pytorch分布式训练踩坑记录
pytorch分布式训练踩坑记录
近期工作涉及到Backbone,所以会涉及到ImageNet1K(120w+张图像)的预训练
先说说手上有啥,一台PC,配置如下
- 2 张 2080ti
- 500G SSD 2T 硬盘
- 64 内存
- cpu i7 8核
任务是图像分类,虽然简单但是大型数据库的训练极其耗时。 无奈实验室设备就那么多(留下没多张V100的泪水)硬着头皮也得上
git 上的Pipeline 其实也不少,这里我推荐俩
https://github.com/JaminFong/dali-pytorch
https://github.com/AberHu/ImageNet-training
我使用的是第一个,训练方案为
.rec数据库 + Nvidia.dali 库数据增强 + DDP(DistrIbutedDataParallel)
神经网络训练的效率可以看为两个大的部分,一个是CPU的I/O读取数据,另一个是GPU的算力,只有相互配合极致才能极大提高训练效率。
第一个 MXnet(.rec文件) 最早用于caffe,在我的理解是把数据集做成一个数据库,通过对每一张图片建立索引加快CPU i/O 寻址的速度。第二个Dali库能将数据增强拿在GPU上做,可以进一步提高效率。在不知道DDP时,我使用的是简单的DataParallel,虽然代码简单,但是极其容易出现GPU间的负载不均衡的情况,训练imageNet还是算了吧(你有很多卡当我没说…)
此外,推荐一个专门讲DDP的原理的教程三部曲,真的深入浅出,强烈推荐!
[原创][深度][PyTorch] DDP系列第一篇:入门教程
[原创][深度][PyTorch] DDP系列第二篇:实现原理与源代码解析
[原创][深度][PyTorch] DDP系列第三篇:实战与技巧
问题1:KeyError:‘RANK’
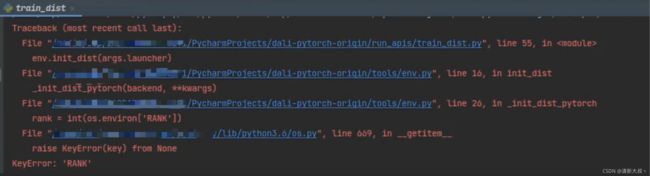
这个问题是在我搞完这个pipline,配置一堆变量,转了数据库格式,直接在Pycharm上点run trian_list.py(个人习惯)出现,baidu搜索这个错误其实并没有看到相关的信息,就告诉你这个是一个环境变量需要人为设置,还有后面world_size参数(其实这里并不需要人为设置),在学习后相关知识后发现,我这样的操作实际上是少了多线程中的launcher(很多参数如local_rank都是它给你自动定义的),在pipline中train_dist.sh如下
python -m torch.distributed.launch --nproc_per_node=$1 run_apis/train_dist.py \
--launcher pytorch \
--report_freq 400 \
--data_path $2 \
--port 23333 \
--config $3
其中 nproc_per_node 实际上就是在问你的GPU数量是多少 我这里就是2
-m 的含义就是实际上就是将python模块作为脚本运行
在这里 就是先运行launch模块 告诉launch我有两个GPU 并将我的train.py传给它
让launch帮我完成相关环境变量的配置,如RANK,world_size等
所以出现这个问题的原因就是我忘记使用launch了,但是新的问题的如何将上面的这个脚本在pycharm上运行调试呢?
找到 Edit Configurations
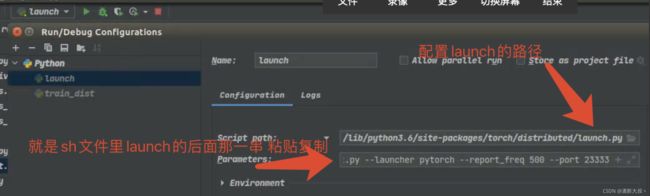
这样,点击右上角绿色三角或者debug就好了
问题2:依然负载不均衡
在网络训练初期一切正常,各项都比较正常,比如GPU利用率和CPU的占用率,
bs为128的情况下,500step大概是1分10秒,一个ep大概9000step,200个ep大概是2.75天
但是差不多过了2000step后,异常出现
第一张GPU满负荷,第二张基本保持在0-10%左右
bs为128,500step大概是5分钟,也就是训练个模型要2星期得一个结果,无法接受
top命令查看CPU发现,实际上只有716进程也就是负责第一张GPU的CPU在不断的i/o
当时看到Xorg进程在占用CPU,还以为是它是在和717进程也就是负责第二张GPU的CPU抢资源
所以当时尝试过nice值改优先度和kill掉Xorg命令行模式运行,发现都不work
不过我注意到Cpu的使用率,我一个8核的CPU,为啥还是那么低呢,直到我看到上图的一个参数 47.4wa,也就是上图的第三行。

这个值越高也就是说明,gpu一直在等待cpu I/O
到这里,我试着将数据拷到 / 目录下(SSD硬盘),之前是没弄是因为装了双系统,不太够
终于,忙活了2天的我解决了这个问题,可以看到CPU利用率相较于之前有很大提升,而且也不会出现负载不均衡的问题。当时一直没太关注SSD,以为转成数据库就可以了。
问题3:CUDA Error: an illegal memory access was encountered
bs为128的情况下两个线程为占45左右,加上其他一些程序实际上也就是out of memory 的类型
稍微调低一点bs就可以了