机器学习——决策树学习
机器学习——决策树学习
- 一、什么是决策树
- 二、决策树的学习过程
-
- 特征选择:
- 决策树生成:
- 剪枝:
- 三、决策树的一个具体的实例
-
- 导入数据
-
- python strip() 函数和 split() 函数的详解及实例
- 数据处理
-
- 提取到训练集中的标签
- 给数据的每一列添加上标签,并且转化为字典来存储每一列
- 需要将数据转化为使用数值来代表的数据(字符串)——序列化
- 调用库函数
- 绘制决策树
- 进行预测
决策树:在机器学习中,决策树是一个预测模型,它代表的是对象属性和对象值之间的一种映射关系
决策树的构建步骤:
1特征的选择
2决策树的生成
3决策树的修剪
参考文档:决策树算法内容讲解
一、什么是决策树
所谓决策树,就是一个类似于流程图的树形结构,树内部的每一个节点代表的是对一个特征的测试,树的分支代表该特征的每一个测试结果,而树的每一个叶子节点代表一个类别。树的最高层是就是根节点。下图即为一个决策树的示意描述,内部节点用矩形表示,叶子节点用椭圆表示。
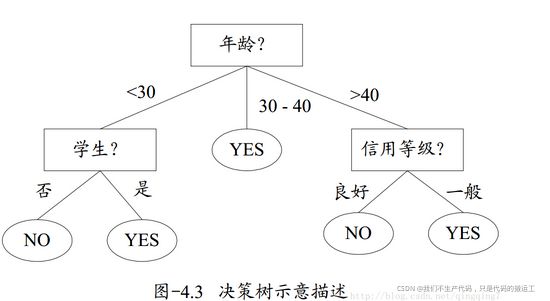
二、决策树的学习过程
一棵决策树的生成过程主要分为以下3个部分:
特征选择:
特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
- 特征的选择
方法一:信息增益
方法二:信息熵
方法三:基尼指数
决策树生成:
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
2. 决策树的生成(树的构建是个递归的过程)
剪枝:
决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
3. 决策树的修剪
方法一:预剪枝,及时停止树增长
方法二:后剪枝
三、决策树的一个具体的实例
所用到的资料:(完整的代码和处理文件)
链接:https://pan.baidu.com/s/1fIAUdCDTpR7TiqLHZtx1yg
提取码:0929
导入数据
python strip() 函数和 split() 函数的详解及实例
一直以来都分不清楚strip和split的功能,实际上strip是删除的意思;而split则是分割的意思。因此也表示了这两个功能是完全不一样的,strip可以删除字符串的某些字符,而split则是根据规定的字符将字符串进行分割。
split()函数
split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
#导入数据
with open('lenses.txt', 'r') as fr: #加载文件
lenses = [inst.strip().split('\t') for inst in fr.readlines()] #处理文件
print("输出读取到的数据:")
print(lenses)
inst=[]
data=[]
with open('lenses.txt', 'r') as fr:
for inst in fr.readlines():#一行一行的读取
print(inst.strip().split('\t'))
data.append(inst.strip().split('\t'))
print('输出读取到的全部数据:')
print(data)

数据处理
在使用回归模型和机器学习模型时,所有考察数据都是数值更容易得到更好的结果。因为都是基于数学函数方法的,所以当数据集中出现类别数据时,此时数据是不理想的,不能用数学方法处理它们。例如处理性别属性时,将男和女两个性别数据用0和1进行代替。
提取到训练集中的标签
data_target=[]
for each in data:
data_target.append(each[-1])#因为在原有数据集中在最后一列
print("输出提取到训练集中的标签:")
print(data_target)
给数据的每一列添加上标签,并且转化为字典来存储每一列
dataLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] # 特征标签
data_list=[]#临时存储全部数据
data_dict={} #保存data数据的字典,用于生成pandas
for each_label in dataLabels:
for each_data in data:
data_list.append(each_data[dataLabels.index(each_label)])
print("输出每一列的数据:")
print(data_list)
data_dict[each_label]=data_list
data_list=[]
print("打印字典信息:")
print(data_dict )
需要将数据转化为使用数值来代表的数据(字符串)——序列化

在使用回归模型和机器学习模型时,所有考察数据都是数值更容易得到更好的结果。因为都是基于数学函数方法的,所以当数据集中出现类别数据时,此时数据是不理想的,不能用数学方法处理它们。例如处理性别属性时,将男和女两个性别数据用0和1进行代替。
使用:LabelEncoder()将object类型转化为数值
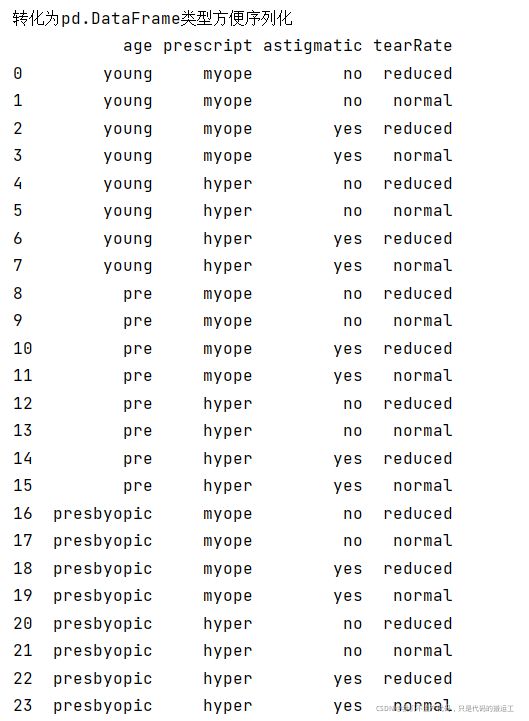
data_pd=pd.DataFrame(data_dict)
print("转化为pd.DataFrame类型方便序列化")
print(data_pd)
le=LabelEncoder()
for col in data_pd.columns:
data_pd[col]=le.fit_transform(data_pd[col])
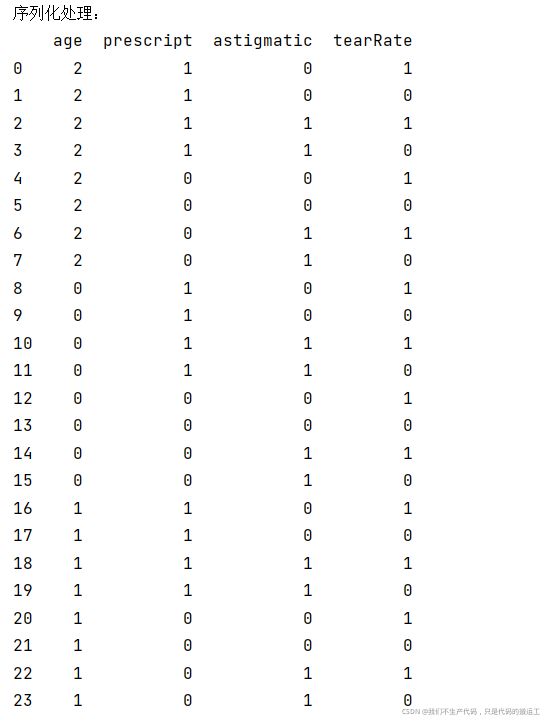
print("序列化处理:")
print(data_pd)
#数据处理阶段
lenses_target = [] #提取每组数据的类别,保存在列表里
for each in lenses:
lenses_target.append(each[-1]) #从最后一列提取标签
print("提取每组数据的类别标签,保存在列表里:")
print(lenses_target)
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签
lenses_list = [] #保存lenses数据的临时列表
lenses_dict = {} #保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels: #提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
#print(lenses_dict)
lenses_list = []
print("打印字典信息:")
print(lenses_dict) #打印字典信息
lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame
print("打印pandas.DataFrame:")
print(lenses_pd) #打印pandas.DataFrame
print("数据序列化:")
le = LabelEncoder() #创建LabelEncoder()对象,用于序列化
for col in lenses_pd.columns: #序列化
lenses_pd[col] = le.fit_transform(lenses_pd[col])
print("打印编码信息:")
print(lenses_pd)
调用库函数
#调用库函数
clf = tree.DecisionTreeClassifier(max_depth = 4) #最多一共四层 #创建DecisionTreeClassifier()类
clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
绘制决策树
# 绘制决策树
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=lenses_pd.keys(),
class_names=clf.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_jpg('decision_tree预测决策树.jpg')
进行预测
#进行预测
print("预测:[[presbyopic,myope,yes,normal],[presbyopic,hyper,yes,normal]]")
print(clf.predict([[1, 1, 1, 0], [1, 0, 1, 0]]))