机器学习——03决策树
之前整理的决策树的知识
机器学习实战(三)——决策树
决策树的比较以及剪枝
机器学习-03决策树
上节介绍的k-近邻算法可以完成很多分类任务,但是其最大的缺点是无法给出数据的内在含义,决策树的优势在于数据形式非常容易理解。
目录
1.决策树模型
1.1 ID3算法
1.2 C4.5算法
1.3 CART算法
1.4 决策树剪枝
1.4.1 预剪枝
1.4.2 后剪枝
1.5 决策树的优缺点
2.决策树代码实现
2.1决策树-例子
2.2 决策树-CART算法
2.3 决策树-线性二分类
2.4 决策树-非线性二分类
1.决策树模型
适合分析离散数据,如果是连续数据则要先转换成离散数据在做分析。
根节点的不同则构建的决策树也不相同,根节点到底要选哪个,根据下面三个算法来计算。
熵——香农(信息熵):一条信息的信息量大小和它的不确定性有直接联系,一件事情越是确定的,它的信息熵越小,越不确定,则信息熵越大。
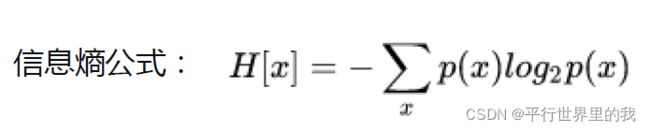
eg:
假如有一个普通骰子A,仍出1-6的概率都是1/6
有一个骰子B,扔出6的概率是50%,扔出1-5的概率都是10% 有一个骰子C,扔出6的概率是100%。
则三个骰子的信息熵分别为: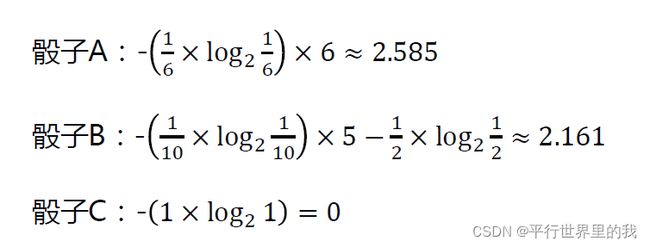
1.1 ID3算法
对于连续型数据,把他转换为离散型,使用的方法:
把所有数据两两一组,选择平均数作为一些备选值,然后依次计算信息增益,哪个值的信息增益结果最大,就选哪个值来进行切分。
选择最大化信息增益来对节点进行划分。
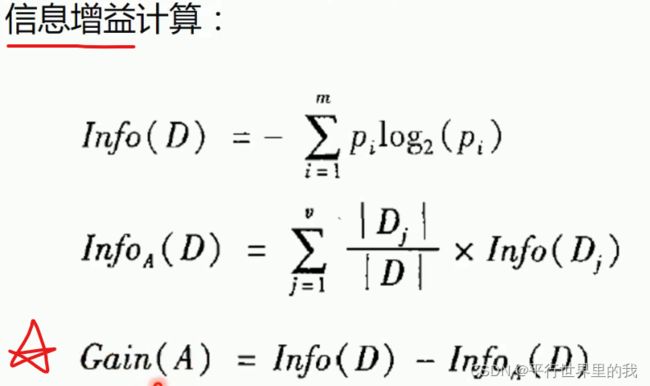
eg:

信息增益最大的就是age,设置为根节点
1.2 C4.5算法
ID3算法倾向于首先选择因子数较多的变量作为根节点。——改进:增益率
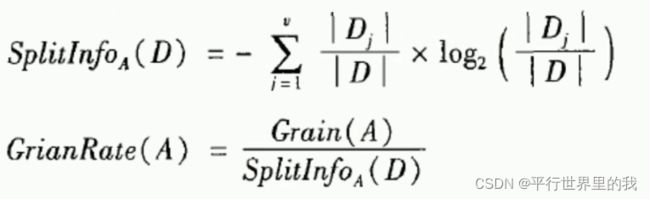
1.3 CART算法
CART决策树的生成是递归的构建二叉决策树的过程。
CART使用基尼(Gini)系数最小化准则来进行特征选择。
选取基尼系数增益值最小的属性作为根节点。
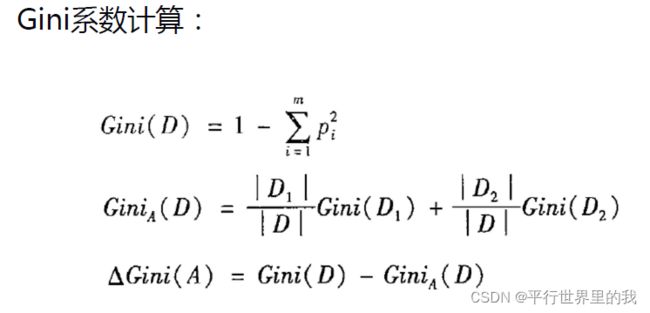
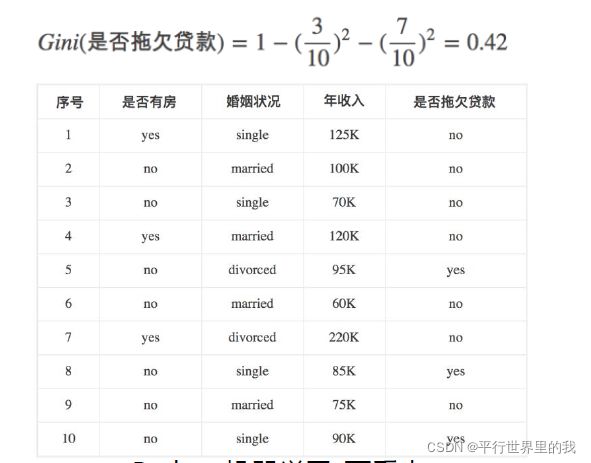
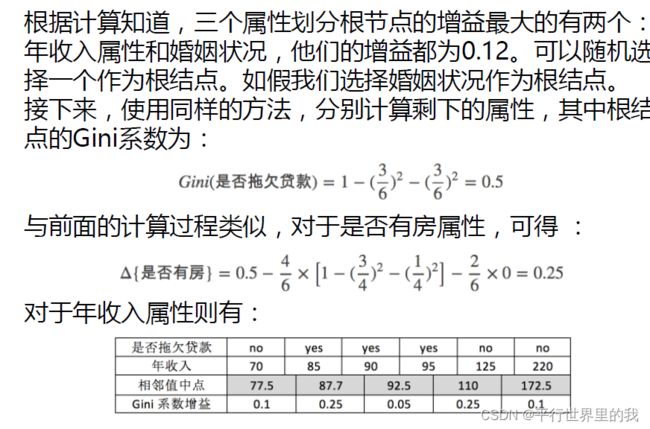
eg:



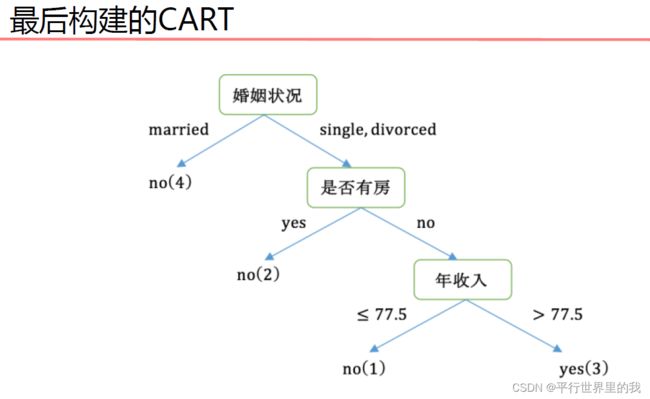
1.4 决策树剪枝
1.4.1 预剪枝
首先将没用的特征属性去掉再构建
1.4.2 后剪枝
当预测为某一类绝大多数都是一类时,可以直接定为这一类,不用再继续分叉。
1.5 决策树的优缺点
| 优点 | 小规模数据集有效 |
| 缺点 | 处理连续数据变量不好; 类别较多时,错误增加的较快; 不能处理大量数据。 |
2.决策树代码实现
2.1决策树-例子
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
# 读入数据
# 里面全是字符,用专门的csv读取
Dtree = open(r'AllElectronics.csv', 'r')
reader = csv.reader(Dtree)
# 获取第一行数据
headers = reader.__next__()
print(headers)
# 定义两个列表
featureList = []
labelList = []
#
for row in reader:
# 把label存入list
labelList.append(row[-1])
rowDict = {}
for i in range(1, len(row)-1):
#建立一个数据字典
rowDict[headers[i]] = row[i]
# 把数据字典存入list
featureList.append(rowDict)
print(featureList)
# 把数据转换成01表示
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
print("x_data: " + str(x_data))
# 打印属性名称
print(vec.get_feature_names())
# 打印标签
print("labelList: " + str(labelList))
# 把标签转换成01表示
lb = preprocessing.LabelBinarizer()
y_data = lb.fit_transform(labelList)
print("y_data: " + str(y_data))
# 创建决策树模型riterion='entropy'计算熵,使用C4.5.
# 默认基尼指数
model = tree.DecisionTreeClassifier(criterion='entropy')
# 输入数据建立模型
model.fit(x_data, y_data)
# 测试
x_test = x_data[0]
print("x_test: " + str(x_test))
predict = model.predict(x_test.reshape(1,-1))
print("predict: " + str(predict))
# 导出决策树
# pip install graphviz
# http://www.graphviz.org/
import graphviz
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = vec.get_feature_names(),
class_names = lb.classes_,
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
graph.render('computer')
print(graph)
print(vec.get_feature_names())
print(lb.classes_)对于画出决策树,参照博客https://blog.csdn.net/sylviatam/article/details/120950926
对于现在sklearn中封装的决策树的算法,一般构建的是二叉树,只有两个分支。
2.2 决策树-CART算法
from sklearn import tree
import numpy as np
# 载入数据
data = np.genfromtxt("cart.csv", delimiter=",")
x_data = data[1:,1:-1]
y_data = data[1:,-1]
# 创建决策树模型
model = tree.DecisionTreeClassifier()
# 输入数据建立模型
model.fit(x_data, y_data)
# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['house_yes','house_no','single','married','divorced','income'],
class_names = ['no','yes'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
graph.render('cart')2.3 决策树-线性二分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import tree
# 载入数据
data = np.genfromtxt("LR-testSet.csv", delimiter=",")
x_data = data[:,:-1]
y_data = data[:,-1]
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
# 创建决策树模型
model = tree.DecisionTreeClassifier()
# 输入数据建立模型
model.fit(x_data, y_data)
# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['x','y'],
class_names = ['label0','label1'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
predictions = model.predict(x_data)
print(classification_report(predictions,y_data))
2.4 决策树-非线性二分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import tree
from sklearn.model_selection import train_test_split
# 载入数据
data = np.genfromtxt("LR-testSet2.txt", delimiter=",")
x_data = data[:, :-1]
y_data = data[:, -1]
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
#分割数据
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data)
# 创建决策树模型
# max_depth,树的深度
# min_samples_split 内部节点再划分所需最小样本数
model = tree.DecisionTreeClassifier(max_depth=7,min_samples_split=4)
# 输入数据建立模型
model.fit(x_train, y_train)
# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['x','y'],
class_names = ['label0','label1'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
predictions = model.predict(x_train)
print(classification_report(predictions,y_train))
predictions = model.predict(x_test)
print(classification_report(predictions,y_test))