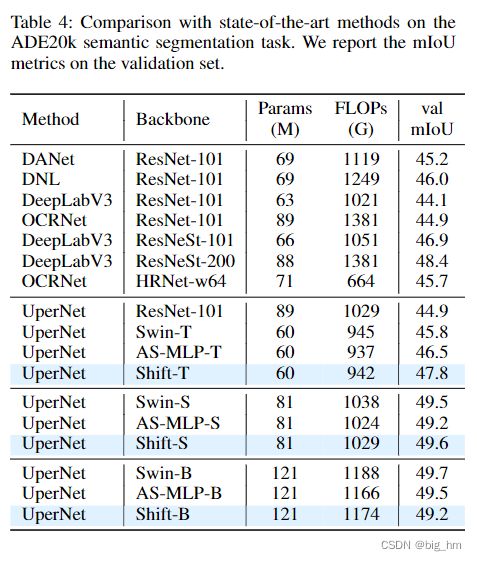
除了分类任务外,在目标检测任务和语义分割任务中也可以观察到类似的性能趋势。值得注意的是,一些基于ViT和基于MLP的方法无法轻松扩展到如此密集的预测任务,因为高分辨率输入会产生难以承受的计算负担。由于移位操作的高效率,此方法不会遇到这种障碍。如表3和表4所示,我们的ShiftViT主干网的优势显而易见。

Ablation Study
MLP中的展开比 τ \tau τ
由于在模型深度和构建块的复杂性之间存在权衡,为了进一步研究这种权衡,本文提出了一些具有不同深度的ShiftViT模型。对于ShiftViT,大多数参数存在于MLP部分。可以改变MLP中 的展开比 τ \tau τ 来控制模型深度。从表5中可以观察到一种趋势,即模型越深,性能越好。当ShiftViT深度增加到225时,它在分类、检测和分割方面的绝对增益分别比57层对应物高0.5%、1.2%和2.9%。这一趋势支持了作者的猜测,即强大而沉重的模块,如注意力,可能不是backbone的最佳选择。
移位通道的百分比 Percentage of shifted channels
从Figure 3可以看出,比例太少时,性能会不如 swin-T。当设置为 1/3 时,性能是最好的。在合理的范围内(从25%到50%),所有设置都比Swin-T具有更好的精度。

移位的像素数 Shifted pixels
本文在移位操作中是一小部分通道沿四个方向,移位一个像素。为了进行全面的探索,作者尝试了不同的移位像素。
当移位像素为零时,即不发生移位,ImageNet数据集的前1位精度仅为72.9%,显著低于81.7%。这并不奇怪,因为不移动意味着不同空间位置之间没有交互作用。
此外,如果在移位操作中移位两个像素,该模型在ImageNet上达到80.2%的top-1精度,这也略低于默认设置。
训练方案 ViT-style training scheme
在CNN中曾对移位操作进行了深入研究。Shift-ResNet-50 在ImageNet上的准确率仅为75.6% ,远低于作者的81.7%。
作者从 优化器、激活函数、规范化层和训练层面分析了 Transformer 性能取得突破的原因 。 从Table 6中,可以观察到这些因素会显著影响准确性,尤其是epoch数。
这些结果表明,ShiftViT的良好表现部分是由训练方案带来的。同样,ViT的成功也可能与其特殊训练计划有关。

conclusion
这项工作表明,注意力机制可能不是ViT成功的关键因素。甚至可以用一个非常简单的移位操作来代替注意力层。由于移位操作已经是最简单的空间建模模块,所以良好的性能必须来自ViT的其余组件,例如FFN和训练方案。