OpenBox:高效通用的黑盒优化系统

简介
近年来,人工智能与机器学习备受人们关注,越来越多的人使用机器学习模型解决实际问题,如数据分析与预测、人脸识别、商品推荐等。在应用机器学习模型的过程中,模型超参数的选择对模型性能有着重要影响,超参数优化问题成为了机器学习的重要挑战之一。超参数优化是典型的黑盒优化问题,对于优化目标不存在具体表达式或梯度信息,且验证代价较大,其目标是在有限的验证次数内,尽快找到全局最优点。
OpenBox是我们针对黑盒优化设计的一套开源系统,以贝叶斯优化为基础,高效求解黑盒优化问题。其使用场景广泛,不仅支持传统的单目标黑盒优化(如超参数优化),还支持多目标优化、带约束条件优化、多种参数类型、迁移学习、分布式并行验证、多精度优化等。OpenBox不仅支持本地安装与优化调用,还提供在线优化服务,用户可通过网页可视化监控并管理优化过程,也可以部署私有优化服务。
本文首先对黑盒问题及优化算法做简要介绍,然后将介绍我们的开源黑盒优化系统OpenBox。
黑盒优化介绍
首先,什么是黑盒优化?黑盒优化是在有限的验证预算内,对黑盒函数 f : X → R f : X → \R f:X→R 进行优化。但对于任何输入 x ∈ X x \in X x∈X,验证 f ( x ) f(x) f(x) 时,无法得知 f f f 的其他信息,例如表达式或梯度。当验证代价很昂贵时,应当谨慎选择输入参数,尽快达到全局最优值。

上图为一个黑盒函数的示意图,进行黑盒优化的过程中,我们只能通过不断地将数据输入到黑盒函数中,然后利用输出值猜测黑盒函数的结构信息。黑盒函数本身不提供任何有关内部运行的信息。
在白盒优化中,问题的具体形式是已知的,例如,对于线性回归问题,我们可以通过解析表达式求解,或者对于深度神经网络,即使无法直接求解,也可以利用优化目标对参数的梯度信息进行优化。而在黑盒优化中,优化目标的解析表达式及梯度信息均未知,我们无法利用优化目标本身的特性求得其全局最优解。
以机器学习超参数优化为例,我们的目标是找到一组使得机器学习模型性能最好的超参数,因此,函数的输入是模型超参数,输出是机器学习模型通过在这组超参数上执行训练与预测得到的性能评估,模型性能与超参数之间的关系无法用具体表达式刻画。
除了机器学习超参数优化外,黑盒优化在许多领域都有着广泛的应用,如自动化A/B测试、实验设计、数据库参数调优、处理器架构和芯片设计、资源配置优化、自动化化工设计等(如下图)。
 ### 网格搜索与随机搜索
### 网格搜索与随机搜索
解决黑盒优化问题的最朴素方法是网格搜索(Grid Search)和随机搜索(Random Search)。网格搜索也被称为全因子设计(Full Factorial Design),用户对每个超参数给定有限取值集合,网格搜索将在所有超参数取值集合的笛卡尔积上进行验证。显然,这一方法存在维度灾难问题,即随着超参数个数的增加,所需的函数验证次数呈指数级增长。
相对于网格搜索,随机搜索是更有效的方法。随机搜索将在给定的(时间)资源约束内,不断对超参数空间进行采样与验证。在网格搜索的过程中,如果对于优化目标存在不重要的输入参数,当我们固定重要参数,尝试不重要参数的不同取值时,验证结果差异很小,搜索低效,而随机搜索避免了这个问题,能够搜索更多不同重要参数对应的目标值。下图为网格搜索和随机搜索的对比示意。

贝叶斯优化是目前最先进的黑盒优化方法,针对验证代价昂贵的黑盒函数,可以在更少的验证次数内找到全局最优解。贝叶斯优化是基于模型的迭代式优化框架,包含两个重要组成部分,即概率代理模型(probabilistic surrogate model)和采集函数(acquisition function)。优化的主要步骤如下:
- 根据已有历史观测数据,使用概率代理模型,对黑盒函数的输入输出建模。
- 代理模型对输入空间中的候选点预测概率分布,采集函数根据概率代理模型计算候选点的验证价值。
- 优化采集函数,得到价值最高的下一个候选点。使用黑盒函数验证该参数配置,并将结果更新到历史观测数据中。
- 重复以上步骤,直至达到给定资源约束或达到预期效果。
 上图是一维输入空间下贝叶斯优化的一个例子,从上至下的三张图展示了顺序优化过程。图中黑色的虚线代表真实的黑盒函数。初始情况下,利用两个历史观测数据建模,得到概率代理模型。代理模型对输入参数的预测均值以黑色实线表示,预测方差(即不确定性)以蓝色区域大小表示。常用的代理模型有高斯过程(Gaussian Process)、随机森林(Random Forest)、Tree-structured Parzen Estimator(TPE)等。
上图是一维输入空间下贝叶斯优化的一个例子,从上至下的三张图展示了顺序优化过程。图中黑色的虚线代表真实的黑盒函数。初始情况下,利用两个历史观测数据建模,得到概率代理模型。代理模型对输入参数的预测均值以黑色实线表示,预测方差(即不确定性)以蓝色区域大小表示。常用的代理模型有高斯过程(Gaussian Process)、随机森林(Random Forest)、Tree-structured Parzen Estimator(TPE)等。
根据代理模型,采集函数(图中橙色曲线)计算候选输入参数的验证价值。采集函数需要平衡探索(exploration)与利用(exploitation),即权衡选择不确定性高的候选点还是选择性能更优的候选点。相对于黑盒函数,采集函数的验证代价较低,可进行较为充分的优化。常用的采集函数有Expected Improvement、Lower Confidence Bound、Probability of Improvement等。
优化采集函数得到最大值点后(橙色曲线上的x),在黑盒函数上验证这个候选点并得到新的结果,之后我们重新训练代理模型,进行下一轮优化。
OpenBox开源项目
OpenBox是解决黑盒优化(超参数优化)问题的高效且通用的开源系统,我们的设计遵循以下理念:
- 易用:用户以最小代价使用黑盒优化服务,可通过用户友好的可视化界面监控与管理优化任务。
- 性能优异:集成最先进(state-of-the-art)的优化算法,并可自动选择最优策略。
- 资源感知管理:为用户提供基于成本(时间、并行数等)的建议。
- 高效:充分利用并行资源,并利用迁移学习、多精度优化加速搜索。
- 规模可扩展:对于输入维度、目标维度、任务数、并行验证数量等有较好的可扩展性。
- 错误容忍、系统可扩展性、数据隐私保护。
OpenBox使用Python编写,开源项目地址为:https://github.com/thomas-young-2013/open-box
广泛的使用场景
相较于现有的黑盒优化(超参数优化)系统,OpenBox支持更广泛的使用场景,包括多目标优化、带约束条件优化、多种参数类型、迁移学习、分布式并行验证、多精度优化等。OpenBox与现有系统的支持场景对比如下图:

- 多种参数类型(FIOC,即浮点型、整型、序数型、类别型):输入参数不局限于浮点型(实数),例如超参数优化中,SVM模型核函数用类别型表示,如果单纯用整型代替序数型或类别型参数,将对参数附加额外的序关系,不利于模型优化。
- 多目标优化(Multi-objective Optimization):同时优化多个不同(甚至相互冲突)的目标,例如同时优化机器模型准确率和模型训练/预测时间。
- 带约束条件优化(Optimization with Constraints):最优化目标的同时,要满足(黑盒)条件。
现有系统往往不能同时支持以上特性。OpenBox在支持上述场景的基础上,还支持:
- 利用历史任务信息指导当前优化任务,即迁移学习(Transfer Learning)。
- 提供并行优化算法、支持分布式验证,充分利用并行资源。
- 提供多精度(Multi-Fidelity)优化算法,从而在高验证代价场景下(如大数据集,机器模型训练时间较长),进一步加速搜索。
我们会在后续文章中介绍不同场景的使用方法。
高效并多样的优化策略
OpenBox系统默认使用基于随机森林代理模型(Random Forest Surrogate Model)的贝叶斯优化(Bayesian Optimization)算法,该算法对于超参数优化任务有着杰出的表现。相较于同样使用该算法的SMAC3库,OpenBox使用了更多优化策略,使得优化收敛更快,效果进一步提升。
对于贝叶斯优化算法,OpenBox还支持:
- 高斯过程(Gaussian Process)代理模型。
- Tree-structured Parzen Estimator(TPE)模型。
- 多种采集函数(Acquisition Function)如EI、PI、LCB、EIC、EHVI、MESMO、USeMO等。
用户可在系统推荐的基础上自行选择优化策略。
多种使用方法
在现有系统中,Google Vizier为用户提供了一个超参数优化服务(Service)。与算法库(Library)不同,用户无需部署与运行优化算法,只需要与服务交互,获取参数配置、进行验证并更新结果。但是,Google Vizier为谷歌内部服务,并未开源。OpenBox提供了开源优化服务,用户既可以使用我们提供的OpenBox在线服务,也可以通过开源代码将服务部署在自己的服务器中,满足用户自定义与隐私性需求。
目前OpenBox支持全平台(Linux、macOS、Win10)使用,并为用户提供本地和服务两种使用方式:
- 本地使用:用户可通过安装Python包,调用黑盒优化(超参数优化)框架与算法。
- 服务使用:用户可通过接口访问OpenBox服务,从服务端获取推荐的参数配置,在本地执行参数性能验证(如机器学习模型训练与预测)后,将结果更新至服务端。用户可通过访问服务网站页面,可视化监视与管理优化过程。
OpenBox代码已在Github开源,项目地址:https://github.com/thomas-young-2013/open-box 。欢迎更多开发者参与我们的开源项目。
本地使用教程
我们将通过数学函数优化和LightGBM模型超参数优化两个例子,介绍OpenBox系统本地使用方法。安装方法请参考我们的安装教程。
数学函数优化
首先,我们定义输入参数空间,并定义优化目标函数(最小化),这里我们使用Branin函数。
import numpy as np
from openbox import sp
# Define Search Space
space = sp.Space()
x1 = sp.Real("x1", -5, 10, default_value=0)
x2 = sp.Real("x2", 0, 15, default_value=0)
space.add_variables([x1, x2])
# Define Objective Function
def branin(config):
x1, x2 = config['x1'], config['x2']
y = (x2-5.1/(4*np.pi**2)*x1**2+5/np.pi*x1-6)**2+10*(1-1/(8*np.pi))*np.cos(x1)+10
return y
接下来,我们调用OpenBox优化框架Optimizer执行优化。这里我们设置max_runs=50,代表目标函数将计算50次。
from openbox import Optimizer
opt = Optimizer(branin, space, max_runs=50, task_id='quick_start')
history = opt.run()
优化结束后,打印优化结果如下:
print(history)
+---------------------------------------------+
| Parameters | Optimal Value |
+-------------------------+-------------------+
| x1 | -3.138277 |
| x2 | 12.254526 |
+-------------------------+-------------------+
| Optimal Objective Value | 0.398096578033325 |
+-------------------------+-------------------+
| Num Configs | 50 |
+-------------------------+-------------------+
我们可以绘制收敛曲线,进一步观察结果。在Jupyter Notebook环境下,还可以查看HiPlot可视化结果。
history.plot_convergence(true_minimum=0.397887)
history.visualize_jupyter()
LightGBM模型超参数优化
在这个例子中,我们以字典的形式定义任务,其中最关键的是超参数空间定义,即LightGBM模型的超参数与搜索范围。我们的超参数空间包含7个超参数("parameters"字典)。另一个重要的设置是优化轮数(“max_runs”),我们设置为100,代表优化目标将被评估100次,也即训练100次LightGBM模型。
config_dict = {
"optimizer": "SMBO",
"parameters": {
"n_estimators": {
"type": "int",
"bound": [100, 1000],
"default": 500,
"q": 50
},
"num_leaves": {
"type": "int",
"bound": [31, 2047],
"default": 128
},
"max_depth": {
"type": "const",
"value": 15
},
"learning_rate": {
"type": "float",
"bound": [1e-3, 0.3],
"default": 0.1,
"log": True
},
"min_child_samples": {
"type": "int",
"bound": [5, 30],
"default": 20
},
"subsample": {
"type": "float",
"bound": [0.7, 1],
"default": 1,
"q": 0.1
},
"colsample_bytree": {
"type": "float",
"bound": [0.7, 1],
"default": 1,
"q": 0.1
},
},
"num_objs": 1,
"num_constraints": 0,
"max_runs": 100,
"time_limit_per_trial": 180,
"task_id": "tuning_lightgbm"
}
接下来,我们定义优化目标函数,函数输入为模型超参数,返回值为模型平衡错误率。注意:
-
OpenBox对目标向最小化方向优化。
-
为支持多目标与带约束优化场景,返回值为字典形式,且优化目标以元组或列表表示。(单目标无约束场景下也可以返回单值)
目标函数内部包含利用训练集训练LightGBM模型、利用验证集预测并计算平衡错误率的过程。
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.metrics import balanced_accuracy_score
from lightgbm import LGBMClassifier
# prepare your data
X, y = load_digits(return_X_y=True)
x_train, x_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=1)
def objective_function(config):
# convert Configuration to dict
params = config.get_dictionary()
# fit model
model = LGBMClassifier(**params)
model.fit(x_train, y_train)
# predict and calculate loss
y_pred = model.predict(x_val)
loss = 1 - balanced_accuracy_score(y_val, y_pred) # OpenBox minimizes the objective
# return result dictionary
result = dict(objs=(loss, ))
return result
定义好任务和目标函数以后,就可以调用OpenBox优化框架Optimizer的封装接口执行优化。优化结束后,可以打印优化结果。
from openbox import create_optimizer
opt = create_optimizer(objective_function, **config_dict)
history = opt.run()
打印优化结果如下:
print(history)
+------------------------------------------------+
| Parameters | Optimal Value |
+-------------------------+----------------------+
| colsample_bytree | 0.800000 |
| learning_rate | 0.018402 |
| max_depth | 15 |
| min_child_samples | 15 |
| n_estimators | 200 |
| num_leaves | 723 |
| subsample | 0.800000 |
+-------------------------+----------------------+
| Optimal Objective Value | 0.022305877305877297 |
+-------------------------+----------------------+
| Num Configs | 100 |
+-------------------------+----------------------+
同样,我们可以绘制收敛曲线,进一步观察结果。在Jupyter Notebook环境下,还可以查看HiPlot可视化结果。
history.plot_convergence()
history.visualize_jupyter()
系统还集成了超参数敏感度分析功能,依据此次任务分析超参数重要性如下:
print(history.get_importance())
+--------------------------------+
| Parameters | Importance |
+-------------------+------------+
| learning_rate | 0.293457 |
| min_child_samples | 0.101243 |
| n_estimators | 0.076895 |
| num_leaves | 0.069107 |
| colsample_bytree | 0.051856 |
| subsample | 0.010067 |
| max_depth | 0.000000 |
+-------------------+------------+
在本任务中,对模型性能影响最大的前三个超参数分别为learning_rate、min_child_samples和n_estimators。
如果您有兴趣了解OpenBox的更多使用方法(如多目标、带约束条件场景,并行验证,服务使用等),欢迎阅读我们的教程文档:https://open-box.readthedocs.io。
性能实验结果
OpenBox系统对于黑盒优化问题有着优异的表现,我们在多种任务上对比了OpenBox和其他系统的性能。下面我们将展示部分实验结果。
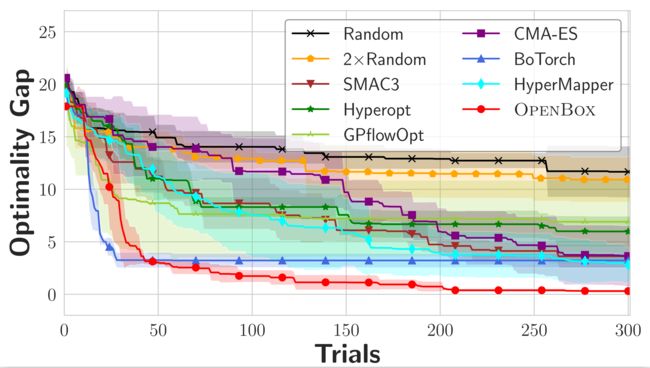
下图为各系统在数学问题上的最优值差异曲线:
| Ackley-4d | Hartmann-6d |
|---|---|
 |
 |
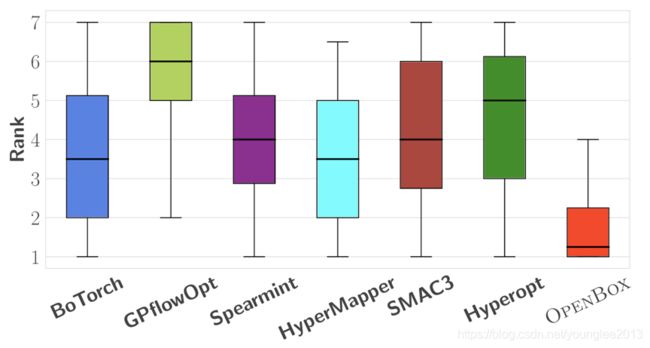
下图为各系统在25个数据集上,对LightGBM模型进行超参数优化后的排名:
此外,我们对比了OpenBox与Google Vizier系统迁移学习算法的性能。实验中,我们给定25个数据集以及在各数据集上单独调参的历史数据信息,每次选择一个数据集,迁移学习算法使用其余24个数据集的历史信息,在该数据集上对模型调参。平均性能排名曲线如下(其中SMAC3为没有使用迁移学习的基准算法):

在各项实验中,OpenBox系统性能均超过了现有系统。
总结
本文介绍了黑盒优化问题,以及我们的开源黑盒优化系统OpenBox(项目地址:https://github.com/PKU-DAIR/open-box),欢迎更多开发者参与我们的开源项目。
在后续文章中,我们将继续介绍OpenBox系统在更多场景下的使用方法,包括服务部署与使用、并行验证、多精度优化等,敬请期待。
参考
[1] https://www.automl.org/wp-content/uploads/2018/11/hpo.pdf
[2] https://zhuanlan.zhihu.com/p/66312442