文献阅读(75)ICML Workshop2020-Temporal Graph Networks for Deep Learning on Dynamic Graphs
本文是对《Temporal Graph Networks for Deep Learning on Dynamic Graphs》一文的总结,如有侵权即刻删除。
朋友们,我们在github创建了一个图学习笔记库,总结了相关文章的论文、代码和我个人的中文笔记,能够帮助大家更加便捷地找到对应论文,欢迎star~
Chinese-Reading-Notes-of-Graph-Learning
更多相关文章,请移步:文献阅读总结:网络表示学习/图学习
文章目录
- Title
- 总结
-
- 1 问题定义
- 2 时序图网络
Title
《Temporal Graph Networks for Deep Learning on Dynamic Graphs》
——ICML Workshop 2020
Author: Emanuele Rossi
总结
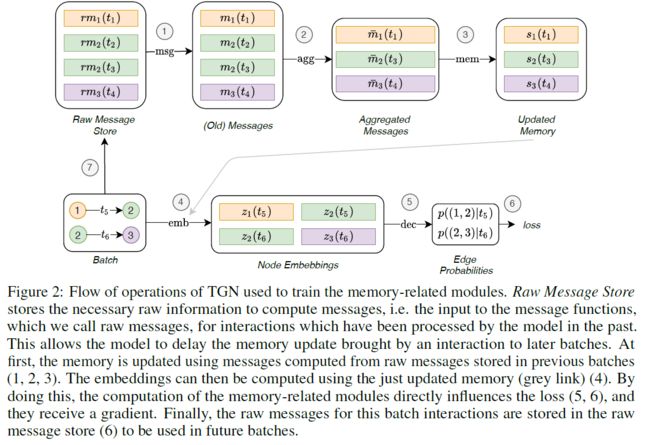
文章提出了在时序图上的通用图神经网络框架TGNs,通过将节点的历史交互信息存储为历史消息进行更新,避免了每次节点嵌入更新需要调用大量数据和反向传播的计算量。算法的框架如下所示:

1 问题定义
传统静态图G=(V,E)上的深度学习,往往将节点之间的边视为消息传递的过程,通过信息的聚合来实现节点嵌入的更新,即:

而对有时间变化的动态图而言,又可分为离散式动态图(也被成为静态快照,按照等时间间隔截取图的邻接矩阵,每个快照对应一个静态图,多个快照之间包含着时间先后的信息)和连续式动态图(又被称为时序图,按照序列形式记录节点的交互先后)。本文研究的是在时序图上的深度学习,因为时序图放弃了邻接矩阵的数据存储形式,而改为了对节点交互的按时间先后记录,那么传统的基于邻接矩阵的图神经网络就不再适用了。
在此,文章还将节点交互(即事件event)分为两类,一类是node-wise event,即当一个节点发生交互时,如果图中还没有出现过该节点,就会为其生成一个初始化的表征,一类是interaction event,即当节点出现在图中后,之后的交互都按照这种事件看待。
2 时序图网络
文章在此提出了memory的概念,在此可以简单理解为历史记录或内存,这个历史记录存储了截止到当前时刻,模型所见过的每个节点,单个节点的记录会在其发生新的交互后完成更新,从而更加简单地表示了时序图的演变轨迹。
当节点发生交互时,应当对节点的记录或者内存进行更新,视为一种消息传递的方式,两个交互的节点信息以及交互本身的信息(如交互时间)都应当被更新到两个节点的内存中,即:
![]()
如果是一个新出现的节点,那么可以根据其特征向量来初始化这种消息传递,即:
![]()
在此,t-表达的是仅次于当前时刻的前一时刻,即不考虑当前交互时的节点内存情况,而msg是可以学习的消息传递函数,如MLP。在此,文章选择了最简单的消息集成函数,即向量拼接。
文章指出,对时序图按照批次(batch)进行计算时,可能会出现同一批次中,节点发生多次交互的情况,这种情况下,节点就会出现多次消息传递。在此,文章首先对同一个节点的多次消息传递进行聚合,然后再作为一个整体更新到节点的内存上去,即:
![]()
聚合函数的选择性较多,在此文章选择了最近一次消息或多条消息的平均值作为最终的更新消息。
需要传递的消息得到后,就要更新到节点内存中,即:

那么节点i在t时刻的表征z,就由交互的两个节点内存和其特征共同生成:

这个生成方式也有多种,例如向量拼接、向量映射、时序多头自注意力、时序加和等。其中,向量映射指的是,给出一定的时间差,通过该时间差值来预测节点未来的表征向量,再与实际生成的对比来判断预测效果,即:
![]()
时序多头自注意力,是对节点的多个邻居表征向量和特征向量进行注意力加权的信息聚合,即:
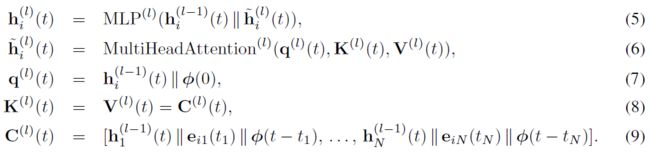
时序加和,则是考虑到了交互时间先后的信息,对整个信息做简单的变换和映射:
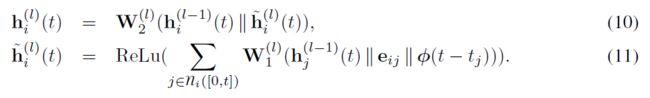
文章在此没有介绍损失函数,但下游任务是链路预测,而链路预测的损失函数,可以默认为经典的正负样本损失,即拉近正样本对距离,拉远随机采样的负样本对距离。
此外,文章还指出,由于内存更新模块是不需要梯度的反向传播的,因此很大程度上加快了模型的训练速度。但是有一点需要注意的是,当一个批次送进模型时,需要对内存进行更新,然而如果将当前批次的数据也进行更新,之后再构造损失函数时就相当于提前告知了模型交互的真实情况,有点监守自盗的感觉。因此,文章在每个批次送入后,只对前一批次的信息进行更新,这样避免了对groundtruth的提前泄露,其结构如下所示: