机器学习——决策树之连续值处理
一、连续属性离散化
连续属性就是像:0.697、0.774、0.634等的数字。 连续属性取值数目非有限,无法直接进行划分。这里采用二分法对连续属性进行处理。
我的数据集
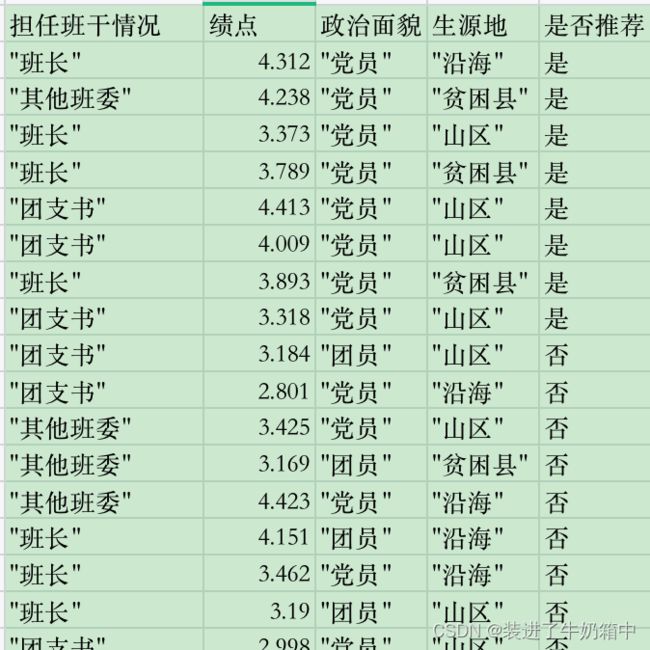
第一步
将连续属性a在样本集D上出现的n个不同的取值从小到大排列,记为![]() 。基于划分点t,可将D分为子集
。基于划分点t,可将D分为子集![]() 和
和![]() ,其中
,其中![]() 包含那些在属性a上取值不大于t的样本,
包含那些在属性a上取值不大于t的样本,![]() 包含那些在属性a上取值大于t的样本。考虑包含n-1个元素的候选划分点集合
包含那些在属性a上取值大于t的样本。考虑包含n-1个元素的候选划分点集合
![]()
即把区间[![]() )的中位点
)的中位点![]() 作为 候选划分点
作为 候选划分点
将连续属性绩点在样本集D上出现的17个不同的取值从小到大排序
2.801 2.998 3.169 3.184 3.190 3.318 3.373 3.425 3.462
3.789 3.893 4.009 4.151 4.238 4.312 4.413 4.423
计算候选划分点集合
2.900 3.083 3.176 3.187 3.254 3.346 3.399 3.444
3.630 3.845 3.951 4.080 4.194 4.275 4.363 4.418
第二步
采用离散属性值方法,计算这些划分点的增益,选取最优的划分点进行样本集合的划分 :
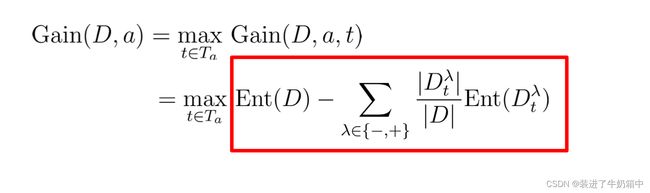
其中Gain(D,a,t)是样本集D基于划分点t二分后的信息增益,于是,就可以选择使Gain(D,a,t)最大化的划分点。
对于上面的数据集,有8个推荐,9个不推荐,信息熵为
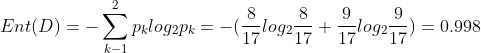
对属性绩点,取划分点![]() ,则:
,则:
![]() ,其中推荐6个,不推荐2个
,其中推荐6个,不推荐2个
![]()
![]() ,其中推荐2个,不推荐7个
,其中推荐2个,不推荐7个
![]()
![]()
计算每个划分点的信息增益,得到最大信息增益为:0.366,对应划分点为3.346
与离散属性不同,若当前结点划分属性为连续属性,该属性还可以作为其后代结点的划分属性
二、代码实现
这里只展现处理连续值相关代码,完整代码请点击百度网盘链接下载
创建数据集
def createDataSet():
dataSet = [
['班长',4.312,'党员','沿海','是']
, ['其他',4.238,'党员','贫困县','是']
, ['班长',3.373,'党员','山区','是']
, ['班长',3.798,'党员','贫困县','是']
, ['团支书',4.413,'党员','沿海','是']
, ['团支书',4.009,'党员','山区','是']
, ['班长',3.893,'党员','贫困县','是']
, ['团支书',3.318,'党员','山区','否']
, ['团支书',3.184,'团员','山区','否']
, ['团支书',2.801,'党员','沿海','否']
, ['其他',3.425,'党员','山区','否']
, ['其他',3.169,'团员','贫困县','否']
, ['其他',4.423,'党员','沿海','否']
, ['班长',4.151,'团员','沿海','否']
, ['班长',3.462,'党员','沿海','否']
, ['班长',3.190,'团员','山区','否']
, ['团支书',2.998,'党员','山区','否']
]
labels = ['担任班委情况','绩点','政治面貌','生源地',]
# 特征对应的所有可能的情况
labels_full = {}
for i in range(len(labels)):
labelList = [example[i] for example in dataSet]
uniqueLabel = set(labelList)
labels_full[labels[i]] = uniqueLabel
return dataSet, labels, labels_full按照给定数值,将数据集划分为不大于和大于两部分
def splitDataSetForSeries(dataSet, axis, value):
# 用来保存不大于划分值的集合
eltDataSet = []
# 用来保存大于划分值的集合
gtDataSet = []
# 进行划分,保留该特征值
for feat in dataSet:
if (feat[axis] <= value):
eltDataSet.append(feat)
else:
gtDataSet.append(feat)
return eltDataSet, gtDataSet计算连续值的信息增益
def calcInfoGainForSeries(dataSet, i, baseEntropy):
#baseEntropy基础信息熵
# 记录最大的信息增益
maxInfoGain = 0.0
# 最好的划分点
bestMid = -1
# 得到数据集中所有的当前特征值列表
featList = [example[i] for example in dataSet]
# 得到分类列表
classList = [example[-1] for example in dataSet]
dictList = dict(zip(featList, classList))
# 将其从小到大排序,按照连续值的大小排列
sortedFeatList = sorted(dictList.items(), key=operator.itemgetter(0))
print(sortedFeatList)
# 计算连续值有多少个
numberForFeatList = len(dataSet)
# 计算划分点,保留三位小数
midFeatList = [round((sortedFeatList[i][0] + sortedFeatList[i+1][0])/2.0, 3)for i in range(numberForFeatList - 1)]
# 计算出各个划分点信息增益
for mid in midFeatList:
# 将连续值划分为不大于当前划分点和大于当前划分点两部分
eltDataSet, gtDataSet = splitDataSetForSeries(dataSet, i, mid)
# 计算两部分的特征值熵和权重的乘积之和
newEntropy = len(eltDataSet)/len(sortedFeatList)*calShannonEnt(eltDataSet) + len(gtDataSet)/len(sortedFeatList)*calShannonEnt(gtDataSet)
# 计算出信息增益
infoGain = baseEntropy - newEntropy
print('当前划分值为:' + str(mid) + ',此时的信息增益为:' + str(infoGain))
if infoGain > maxInfoGain:
bestMid = mid
maxInfoGain = infoGain
return maxInfoGain, bestMid选择最好的数据集划分特征
def chooseBestFeatureToSplit(dataSet, labels):
# 得到数据的特征值总数
numFeatures = len(dataSet[0]) - 1
# 计算出基础信息熵
baseEntropy = calShannonEnt(dataSet)
# 基础信息增益为0.0
bestInfoGain = 0.0
# 最好的特征值
bestFeature = -1
# 标记当前最好的特征值是不是连续值
flagSeries = 0
# 如果是连续值的话,用来记录连续值的划分点
bestSeriesMid = 0.0
# 对每个特征值进行求信息熵
for i in range(numFeatures):
# 得到数据集中所有的当前特征值列表
featList = [example[i] for example in dataSet]
if isinstance(featList[0], str):
infoGain = calcInfoGain(dataSet, featList, i, baseEntropy)
else:
print('当前划分属性为:' + str(labels[i]))
infoGain, bestMid = calcInfoGainForSeries(dataSet, i, baseEntropy)
#print('当前特征值为:' + labels[i] + ',对应的信息增益值为:' + str(infoGain))
# 如果当前的信息增益比原来的大
if infoGain > bestInfoGain:
# 最好的信息增益
bestInfoGain = infoGain
# 新的最好的用来划分的特征值
bestFeature = i
flagSeries = 0
if not isinstance(dataSet[0][bestFeature], str):
flagSeries = 1
bestSeriesMid = bestMid
#print('信息增益最大的特征为:' + labels[bestFeature])
if flagSeries:
return bestFeature, bestSeriesMid
else:
return bestFeature
创建决策树
def createTree(dataSet, labels):
# 拿到所有数据集的分类标签
classList = [example[-1] for example in dataSet]
# 统计第一个标签出现的次数,与总标签个数比较,如果相等则说明当前列表中全部都是一种标签,此时停止划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 计算第一行有多少个数据,如果只有一个的话说明所有的特征属性都遍历完了,剩下的一个就是类别标签
if len(dataSet[0]) == 1:
# 返回剩下标签中出现次数较多的那个
return majorityCnt(classList)
# 选择最好的划分特征,得到该特征的下标
bestFeat = chooseBestFeatureToSplit(dataSet, labels)
# 得到最好特征的名称
bestFeatLabel = ''
# 记录此刻是连续值还是离散值,1连续,2离散
flagSeries = 0
# 如果是连续值,记录连续值的划分点
midSeries = 0.0
# 如果是元组的话,说明此时是连续值
if isinstance(bestFeat, tuple):
# 重新修改分叉点信息
bestFeatLabel = str(labels[bestFeat[0]]) + '小于' + str(bestFeat[1]) + '?'
# 得到当前的划分点
midSeries = bestFeat[1]
# 得到下标值
bestFeat = bestFeat[0]
# 连续值标志
flagSeries = 1
else:
# 得到分叉点信息
bestFeatLabel = labels[bestFeat]
# 离散值标志
flagSeries = 0
# 使用一个字典来存储树结构,分叉处为划分的特征名称
myTree = {bestFeatLabel: {}}
# 得到当前特征标签的所有可能值
featValues = [example[bestFeat] for example in dataSet]
# 连续值处理
if flagSeries:
# 将连续值划分为不大于当前划分点和大于当前划分点两部分
eltDataSet, gtDataSet = splitDataSetForSeries(dataSet, bestFeat, midSeries)
# 得到剩下的特征标签
subLabels = labels[:]
# 递归处理小于划分点的子树
subTree = createTree(eltDataSet, subLabels)
myTree[bestFeatLabel]['小于'] = subTree
# 递归处理大于当前划分点的子树
subTree = createTree(gtDataSet, subLabels)
myTree[bestFeatLabel]['大于'] = subTree
return myTree
# 离散值处理
else:
# 将本次划分的特征值从列表中删除掉
del (labels[bestFeat])
# 唯一化,去掉重复的特征值
uniqueVals = set(featValues)
# 遍历所有的特征值
for value in uniqueVals:
# 得到剩下的特征标签
subLabels = labels[:]
# 递归调用,将数据集中该特征等于当前特征值的所有数据划分到当前节点下,递归调用时需要先将当前的特征去除掉
subTree = createTree(splitDataset(dataSet, bestFeat, value), subLabels)
# 将子树归到分叉处下
myTree[bestFeatLabel][value] = subTree
return myTree运行结果
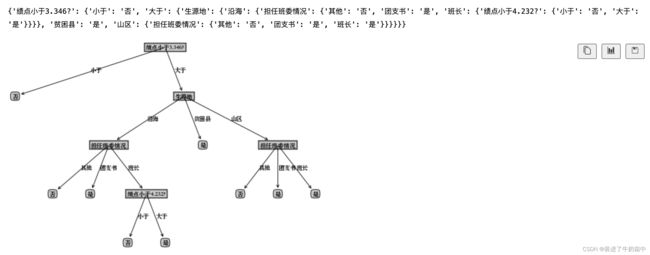
完整代码
链接: https://pan.baidu.com/s/1npNcg7EfQf49SwoGmXriog?pwd=f98b 提取码: f98b