机器学习——K-近邻算法
1.k近邻算法的概述
工作机制:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。通常,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果;在回归任务中可使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
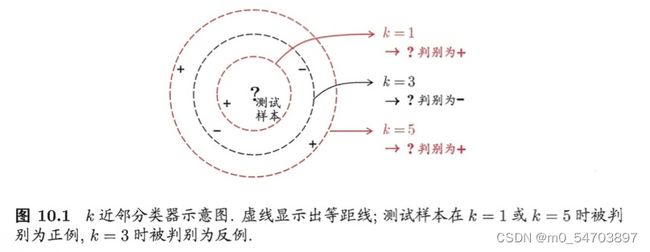
1.1k近邻算法的优缺点
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
1.2k-近邻算法一般流程
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现频率;
5.返回前k个点出现频率最高的类别作为当前点的预测分类
1.3距离计算
参考博客[机器学习-概念] 什么是欧式距离、标准化欧式距离、马氏距离、余弦距离_茫茫人海一粒沙的博客-CSDN博客_标准化欧氏距离
已知数据和测试数据的距离有多种度量方式,比如曼哈顿距离,欧式距离,余弦距离等。在k-近邻算法中常用的距离计算方式是欧式距离。
欧式距离

1.4k值的选择
2 举个例子
陈延奎图书馆主要收藏社科类中外文图书和现报刊,嘉庚图书馆主要收藏自科类中外文图书、现报刊及综合类过刊过报。现根据几位学生在不同图书馆的借书数量区分该同学是就读于文史类专业还是理工类专业。
| 姓名 | 嘉庚图书馆借书数 | 陈延奎图书馆借书数 | 专业类型 |
| 学生A | 54 | 8 | 理工类 |
| 学生B | 40 | 5 | 理工类 |
| 学生C | 59 | 10 | 理工类 |
| 学生D | 2 | 65 | 文史类 |
| 学生E | 7 | 45 | 文史类 |
| 学生F | 5 | 51 | 文史类 |
| 学生G | 65 | 9 | 未知 |
从表1中可以看出的是,在嘉庚图书馆借书数量多的是理工类学生,在陈延奎图书馆借书数量多的是文史类学生。给出未知专业类型的学生,K-近邻算法可以根据已有的数据和该学生在两个图书馆借书的数量来判断这个学生是文史类的还是理工类的。
如下散点图表示了某学生在嘉庚馆和延奎馆借书的数量,若给出学生G(图中红色点),在嘉庚借书65本,在延奎借书9本,如何确定他是理工类还是文史类学生?

根据欧式距离公式计算两点距离:
| 学生姓名 | 与未知专业类型学生G的距离 |
| 学生C | 6.08 |
| 学生A | 11.05 |
| 学生B | 25.32 |
| 学生E | 68.26 |
| 学生F | 73.24 |
| 学生D | 84.29 |
通过计算,我们得到了样本集中所有已知专业类别的学生和未知专业类别的学生的距离,并按照距离递增排序,可以找到k个距离最近的数据。假定k=3,则三个最靠近的学生分别是学生C、学生A、学生B。k-近邻算法按照距离最近的三个学生所属专业类别,决定未知学生专业类别,而这三个学生都是理工类,因此我们判定未知学生专业类别是理工类。
3.Python实现上诉例子
导入科学计算包Numpy,运算符模块
from numpy import *
import operator
# 训练样本集以及对应的类别
def createDateSet():
group = array([[54, 8], [40, 5], [59, 10], [2, 65], [7, 45], [5, 51]])
labels = ['理工类', '理工类', '理工类', '文史类', '文史类', '文史类']
return group, labels
根据k-近邻算法流程编写代码
def classify(inX, dataSet, labels, k):
# dataSetSize是训练样本集数量
dataSetSize = dataSet.shape[0]
# 根据欧式距离公式计算已知点和未知点的距离
# tile函数,把inX变成能与dataSet相减的二维数组
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
# axis=1是列相加求和,即得到(x1-x2)^2+(y1-y2)^2的值
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# 按照距离递增次序排序,返回下标
sortedDistIndicies = distances.argsort()
# 选择与当前点距离最小的k个点
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
# 确定前k个点所在类别的出现频率
# 按照字典里的关键字的值排序,reverse=True降序排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回前k个点中出现频率最高的标签
return sortedClassCount[0][0]
classify( )函数有4个输入参数:用于分类的输入向量是inX,输入的训练样本集为dataSet,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataSet的行数相同。
测试算法
i = 0
print("训练样本集")
group, labels = createDateSet()
for item in group:
print('学生姓名%c:嘉庚馆借阅图书数量%3d本 陈延奎馆借阅图书数量%3d本 专业类别 %s' % (chr(ord('A') + i), item[0], item[1], labels[i]))
i += 1
print("\n测试数据集")
myTests = array([[65, 9], [13, 53], [60, 20]])
myLabels = []
for i in range(3):
myLabels.append(classify(myTests[i], group, labels, 3))
print('学生姓名%c:嘉庚馆借阅图书数量%3d本 陈延奎馆借阅图书数量%3d本 专业类别 %s' % (
chr(ord('G') + i), myTests[i][0], myTests[i][1], myLabels[i]))输出结果
