基于opencv的人脸识别
一、需求分析.
1.1 功能与技术需求
1.2 开发环境与运行需求
二、设计过程
2.1 主要技术原理
2.2采用的关键技术
2.3系统设计流程
2.4系统各功能模块
三、 实验运行结果
四、总结提高
4.1课程设计总结
4.2开发中遇到的问题和解决方法
4.3对自己完成课设完成情况的评价
一、需求分析
1.1 功能与技术需求
随着社会的不断进步以及各方面对于快速有效的自动身份验证的迫切要求,生物特征识别技术在近几十年得到了飞速的发展。作为人的一种内在属性,并且具有很强的自身稳定性及个体差异性,生物特征成为了自动身份验证的最理想依据。当前的生物特征识别技术主要包括有:指纹识别,视网膜识别,虹膜识别,步态识别,静脉识别,人脸识别等。与其他识别方法相比,人脸识别由于具有直接,友好,方便的特点,使用者无任何心理障碍,易于为用户所接受,从而得到了广泛的研究与应用。
1.2 开发环境与运行需求
1.2.1开发环境
硬件:
CUP: INTEL CORE I7-6500U
GPU: NVIDIA GeForce 940M
内存:8G
硬盘:PCIE SSD 256G
软件:
Python 3.5
集成开发环境:
IDLE(是安装好python之后,自动安装好的一个python自带的集成开发环境)
相关库:
opencv3.4.3、numpy1.14.6、keras2.2.4、tensorflow cpu1.11.0和sklearn0.20.0。
1.2.2运行需求
通过电脑本地的摄像头,拍摄实时人脸照片,与训练好的卷积神经网络模型中存放的人脸信息进行比对,同时在桌面上显示识别出的人脸标签值。
二、设计过程
2.1 主要技术原理
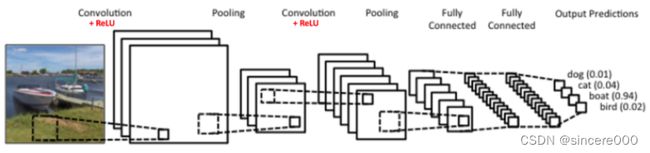
卷积神经网络(Convolutional Neural Network,简称CNN),是一种前馈神经网络,人工神经元可以响应周围单元,可以进行大型图像处理。卷积神经网络包括输入层、卷积层、激活层、池化层和全连接层。
CNN网络结构: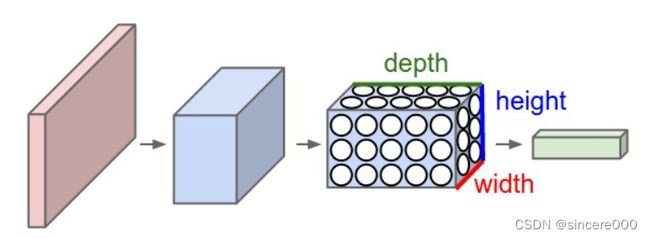
输入层:
与传统神经网络/机器学习一样,模型需要输入的进行预处理操作,常见的3中预处理方式有:
- 去均值
- 归一化
- PCA/SVD降维等
卷积层:
局部感知:人的大脑识别图片的过程中,并不是一下子整张图同时识别,而是对于图片中的每一个特征首先局部感知,然后更高层次对局部进行综合操作,从而得到全局信息。
卷积层使用“卷积核”进行局部感知。举个例子来讲,一个32×32×3的RGB图经过一层5×5×3的卷积后变成了一个28×28×1的特征图,那么输入层共有32×32×3=3072个神经元,第一层隐层会有28×28=784个神经元,这784个神经元对原输入层的神经元只是局部连接,如下图所示:
通过局部感知特性,大大减少了模型的计算参数。但是仅仅这样还是依然会有很多参数。这就有了权值共享机制:
在上面的局部感知中,假设有1m的隐层神经元,每个神经元1010的连接,这样就会有1m10*10个参数。实际上,对于每一层来讲,所有神经元对应的权值应该是相等的,也就是说,第一个神经元的参数向量为[w1,w2,…,w100],那么其他同层的神经元也是[w1,w2,…,w100],这就是权值共享。
为什么需要权值共享呢?同一层下的神经元的连接参数只与特征提取的有关,而与具体的位置无关,因此可以保证同一层中所有位置的连接是权值共享的。例如:第一层隐层是一般用边缘检测,第二层是对第一层学到的边缘曲线组合得到一些特征,比如:角度、线形等;第三层会学到更加复杂的特征,比如:眼睛、眉毛等。对于同一层来说,他们提取特征的方式是一样的,第三层的神经元都是用来提取“眼睛”的特征,因此,需要计算的参数是一样的。
激励层:
所谓激励,实际上是对卷积层的输出结果做一次非线性映射。如果不用激励函数(其实就相当于激励函数是f(x)=x),这种情况下,每一层的输出都是上一层输入的线性函数。容易得出,无论有多少神经网络层,输出都是输入的线性组合,与没有隐层的效果是一样的,这就是最原始的感知机了。
常用的激励函数有:
Sigmoid函数
Tanh函数
ReLU
Leaky ReLU
ELU
Maxout
激励层建议:首先ReLU,因为迭代速度快,但是有可能效果不加。如果ReLU失效的情况下,考虑使用Leaky ReLU或者Maxout,此时一般情况都可以解决。Tanh函数在文本和音频处理有比较好的效果。
池化层:
池化(Pooling):也称为欠采样或下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。主要有:
- Max Pooling:最大池化
- Average Pooling:平均池化

通过池化层,使得原本44的特征图压缩成了22,从而降低了特征维度。
输出层:
经过前面若干次卷积+激励+池化后,终于来到了输出层,模型会将学到的一个高质量的特征图片全连接层。其实在全连接层之前,如果神经元数目过大,学习能力强,有可能出现过拟合。因此,可以引入dropout操作,来随机删除神经网络中的部分神经元,来解决此问题。还可以进行局部归一化(LRN)、数据增强等操作,来增加鲁棒性。
当来到了全连接层之后,可以理解为一个简单的多分类神经网络(如:BP神经网络),通过softmax函数得到最终的输出。整个模型训练完毕。

全连接层:
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:

2.2采用的关键技术
利用opencv获取人脸,采集人脸数据,将收集到的人脸数据加载到内存,搭建属于自己的卷积神经网络,并用人脸数据训练自己的网络,将训练好的网络保存成模型,最后再用opencv获取实时人脸用先前训练好的模型来识别人脸。
搭建卷积神经网络前,需要先完成六个步骤:
第一步需要先把数据加载到内存即将图片预处理之后的图片集,以多维数组的形式,加载到内存,并且要为每一类样本数据标注标签值;
第二步划分数据集即按照交叉验证的原则划分数据集、验证集、训练集。交叉验证是机器学习中的一种常用来精度测试的方法,要先拿出大部分数据用来模型训练,少部分数据用来模型验证,验证结果与真实值计算出差平方和,以上工作重复进行,直至差平方和为0,模型训练完毕,可以交付使用。而在我自己的模型中,导入了sklearn库的交叉验证模块,利用函数train_test_split()函数来划分训练集、验证集和测试集。train_test_split()函数中的test_size参数用来指定划分的比例,另一个参数random_state是用来指定一个随机数种子,从全部数据中随机选取数据建立自己的数据集、验证集和训练集;
第三步要改变图片的维度即我们小组用到了keras库,这个库是建立在tensorflow或者theano基础上的,所以keras库的后端系统可以是tensorflow也可以是theano。但是tensorflow和theano定义的图像数据输入到CNN网络的维度顺序是不一样的,tensorflow的维度顺序为行数(rows)、列数(cols)、通道数(颜色通道,channels);theano则是通道数、行数、列数。所以需要调用函数image_dim_ordering()来确定后端系统的类型(我们用‘th’来代表theano用‘tf’来代表tensorflow),最后用numpy库提供的reshape()函数来调整维度;
第四步采用one-hot编码即因为我的卷积神经网络采用了categorical_crossentropy作为我们的损失函数,而这个函数要求标签集必须采用one-hot编码。所谓的one-hot编码,我理解就是状态位编码,one-hot采用状态寄存器编码,每一个状态值对应一个寄存器,且任意时刻,只有一位是有效的。假设,我们类别有两种分别为0和1,0代表我,1代表others,如果标签为0,编码为[1 0]表示的是第一位有效,如果标签为1,编码为[0 1]表示的是第二位有效。这样做的原因是为了方便CNN操作;
第五步归一化图像数据即数据集先让它浮点化之后又归一化的目的是提升网络收敛速度,减少模型的训练实践,同时适应值域在(0,1)之间的激活函数,增大区分度。归一化有一个特别重要的原因是确保特征值权重一致;
第六步确定优化器即最开始使用的是SGD优化器,SGD优化器随机梯度下降算法参数更新针对每一个样本集x(i) 和y(i) 。批量梯度下降算法在大数据量时会产生大量的冗余计算,比如:每次针对相似样本都会重新计算。这种情况时,SGD算法每次则只更新一次。因此SGD算法通过更快,并且适合online。但是SGD以高方差进行快速更新,这会导致目标函数出现严重抖动的情况。一方面,正是因为计算的抖动可以让梯度计算跳出局部最优,最终到达一个更好的最优点;另一方面,SGD算法也会因此产生过调。之后改进使用了Adam,Adam算法是另一种自适应参数更新算法。和Adadelta、RMSProp算法一样,对历史平方梯度v(t)乘上一个衰减因子,adam算法还存储了一个历史梯度m(t)。mt和vt分别是梯度一阶矩(均值)和二阶矩(方差)。当mt和vt初始化为0向量时,adam的作者发现他们都偏向于0,尤其是在初始化的时候和衰减率很小的时候(例如,beta1和beta2趋近于1时)。通过计算偏差校正的一阶矩和二阶矩估计来抵消偏差。
之后我构建了一个卷积神经网络,这个卷积神经网络一共16层:3层卷积层、2层池化层、3层Dropout层、1层flatten层、2层全连接层和1层分类层。
2.3系统设计流程
2.4系统各功能模块
2.4.1 人脸数据的获取
利用opencv来调用摄像头,获取实时视频流,通过opencv自带的人脸分类器haar来识别并标注出人脸区域,将当前帧保存为图片存到指定的文件夹下面。
catchpicture.py
import cv2
cap = cv2.VideoCapture(0)
num = 0
while cap.isOpened():
ret, frame = cap.read() #读取一帧数据
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)#将图片转化成灰度
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_alt2.xml")
face_cascade.load('D:\python\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml')#一定要告诉编译器文件所在的具体位置
'''此文件是opencv的haar人脸特征分类器'''
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
if len(faces) > 0:
for (x,y,w,h) in faces:
#将当前帧保存为图片
img_name = '%s/%d.jpg'%(r"D:\data\tang", num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > 1000: #如果超过指定最大保存数量退出循环
break
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),2)
#显示当前捕捉到了多少人脸图片
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame,'num:%d'%(num),(x + 30,y + 30),font,1,(255,0,255),4)
#超过指定最大保存数量结束程序
if num > 1000 :break
#显示图像并等待10毫秒按键输入,输入‘q’退出程序
cv2.imshow("capture", frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
2.4.2 图片预处理
第一步获取到的人脸图片集中的每一张图片大小都不一样,为了后续操作的方便需要将捕获到的人脸照片压缩为像素值为64*64的并灰度化处理。所以图片预处理一共分为两部分。第一步定义了一个resize_image()函数作用是先将图片补成正方形之后压缩成像素值为64*64,第二步利用opencv自带的cvtColor()函数将图片灰度化。
picturepraction.py
import os
import cv2
IMAGE_SIZE = 64
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0)
h, w, _ = image.shape
longest_edge = max(h, w)
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
righ = dw - left
else:
pass
BLACK = [0, 0, 0]
constant = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=BLACK)
return cv2.resize(constant, (height, width))
if __name__ == '__main__':
path_name = r"D:\data\tang"
i = 0
for dir_item in os.listdir(path_name):
full_path = os.path.abspath(os.path.join(path_name, dir_item))
i += 1
image = cv2.imread(full_path) #读取出照片
image = resize_image(image) #将图片大小转为64*64
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) #将图片转为灰度图
cv2.imwrite(full_path,image)
2.4.3 图片加载到内存
将图片预处理之后的图片集,以多维数组的形式,加载到内存,并且要为每一类样本数据标注标签值。
loaddata.py
import os
import sys
import numpy as np
import cv2
#读取图片数据并与标签绑定
def read_path(images, labels, path_name, label):
for dir_item in os.listdir(path_name):
full_path = os.path.abspath(os.path.join(path_name, dir_item))
image = cv2.imread(full_path)
images.append(image)
labels.append(label)
def loaddata(parent_dir):
images = []
labels = []
read_path(images, labels, parent_dir+"me", 0)
read_path(images, labels, parent_dir+"tang", 1)
# read_path(images, labels, parent_dir+"jia", 2)
# read_path(images, labels, parent_dir+"other", 3)
images = np.array(images)
print(images.shape)
labels = np.array(labels)
return images,labels
if __name__ == '__main__':
images, labels = loaddata("D:/example/")
2.4.4 构建神经网络
构建一个卷积神经网络,这个卷积神经网络一共16层:3层卷积层、2层池化层、3层Dropout层、1层flatten层、2层全连接层和1层分类层。
face_CNN_keras.py
import random
import numpy as np
from keras.optimizer_v2.adam import Adam
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizer_v2.gradient_descent import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
# ADAM优化器
from keras.optimizers import nadam_v2
from loaddata import loaddata
from picturepraction import resize_image, IMAGE_SIZE
class Dataset:
def __int__(self):
# 训练数据
self.train_images = None
self.train_labels = None
# 验证数据
self.valid_images = None
self.valid_labels = None
# 测试数据
self.test_images = None
self.test_labels = None
# 当前库采用的维度顺序
self.input_shape = None
# 加载数据并预处理
def load(self, img_rows=IMAGE_SIZE, img_cols=IMAGE_SIZE, img_channels=3, nb_classes=4):
images, labels = loaddata("D:/example/")
#print(images.shape)
#print(labels.shape)
# 随机划分训练集、验证集(利用交叉验证原则)
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size=0.3,
random_state=random.randint(0, 100))
# 划分测试集
_, test_images, _, test_labels = train_test_split(images, labels, test_size=0.5,
random_state=random.randint(0, 100))
# 判断后端系统类型来调整数组维度
if K.image_data_format() == 'channels_first': # 如果后端系统是theano,维度顺序为通道数、行、列
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else: # 如果后端系统是tensorflow,维度顺序为行、列、通道数
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
# 输出训练集、验证集、测试集的数量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid_samples')
print(test_images.shape[0], 'test_samples')
# 模型使用categorical_crossentropy作为损失函数
# 因此需要根据图像集数量将图像集标签进行one-hot编码使其向量化
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
# 像素数据浮点化和归一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images
self.valid_images = valid_images
self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
self.test_labels = test_labels
class Model:
def __init__(self):
self.model = None
def build_model(self, dataset, nb_classes=4):
self.model = Sequential()
# 第一层卷积
# 保留边界像素
self.model.add(
Convolution2D(32, 3, 3, padding='same', input_shape=dataset.input_shape, activation='relu')) # 卷积层和激活函数
##输出(32, 64, 64)
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 池化层
# 输出(32, 32, 32)
self.model.add(Dropout(0.5))
# 第二层卷积
# 保留边界像素
self.model.add(Convolution2D(32, 3, 3, padding='same', activation='relu')) # 卷积层和激活函数
##输出(32, 32, 32)
self.model.add(Dropout(0.5))
# 第三层卷积
self.model.add(Convolution2D(64, 3, 3, padding='same', activation='relu'))
# 输出(64, 32, 32)
self.model.add(MaxPooling2D(pool_size=(2, 2)))
# 输出(64, 16, 16)
self.model.add(Dropout(0.5))
self.model.add(Flatten()) # 数据从二维转为一维
# 输出64*16*16 = 16384
# 二层全连接神经网络 512*人的个数
self.model.add(Dense(512))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(nb_classes))
self.model.add(Activation('softmax'))
self.model.summary()
def train(self, dataset, batch_size=20, epoch=10, data_augmentation=True):
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
# self.model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# Adam优化器
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
self.model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
self.model.fit(dataset.train_images, dataset.train_labels, batch_size=batch_size, epochs=10
, validation_data=(dataset.valid_images, dataset.valid_labels), shuffle=True)
MODEL_PATH = 'D:/example/number3.h5'
def save_model(self, file_path=MODEL_PATH):
self.model.save(file_path)
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose=1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
def face_predict(self, image):
if K.image_data_format() == 'channels_first' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
image = resize_image(image)
image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE))
elif K.image_data_format() == 'channels_last' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
image = resize_image(image)
image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
image = image.astype('float32')
image /= 255
# result = self.model.predict_proba(image)
#result = self.model.predict_classes(image)
#return result[0]
predict_x=self.model.predict(image)
classes_x=np.argmax(predict_x,axis=1)
if __name__ == '__main__':
dataset = Dataset()
dataset.load()
model = Model()
model.build_model(dataset)
model.train(dataset)
model.save_model(file_path="D:/example/number3.h5")
2.4.5 识别人脸
利用opencv获取实时人脸数据,调用训练好的卷积神经网络模型,来识别人脸。
faceclassify.py
import cv2
import sys
import gc
from face_CNN_keras import Model
import tensorflow as tf
if __name__ == '__main__':
model = Model()#加载模型
model.load_model(file_path = 'D:/example/number3.h5')
color = (0, 255, 255)#框住人脸的矩形边框颜色
cap = cv2.VideoCapture(0)#捕获指定摄像头的实时视频流
cascade_path = "D:\python\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml"#人脸识别分类器本地存储路径
#循环检测识别人脸
while cap.isOpened():
ret, frame = cap.read() #读取一帧视频
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)#图像灰化,降低计算复杂度
cascade = cv2.CascadeClassifier(cascade_path)#使用人脸识别分类器,读入分类器
faceRects = cascade.detectMultiScale(gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (16, 16))#利用分类器识别出哪个区域为人脸
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
#截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
faceID = model.face_predict(image)
#如果是“我”
if faceID == 0:
cv2.putText(frame, "cjl", (x+30, y+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)#在显示界面输出
print("陈佳乐")#在控制台输出
elif faceID == 1:
cv2.putText(frame, "cym", (x+30, y+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)#在显示界面输出
print("崔逸鸣")#在控制台输出
elif faceID == 2:
cv2.putText(frame, "smm", (x+30, y+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)#在显示界面输出
print("孙漫漫")#在控制台输出
else:
cv2.putText(frame, "unknown",(x+30, y+30),cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)#在显示界面输出
print("unknown")#在控制台输出
cv2.imshow("classify me", frame)
k = cv2.waitKey(10)#等待10毫秒看是否有按键输入
if k & 0xFF == ord('q'):#按q退出
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
- 实验运行结果


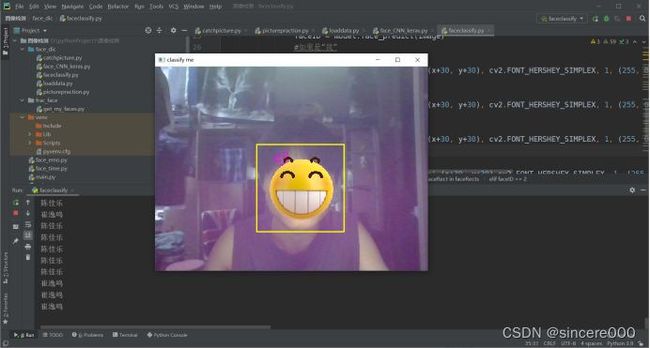
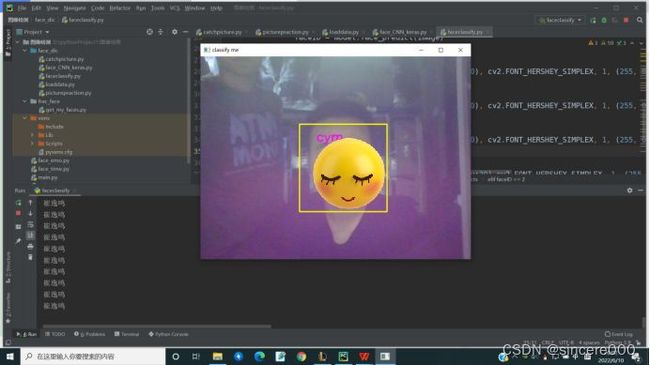

四、总结提高
4.1课程设计总结
在初次尝试进行模型训练时,没有对图片进行细节处理以及数据提升,虽然模型准确率很高,但当使用摄像头进行识别时,会存在识别不准确的情况,因此后面增加了对图像的细节处理以及数据提升处理,预测效果达到预期值,模型最高准确率达到99.93%,损失率0.0067。
数据集的问题,由于是直接采用摄像头进行拍摄,会存在有些角度没有采集完全或者会受到环境因素的影响。到人脸识别对比时,就会只能识别那些角度的特征,换了一个角度就会识别不出来.
4.2开发中遇到的问题和解决方法
(1)问题:搭建CNN网络时出错:ValueError: With n_samples=0, test_size=0.3 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
解决办法:采集的人脸图片样本和经过图像灰度化预处理的样本储存在指定的me文件夹里,因此要将最后处理后的文件转储到文件夹sample中,否则样本集为空。
(2)问题:AttributeError: 'Sequential' object has no attribute 'predict_proba'
解决办法:'Sequential'对象没有属性'predict_proba',将语句改为predict_x=self.model.predict(image) classes_x=np.argmax(predict_x,axis=1)
- 问题:由于版本的问题卷积层Convolution2D函数的内置参数错误
解决办法:将Convolution2D函数的参数改为padding='same'
4.3对自己完成课设完成情况的评价
我们看到一个的东西时,其实眼睛并没有注意到整个物体,而是把注意力集中在一小部分。比如说我们看到一个人时,首先注意到的是他的脸。卷积操作就相当于提取图片的特征信息,相当于将计算机的注意力放在图片的某一部分。我们将中间的隐藏层作为图片输出时,看到的东西会很奇怪,虽然我们看不懂,但这些相当于计算机对这张图片的一种抽象认识。
完成本篇实验报告后对卷积神经网络有了初步的认识。但对其中的激励层、池化层等概念还没有深入彻底的理解,只是模糊的知道大概是干什么的,对深度学习中的数学原理也没有很透彻的理解,还需要今后不断地学习。