Kettle
主要内容:
一.ETL介绍
二.Kettle介绍
三.Java调用Kettle API
一、ETL介绍
1. ETL是什么?
1).ETL分别是“Extract”、“ Transform” 、“Load”三个单词的首字母缩写也即数据抽取、转换、装载的过程,但我们日常往往简称其为数据抽取。
ETL包含了三方面:
Extract(抽取):将数据从各种原始的业务系统中读取出来,这是所有工作的前提。一般抽取过程需要连接到不同的数据源,以便为随后的步骤提供数据。这一部分看上去简单而琐碎,实际上它是 ETL 解决方案的成功实施的一个主要障碍。
Transform(转换):按照预先设计好的规则将抽取得数据进行转换,使本来异构的数据格式能统一起来。任何对数据的处理过程都是转换。这些处理过程通常包括(但不限于)下面一些操作:
移动数据
根据规则验证数据
数据内容和数据结构的修改
将多个数据源的数据集成
根据处理后的数据计算派生值和聚集值
Load(装载):将转换完的数据按计划增量或全部导入到数据仓库中。也就是说将数据加载到目标系统的所有操作。
2).ETL是数据抽取(Extract)、清洗(Cleaning)、转换(Transform)、装载(Load)的过程。是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
3).ETL是BI/DW( Business Intelligence/Data Warehouse , 商务智能/数据仓库)的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。
DW(Data Warehouse)即数据仓库:这个概念是由被誉为“数据仓库之父”的WilliamH.Inmon博士提出的:数据仓库是一个面向主题的、集成的、随时间变化的、信息相对稳定的数据集合,它用于对企业管理和决策提供支持。
『
主题:是指用户使用数据仓库进行决策时所关心的重点方面;
集成:是指数据仓库中的信息是经过一系列加工、整理和汇总的过程;
随时间变化:记录过去某一时点到当前各个阶段的信息;
相对稳定:数据进入数据仓库以后,一般很少进行修改,更多的是相对信息的查询操作。
』
BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策。
2. ETL在BI/DW核心的体现
ETL的作用整个BI/DW系统由三大部分组成:数据集成、数据仓库和数据集市、多维数据分析。通常,商务智能运作所依靠的信息系统是一个由传统系统、不兼容数据源、数据库与应用所共同构成的复杂数据集合,各个部分之间不能彼此交流。从这个层面看:目前运行的应用系统是用户花费了很大精力和财力构建的、不可替代的系统,特别是系统的数据。而新建的商务智能系统目的就是要通过数据分析来辅助用户决策,恰恰这些数据的来源、格式不一样,导致了系统实施、数据整合的难度。此时,非常希望有一个全面的解决方案来解决用户的困境,解决数据一致性与集成化问题,使用户能够从已有传统环境与平台中采集数据,并利用一个单一解决方案对其进行高效的转换。这个解决方案就是ETL。
ETL是BI/DW的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么ETL就是建设大厦的过程。在整个项目中最难部分是用户需求分析和模型设计,而ETL规则设计和实施则是工作量最大的,其工作量要占整个项目的60%-80%,这是国内外专家从众多实践中得到的普遍共识。
用户的数据源分布在各个子系统和节点中,利用ETL将各个子系统上的数据,通过自动化FTP或手动控制传到UNIX或NT服务器上,进行抽取、清洗和转化处理,然后加载到数据仓库。因为现有业务数据源多,保证数据的一致性,真正理解数据的业务含义,跨越多平台、多系统整合数据,最大可能提高数据的质量,迎合业务需求不断变化的特性,是ETL技术处理的关键。
3. ETL过程中实现数据清洗的实现方法
首先,在理解源数据的基础上实现数据表属性一致化。为解决源数据的同义异名和同名异义的问题,可通过元数据管理子系统,在理解源数据的同时,对不同表的属性名根据其含义重新定义其在数据挖掘库中的名字,并以转换规则的形式存放在元数据库中,在数据集成的时候,系统自动根据这些转换规则将源数据中的字段名转换成新定义的字段名,从而实现数据挖掘库中的同名同义。
其次,通过数据缩减,大幅度缩小数据量。由于源数据量很大,处理起来非常耗时,所以可以优先进行数据缩减,以提高后续数据处理分析效率。
最后,通过预先设定数据处理的可视化功能节点,达到可视化的进行数据清洗和数据转换的目的。针对缩减并集成后的数据,通过组合预处理子系统提供各种数据处理功能节点,能够以可视化的方式快速有效完成数据清洗和数据转换过程。
4. ETL工具介绍
ETL的工具功能:必须对抽取到的数据能进行灵活计算、合并、拆分等转换操作。
目前,ETL工具的典型代表有:
商业软件:Informatica、IBM Datastage、Oracle ODI、Microsoft SSIS…
开源软件:Kettle、Talend、CloverETL、Ketl,Octopus …
二.Kettle介绍
1. Kettle的今生前世
Kettle 是 PDI 以前的名称,PDI 的全称是Pentaho Data Integeration,Kettle 本意是水壶的意思,表达了数据流的含义。
Kettle 的主作者是 Matt ,他在 2003 年就开始了这个项目,在 PDI 的代码里就可以看到最早的日期大概在2003年4月。 从版本2.2开始, Kettle 项目进入了开源领域,并遵守 LGPL 协议。
在 2006年 Kettle 加入了开源的 BI(Business Intelligence) 组织 Pentaho, 正式命名为PDI, 加入Pentaho 后Kettle 的发展越来越快了,并有越来越多的人开始关注它了。
2. 什么是Kettle?
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
作为Pentaho的一个重要组成部分,现在在国内项目应用上逐渐增多。
Kettle :Kettle is an acronym for “Kettle E.T.T.L. Environment”. This means it has been designed to help you with your ETTL needs: the Extraction, Transformation, Transportation and Loading of data
Kettle 是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;翻译成中文名称应该叫水壶,名字的起源正如该项目的主程序员MATT 在一个论坛里说的哪样:希望把各种数据放到一个壶里然后以一种指定的格式流出。
3. Kettle的安装与运行
1>. 下载安装
可以从 http://kettle.pentaho.org 下载最新版的 Kettle软件 ,同时,Kettle 是绿色软件,下载后,解压到任意目录即可。 由于Kettle 是采用java 编写,因此需要在本地有JVM 的运行环境,我们所使用的Kettle的最新版本是5.1 的。安装完成之后,点击目录下面的kettle.exe 或者spoon.bat 即可启动kettle 。在启动kettle 的时候,会弹出对话框,让用户选择建立一个资源库。
资源库:是用来保存转换任务的, 它用以记录我们的操作步骤和相关的日志,转换,JOB 等信息。用户通过图形界面创建的的转换任务可以保存在资源库中。资源库可以是各种常见的数据库,用户通过用户名/ 密码来访问资源库中的资源,默认的用户名/ 密码是admin/admin. 资源库并不是必须的,如果没有资源库,用户还可以把转换任务保存在 xml 文件中。
2>. 配置Kettle的环境变量:(前提是配置好Java的环境变量,因为他是java编写,需要本地的JVM的运行环境)在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:\kettle\data-integration(具体以安装路径为准)
新建系统变量:KETTLE_HOME
变量值: D:\kettle\data-integration(具体以安装路径为准,Kettle的解压路径,直到Kettle.exe所在目录)
选择PATH添加环境变量:
变量名:PATH
变量值:% KETTLE_HOME%;
3. Kettle的基本概念
1). 作业(job),负责将[转换]组织在一起进而完成某一块工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的作业,当这几个作业都完成了,也就说明这项任务完成了。
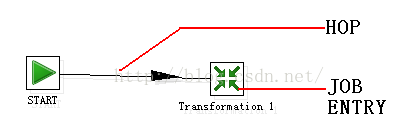
1>. Job Entry:一个Job Entry 是一个任务的一部分,它执行某些内容。
2>. Hop:一个Hop 代表两个步骤之间的一个或者多个数据流。一个Hop 总是代表着两个Job Entry 之间的连接,并且能够被原始的Job Entry 设置,无条件的执行下一个Job Entry,
直到执行成功或者失败。
3>. Note:一个Note 是一个任务附加的文本注释信息。
2). 转换(Transformation),定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比作业粒度更小一级的容器,我们将任务分解成作业,然后需要将作业分解成一个或多个转换,每个转换只完成一部分工作。
1>. Value:Value 是行的一部分,并且是包含以下类型的的数据:Strings、floating point Numbers、unlimited precision BigNumbers、Integers、Dates、或者Boolean。
2>. Row:一行包含0 个或者多个Values。
3>. Output Stream:一个Output Stream 是离开一个步骤时的行的堆栈。
4>. Input Stream:一个Input Stream 是进入一个步骤时的行的堆栈。
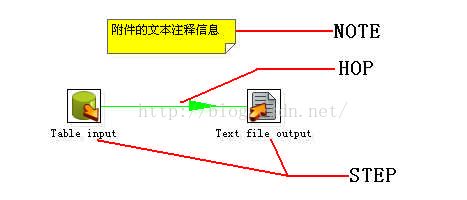
5>. Step:转换的一个步骤,可以是一个Stream或是其他元素。
6>. Hop:一个Hop 代表两个步骤之间的一个或者多个数据流。一个Hop 总是代表着一个步骤的输出流和一个步骤的输入流。
7>.Note:一个Note 是一个转换附加的文本注释信息。
3).Kettle是一个开源的ETL工具,包括了4个部分。
Chef— — 任务(job)设计工具(GUI方式)
Kitchen— — 任务(job)执行器(命令行方式)
Spoon— — 转换(transform)设计工具(GUI方式)
Span— — 转换(transform)执行器(命令行方式)
目前的版本已经看不到Chef的影子了,因为在Spoon里面包含了设计Job的功能。看来Kettle是将设计工具全部集成在了Spoon上面。而Spoon也包括了Job和Transform的执行功能。
SPOON 允许你通过图形界面来设计ETL转换过程(Transformation)和Job。
Spoon 是一个图形用户界面,它允许你运行转换或者任务,其中转换是用Pan 工具来运行,任务是用Kitchen 来运行。Pan 是一个数据转换引擎,它可以执行很多功能,例如:从不同的数据源读取、操作和写入数据。Kitchen 是一个可以运行利用XML 或数据资源库描述的任务。通常任务是在规定的时间间隔内用批处理的模式自动运行。
PAN 允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
KITCHEN也是一个后台运行的程序。
4. Kettle 基本使用
1>. Kettle 的几个子程序的功能和启动方式
Spoon.bat: 图形界面方式启动作业和转换设计器。
Pan.bat: 命令行方式执行转换。
Kitchen.bat: 命令行方式执行作业。
2>. 转换和作业
Kettle 的 Spoon 设计器用来设计转换(Transformation)和 作业(Job)。
•转换主要是针对数据的各种处理,一个转换里可以包含多个步骤(Step)。
•作业是比转换更高一级的处理流程,一个作业里包括多个作业项(Job Entry),一个作业项代表了一项工作,转换也是一个作业项。
3>. 输入步骤简介
输入类步骤用来从外部获取数据,可以获取数据的数据源包括,文本文件(txt,csv,xml,json)数据库、 Excel 文件等桌面文件,自定义的数据等。对特殊数据源和应用需求可以自定义输入插件。 例子:生成随机数步骤
4>. 转换步骤简介
转换类步骤是对数据进行各种形式转换所用到的步骤。
例子:
字段选择
计算器
增加常量
5>. 流程步骤简介
流程步骤是用来控制数据流的步骤。一般不对数据进行操作,只是控制数据流。 例子: 过滤步骤
6>. 连接步骤简介
连接步骤用来将不同数据集连接到一起。 例子: 笛卡尔乘积
7>. 输出步骤简介
输出步骤是输出数据的步骤,常见的输出包括文本文件输出、表输出等,可以根据应用的需求开发插件以其他形式输出。
例子:表输出
8>.在Kettle里元数据的存储方式:
•资源库 资源库包括文件资源库、数据库资源库 Kettle 4.0 以后资源库类型可以插件扩展
•XML 文件 .ktr 转换文件的XML的根节点必须是
数据库资源库:
•把 Kettle 的元数据串行化到数据库中,如 R_TRANSFORMATION 表保存了Kettle 转换的名称、描述等属性。
•在Spoon 里创建和升级数据库资源库
文件资源库:
在文件的基础上的封装,实现了 org.pentaho.di.repository.Repository 接口。是Kettle 4.0 以后版本里增加的资源库类型
不使用资源库: 直接保存为ktr 或 kjb 文件。
Kettle 资源库 – 如何选择资源库?
数据库资源库的缺点:
•不能存储转换或作业的多个版本。
•严重依赖于数据库的锁机制来防止工作丢失。
•没有考虑到团队开发,开发人员不能锁住某个作业自己开发。
文件资源库的缺点:
•对象(如转换、作业、数据库连接等对象)之间的关联关系难以处理,所以删除、重命名等操作会比较麻烦。
•没有版本历史。
•难以进行团队开发。
不使用资源库:使用 svn 进行文件版本控制。
9>.命令行执行Kettle文件
参数格式说明 有两种参数格式 1. /参数名:值 或 -参数名=值 建议使用第一种参数格式.
1.执行test.ktr 文件 日志保存在D:\log.txt 中, 默认日志级别是Basic
Pan /file:D:\AppProjects\nxkh\test.ktr /logfile:D:\log.txt
2.执行test.ktr 文件 日志保存在D:\log.txt 中, 日志级别是Rowlevel
Pan /file:D:\AppProjects\nxkh\test.ktr /logfile:D:\log.txt /level: Rowlevel
3.导出一个 job 文件,以及该 job 文件依赖的转换及其他资源
kitchen /file:c:/job1.kjb /export:c:/a.zip
4.直接执行一个导出的 zip 文件
Kitchen.bat /file:"zip:file:///c:/a.zip!job1.kjb"
5. 常见错误及其排除
1>. 数据库的连接失败

解决办法,是链接相应的数据库的jar包没有加到Kettel中去。在百度或者以前的web项目中找个数据库的jar包。将MySQL-connector-java-5.1.18.jar复制到D:\kettle5.1\data-integration\lib下面,重新启动一次,这下就好了。再次测试,测试通过链接成功。

2>. 传递的数据时出现中文乱码的处理。
在数据库连接选项卡中,在选项中增加命名参数setCharacterEncoding = utf8
另外确保在创建数据库时,Character Set同时也设为utf8.

6. Kettle的变量
1. 变量的类型
Kettle 的早期版本中的变量只有系统环境变量
目前版本中(3.1) 变量包括系统环境变量, "Kettle变量" 和内部变量三种系统环境变量的影响范围很广,凡是在一个 JVM下运行的线程都受其影响.Kettle 变量限制了变量的作用范围, 变量范围包括三种分别是 grand-parent job, parent job, root job 内部变量: 是 kettle 内置的一些变量, 主要是kettle 运行时依赖的环境, 如转换文件名称, 转换路径,ip地址, kettle 版本号等等.
2. 变量的设置
"系统环境变量" 有三种设置方式
1) 通过命令行 -D 参数
2) 属性文件 kettle.property 中设置, 该属性文件位于 ${user.home}.kettle 下
3) 通过设置环境变量步骤 (Set Variable) 设置."Kettle 变量" 只能通过设置环境变量 (Set Variable) 步骤设置,同时设置变量的作用范围.
"内部变量" 是预置的无须设置.
3. 变量的使用
无论哪种类型的变量在使用上都是一样的, 有两种方式
1) 通过 %%var%% 或 ${var} 来引用, 这个引用可以用在 SQL 语句中, 也可以用在允许变量输入的输入框里.
2) 通过获取变量 (Get Variable) 步骤来使用命令行参数:
1. 设置: 命令行参数通过获取系统信息(Get System Info) 步骤设置, 在使用时可以像列名一样来使用,不必像变量一样要通过 ${var} 这样的格式引用. 用户最多可以设置10个命令行参数
2. 传递: 命令行下使用 pan /file:xxx.ktr arg1 arg2 来传递参数.
图形界面下,每次运行时有要求输入参数的提示窗口.
7. Kettle之效率提升
Kettle作为一款ETL工具,肯定无法避免遇到效率问题,当很大的数据源输入的时候,就会遇到效率的问题。对此有几个解决办法:
1)数据库端创建索引。对需要进行查询的数据库端字段,创建索引,可以在很大程度上提升查询的效率,最多的时候,我不创建索引,一秒钟平均查询4条记录,创建索引之后,一秒钟查询1300条记录。
2)数据库查询和流查询注意使用环境。因为数据库查询为数据输入端输入一条记录,就对目标表进行一次查询,而流查询则是将目标表读取到内存中,数据输入端输入数据时,对内从进行查询,所以,当输入端为大数据量,而被查询表数据量较小(几百条记录),则可以使用流查询,毕竟将目标表读到内存中,查询的速度会有非常大的提升(内存的读写速度是硬盘的几百倍,再加上数据库自身条件的制约,速度影响会更大)。同理,对于目标表是大数据量,还是建议使用数据库查询,不然的话,一下子几百M的内存被干进去了,还是很恐怖的。
3)谨慎使用JavaScript脚本,因为javascript本身效率就不高,当你使用js的时候,就要考虑你每一条记录,就要执行一次js所需要的时间了。
4)数据库commit次数,一条记录和一百条记录commit对效率的影响肯定是不一样的。
5)表输入的sql语句的写法。有些人喜欢在表输入的时候,将所有关联都写进去,要么from N多个表,要么in来in去,这样,就要面对我在2)里面说道的问题,需要注意。
6)注意日志输出,例如选择数据库更新方式,而且日志级别是debug,那么后台就会拼命的输出日志,会在很大程度上影响速度,此处一定要注意。
7)kettle本身的性能绝对是能够应对大型应用的,一般的基于平均行长150的一条记录,假设源数据库,目标数据库以及kettle都分别在几台机器上(最常见的桌面工作模式,双核,1G内存),速度大概都可以到5000 行每秒左右,如果把硬件提高一些,性能还可以提升 , 但是ETL 过程中难免遇到性能问题,下面一些通用的步骤也许能给你一些帮助.
尽量使用数据库连接池
尽量提高批处理的commit size
尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)
Kettle 是Java 做的,尽量用大一点的内存参数启动Kettle.
可以使用sql 来做的一些操作尽量用sql
Group , merge , stream lookup ,split field 这些操作都是比较慢的,想办法避免他们.,能用sql 就用sql
插入大量数据的时候尽量把索引删掉
尽量避免使用update , delete 操作,尤其是update , 如果可以把update 变成先delete ,后insert .
能使用truncate table 的时候,就不要使用delete all row 这种类似sql
尽量不要用kettle 的calculate 计算步骤,能用数据库本身的sql 就用sql ,不能用sql 就尽量想办法用procedure , 实在不行才是calculate 步骤.
要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log 生成的方式来了解你的ETL操作最慢的地方。
远程数据库用文件+FTP 的方式来传数据 ,文件要压缩。(只要不是局域网都可以认为是远程连接)
8. Last:Kettle总结
#Kettle的功能非常强大,数据抽取效率也比较高,开源产品,可以进行第三方修改,工具中的控件能够实现数据抽取的大部分需求。
#所有功能支持控件化,使用简单
#Kettle目前还不是特别稳定,并且发现的BUG也特别多
三.Java调用Kettle API
Java代码调用kettle任务
工具 kettle5.1版本
下载地址
所需的包 (这几个包是必须要的,它们相互调用,不引用就报错。)

这些包都可以去kettle 目录C:\***\pdi-ce-5.1.0.0-752\data-integration\lib
下面去找(lib,libswt这几个目录里面有各种包。)另外需要连接数据库,还需要连接数据库的jar包。另外在需要什么包去这里面找。
1. 使用JavaAPI创建(比较繁琐,不做讲解,有兴趣探究)
2. 使用Java调用现成的Transformation或者Job文件。
我们使用Spoo集成的图形化界面工具设计转换和工作。在利用Kettle提供的Java API调用运行。
- package com;
- import org.pentaho.di.core.KettleEnvironment;
- import org.pentaho.di.core.exception.KettleException;
- import org.pentaho.di.core.util.EnvUtil;
- import org.pentaho.di.job.Job;
- import org.pentaho.di.job.JobMeta;
- import org.pentaho.di.trans.Trans;
- import org.pentaho.di.trans.TransMeta;
- /**
- * Running an existing transformation or job.
- *
- * @author Stephen.Huang
- *
- */
- public class KettleTestDemo {
- public static void main(String[] args) {
- String transFileURL = "C:/Kettele5.1_Data/UserToUser.ktr";
- String jobFileURL = "C:/Kettele5.1_Data/Demo/Demo_job1.kjb";
- String transFile1 = "C:/Kettele5.1_Data/Demo/Parameter_demo.ktr";
- String Parameters[] = {"100","500"};
- // 使用runTransformation方法执行transformations
- //runTransformation(transFileURL,null);
- // 使用executeJobs方法执行transformations
- //runJobs(jobFileURL);
- //带参数的transformation
- //runTransformation(transFile1,Parameters);
- }
- /**
- * Run an exist transformation.
- *
- * @param fileURL
- */
- public static void runTransformation(String fileURL,String[] Parameters) {
- System.out.println("使用runTransformation()方法执行" + fileURL + "文件开始");
- try {
- // 初始化kettle环境
- KettleEnvironment.init();
- EnvUtil.environmentInit();
- // 创建ktr元对象
- TransMeta transMeta = new TransMeta(fileURL);
- // 创建ktr
- Trans trans = new Trans(transMeta);
- // 执行ktr
- trans.execute(Parameters); // You can pass arguments instead of null.
- // 等待执行完毕
- trans.waitUntilFinished();
- if (trans.getErrors() > 0) {
- System.out.println("runTransformation()方法执行文件" + fileURL + "时,出现运行时错误:");
- throw new RuntimeException("There were errors during transformation execution.");
- }
- } catch (KettleException e) {
- System.out.println("使用runTransformation()方法执行文件<" + fileURL + ">出错!");
- System.out.println(e);
- } finally {
- System.out.println("使用executeTrans()方法执行" + fileURL + ")结束");
- }
- }
- /**
- * Run an exits job.
- *
- * @param fileURL
- */
- public static void runJobs(String fileURL) {
- System.out.println("------>使用executeJobs()方法执行文件:" + fileURL + " 开始");
- try {
- // 初始化kettle环境
- EnvUtil.environmentInit();
- KettleEnvironment.init();
- // 创建kjb元对象
- JobMeta jobMeta = new JobMeta(fileURL, null);
- // 创建kjb
- Job job = new Job(null, jobMeta);
- job.start();
- //等待执行完毕
- job.waitUntilFinished();
- if (job.getErrors() > 0) {
- System.out.println("runTransformation()方法执行文件" + fileURL + "时,出现运行时错误:");
- throw new RuntimeException("There were errors during transformation execution.");
- }
- } catch (KettleException e) {
- System.out.println("使用executeJobs()方法执行文件<" + fileURL + ">出错!");
- e.printStackTrace();
- } finally {
- System.out.println("----->使用executeJobs()执行文件:" + fileURL + " 结束 ");
- }
- }
- }
参考文献:http://blog.csdn.net/cissyring/article/details/2493865
推荐教材:Pentaho Kettle解决方案:使用PDI构建开源ETL解决方案
参考资料: \\192.168.1.19\Development\InternalApp\share\Stephen
Kettle用户手册:http://wenku.baidu.com/view/99e2d235a32d7375a41780c3.html
PDI Cookbook下载: http://download.csdn.NET/download/baicaicai/3550176