MetaTransformer——ViT标准模型结构
Paper地址:https://arxiv.org/abs/2111.11418
GitHub链接:GitHub - sail-sg/poolformer: PoolFormer: MetaFormer is Actually What You Need for Vision (CVPR 2022 Oral)
方法
主流Vision Transformer (ViT)模型的基本模块包含MSA与FFN,其中MSA通过Attention执行Token间相关性建模,实现Context信息编码。由于MSA起到Token信息混合的作用,可抽象为Token mixer。基于Token mixer的一般性作用,MetaTransformer提出了ViT的标准模型结构,如下图所示:

经典的Token mixer可设计为Attention-based module(例如ViT、DeiT等)、MLP-like module(例如ResMLP)。文章基于MetaTransformer标准结构创建了PoolFormer模型,将Token mixer设计为Average pooling(计算非常轻量),并且Forward过程保留了Spatial dimension(没有将HW摊平为Sequence)。PoolFormer包含四个Stage,每个Stage内部的空间分辨率与特征维度相同,不同Stage之间通过PatchEmbed模块实现特征维度增长与空间降采样,降采样率分别为4、8、16与32,具体如下所示:
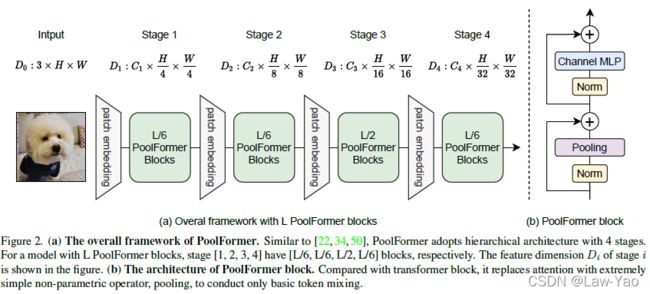
其中Token mixer为Average pooling操作:
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x其中PatchEmbed模块实现特征过渡与空间降采样:
class PatchEmbed(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x文章设计的两个不同参数规模的PoolFormer结构如下:

实验结果
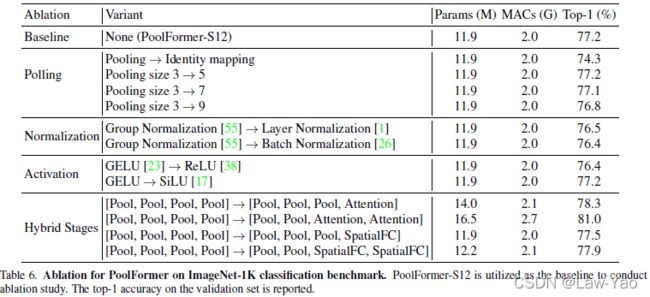
文章在ImageNet-1K、COCO2017、ADE20K数据集上验证了PoolFormer的有效性。并且根据Pooling、Normalization、Activation以及多阶段混合方式,进行了Ablation实验,具体如下: