2021年声纹识别研究与应用学术研讨会笔记
2021年声纹识别研究与应用学术研讨会笔记
声纹识别是国务院认定的远程身份认证方法,在研究过程中要注意信息安全和法律法规的要求,声纹识别是一个比较热的研究方向,ICCASP有36篇和speaker verification有关的文章,其中有涉及多模态、spoofing、鲁棒性、domain adaptation等,未来的应用应该是场景驱动、融合创新的,有一些例如反欺诈需要声纹掩盖等针对技术。我们需要共同维护创新环境,良性发展、合作共赢,要找准赛道,避免恶意竞争(通过非常规手段,侵权压价等),需要建立良性市场生态,可以建立产学研用联盟进行声纹识别的良性发展。
Speaker Recognition and Characterization in Xi-Vector Embedding Space
关键词: speaker embedding
说话人识别一般流程有特征提取、Speaker Embedding和scoring几个过程,首先特征提取有获得特征序列,通过embedding获取等长特征向量,最后进行评分和分类。
同一个人的embedding space内是彼此接近的,因此可以进行简单的几何计算,例如Paris-France+England = London,Paris-France嵌入表示首都的概念。
X-Vector前面经过CNN特征提取后,进行均值和标准差的pooling,通过FC层输出分类概率,第一层FC的输出即为Embedding Vector。
I-Vector使用UBM模型指导GMM做特征映射,i-vector提取的是后验均值估计,组成了嵌入向量。
特征嵌入从supervector到generative embedding再到discriminative embedding,分类器从SVM、JFA到PLDA。
X-Vector的优点是利用了深度模型,数据量大和判别学习,缺点是对非确定因素的建模和处理不强。I-Vector的优点是对非确定因素的建模和处理能力强,但是采用UBM和T矩阵是一个较浅层的模型,随训练数据的增长,性能很快饱和。所以这里提出了Xi / z a i / /zai/ /zai/-Vector结合了X-Vector和i-vector嵌入的优点。
第一个要点是非确定性估计,在encoder中加入uncertainty估计值, Xi-Vector有Encorer、Temporal Aggregation和Decoder三个部分,Encoder包含两层神经网络和两个生成部分,一个是特征,一个是非确定性的估计,输出通过高斯后验概率估计后经过两层FC层输出分类概率,第一层FC输出为Xi-Vector Embedding。实验表明预测结果更加准确,Xi-Vector将生成模型和判别模型进行结合,达到了更加好的效果。具有开源代码。
*说话人分割聚类研究进展与展望
关键词: 图卷积神经网络、聚类
说话人分割聚类:给定一个包含多人交替说话的声音,系统需要判断每个时间段是谁在说话。有很多供使用的竞赛数据集,研究趋势从简单场景到复杂场景, 挑战有噪声干扰、人数未知、语音重叠等等,如何适应新的场景也是一个迫切需要改进的方向。
系统包含分割和聚类两个部分,VAD可以做分割,VAD后进行合并和切片,将语音片段转换为聚类问题。
第一步需要提取嵌入表征向量,之前的方法有AHC聚类可以进行层次聚类,还有SC(谱聚类)、VB\VBx聚类、UIS-RNN(中国餐馆方式)、DNC(神经网络直接进行分类),另外需要进行重叠语音检测。
端到端系统从EEND到TS-VAD等等,聚类算法总结如下:
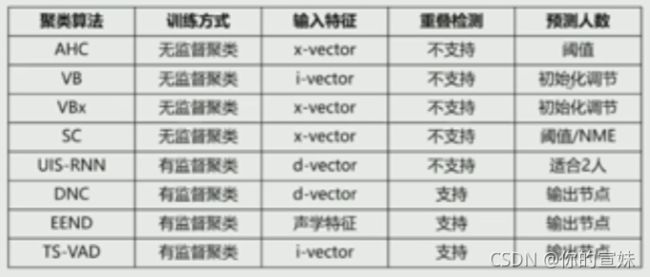
系统对比,CALLHOME数据集中,TDNN+AHC+VB效果最好,DIHARD III数据集中,Cosine相似矩阵和NME-SC的结果最好,重聚类中加入VBx,加入重叠检测很重要。VoxSRC21比赛,包含背景音、笑声杂音等等,提出wav2vec VAD做ASR模型,重叠检测通过VAD第一次分配说话人,OSD第二次分配说话人。提出的单系统已知最优。XMUSPEECH融合系统,实验经验是:
防止过拟合,合理设计子系统。
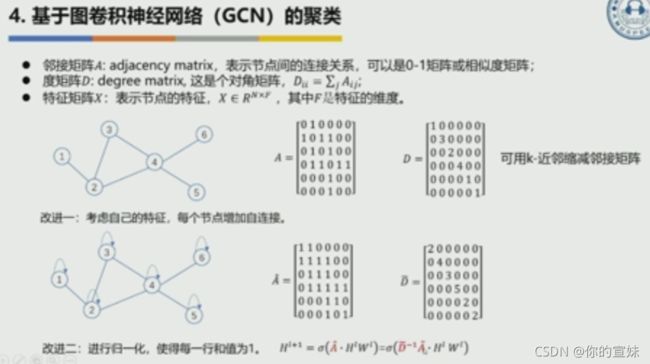
系统存在一些问题,仅依赖于embedding之间的相似度,没有考虑时序关系或者结构信息,可以利用前后时间关系从无监督打分变为有监督打分,后端采用谱聚类,采用图神经网络得到新的embedding,考虑了节点之间的连接关系。
普通卷积神经网络只是从平面结构合并,没考虑节点之间的关系,图卷积网络不仅考虑了节点特征,还有节点之间的关系,多了归一化邻接矩阵。 两种改进:第一种是考虑自己的特征,每个节点增加自链接,第二个是进行归一化,使得每一行和为1。
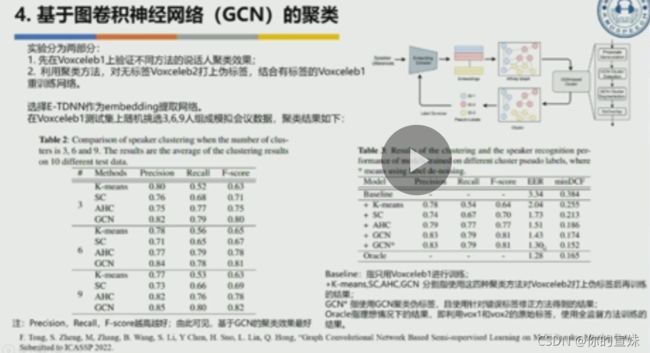
复杂场景、神经网络有监督聚类、在线系统、联合语音识别和多模态等都是可以研究的方向。
Minding on Hard Trials
关键词: hard trails
现在的说话人识别已经达到了很高的水平,但是EER较低效果真的好吗?在其它情境中,有很多模型都是不可用的。
一般的trails都是交叉的方式,两个说话人的数据进行混别成对,其中有很多不靠谱的trails,所以EER非常低。数据里有很多bias,有很多因素影响数据分布,我们需要更加关注那些有bias的点(hard trails)。Hard trails来自分布的交叠部分。

黄色部分是hard trails,需要找到不同模型的正负例重叠区域,经过实验验证其确实是存在各个模型当中的。
除了验证实验,还用人类测试的方式,随困难程度增加,分类准确率降低,机器结果比人类还要好一些。在softmax进行分类时希望有一个margin能够增加正负例的距离,但是m方法不能产生margin的效果。在AM-softmax加入max函数,能达到margin的效果。
Target Speaker Extraction in Multi-Speaker Interaction Scenario
关键词: 语音分离
第一个工作是,可以通过为数据赋予性别标签的方式,将非监督的学习转化为监督学习,把预测单人转化为预测性别的任务。
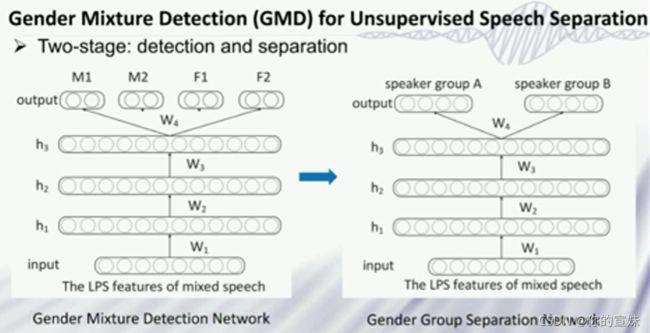
第二个工作,CHiME-5挑战中已经给出diarization结果,但是其中有两人或多人重叠的语音,数据中有回音等噪声,结果不好的原因可能是因为没有考虑噪声等外界因素,这里主要考虑的是在重叠部分做分离。
数据中diarization结果不是完全对应的,做特定说话人分离,如何获取特定人的信息?考虑一个两阶段方法:第一阶段产生更多的目标说话人数据,第二阶段提取更好的目标说话人语音。如果特定说话人的数据比较少,可能结果不是很好。
第三个工作,有一个小孩子的数据库,小孩子不配合录音,所以有很多无关杂音,去掉成人声音等等噪声。采用联合语音分离增强,首先用神经网络进行降噪处理,随后再提取小孩子的语音。把小孩子和大人的声音进行分离,类似于男女的分离。实验中采用diarization中的JER和CSDER(小孩子的声音错误率)作为评估标准。
可以用来做降噪耳机,通过学习特定说话人的声音,做到提取纯人声的效果。
*Multi-Modality Matters: Audio-Visual Deep Neural Networks for Robust Person Verification
关键词: 多模态、数据增强、知识迁移
现在我们很多都是用人脸或声音等解锁手机,但是哪一个模态都做不到100%可靠。人脸识别例如口罩、遮挡、模糊、化妆等会影响人脸的变化,声音识别例如信道污染、长短时问题、多说话人等影响,识别结果会受到影响。
三个问题,如何利用音视两个信息得到更好的结果,如何在污染的情况下保持好的性能,如何用多模态系统提升单模态系统的应用。
传统音视模态结合采用score fusion打分融合的形式,比较简单,性能不错。提出三种融合策略,AVN-F(Feature Level)、AVN-E(Embedding Level)、AVN-J(Joint),是前后端联合训练的网络。
首先是Feature Level,特征通过Transformation提取高维特征后,后进行拼接获得person embedding。提出三种方式,实验中将单模态和特征层面融合的EER结果对比,可以得到明显的性能提升。
其次是embedding level,提出三种方式,同上面一样进行单模态和多模态对比,可以看出多模态系统效果好很多。
复杂场景下,不是每一个模态都能得到高质量的数据,会有模态污染,所以需要在不同level设计好的data argumentation(数据增强)策略,增强模型的鲁棒性。单模态下即使进行数据增强,性能也并未提升很多,多模态进行数据增强后性能有了明显提升。
提出噪声分布匹配,能够生成embedding level的增强data,首先通过embedding extractor得到clean和noisy的embedding,之后得到纯噪声embedding,用高斯模型对其进行建模,可以在clean的embedding上用高斯模型进行随机采样获得新的noise embedding,后用混合数据进行训练。
最后提出了joint的融合方式,通过multitask learning做融合学习,相比于前两种方式有更进一步的下降,和score average融合还有改进。
最后应用的时候可能还是单模态,有没有可能将多模态知识迁移到单模态情况下提高性能呢?传统的教师学生模型中,用教师模型的输出优化学生模型,提出三种方式,label level、embedding level和embedding-distribution level。用多模态系统教单模态系统,以做知识迁移提升学生系统性能。
噪声与远场环境下的声纹识别
关键词: 自组织阵列、鲁棒性、通道加权融合
复杂环境下声纹识别有很多挑战,比如其他声源的加性噪声、信道畸变、多径效应产生的混响和其他说话人干扰等,解决问题包含降噪前端声纹识别系统和声纹识别的域自适应。这里只关注一个内容,基于深度学习的自组织阵列语音处理。但设备前端处理会有很多局限性,性能存在物理上限,信噪比快速降低,对距离说话人的位置、远近较为敏感。阵列中距离语音源的远近会对声纹识别产生严重影响,可以自组织麦克风阵列,将分布在说话人周围的麦克风组织起来,有效避免远场出现概率。物联网大环境的发展趋势即多设备联合处理,给我们语音产业带来指数级的增长空间,需要将传统阵列信号处理方法向自组织阵列拓展。
很多假设在实际中很难满足,导致研究一直在理论状态,是一个小众的研究课题,是否能用深度学习代替理想假设?可以采用深度模型做通道加权,将比较差设备的权重降低、通道同步(将不同厂家设备融合会产生许多问题,如时延不同等),通过深度模型解决,后应用到实际。
我们预测每个设备的信噪比,作为通道的权重。
同时还进行了真实的大规模自组织阵列数据采集,很多数据集的收集有不同步的问题。为了将两个耦合问题节点数规模小和无严格且自然同步数据的两个问题解耦合,采集了严格同步的数据,进行通道融合和通道选择上都有性能的提升。
传统鲁棒声纹识别需要做数据增强,需要将含噪声数据和完好数据进行训练,由于自组织阵列数据量庞大,相似性高有冗余,自组织阵列数据的噪声大,易在噪声不收敛等问题。采用domain adaptation,首先用clean的数据训练声纹识别器,后将参数固定,加入通道加权和融合的模块将多个通道数据融合。
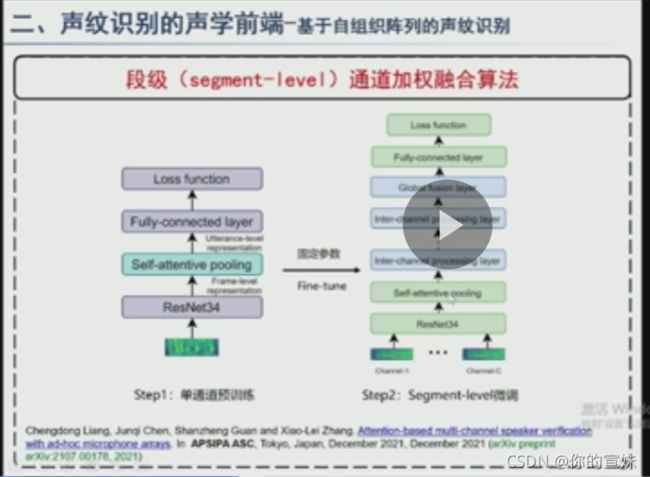
segment-level通道加权融合,cross channel inter processing layer采用multi head selfattention机制。实验结果中Segment-level Sparsemax效果好很多,EER更低。
还有帧级加权融合,对每个通道的帧进行加权,做完加权后对通道进行average,得到通道级fusion,通过pooling层得到x-vector。帧级别甲醛融合在实验中EER有进一步的明显下降。实际应用可能有帧级别不同步的问题。
声纹识别与语音防伪技术前沿及工作进展
关键词: 声纹伪造、前沿技术
语音防伪技术为了防止语音的深度伪造,在日常生活中很多人都接触过,比如就医求助、继续银行转账诈骗等等。法律是禁止滥用AI技术进行诈骗,不仅需要法律约束,还需要采用技术手段防止语音伪造。
技术热点有端到端的模型、联合识别(辅助提升)、噪声问题(鲁棒性)和远场问题等等。引入多尺度、多层次的信息,在X-Vector的主体框架,在特征、结构、池化和损失函数可以进行改进研究。训练策略有Large Margin Fine-tuning,分两阶段训练,预训练使用小margin的loss。还有多头注意力机制、ASP、MHAP等等。
语音防伪技术的评价指标一般是EER和t-DCF,数据层面通过数据增强模拟提升防伪系统性能,特征层面主要是关注于高频特征或者拼接点等,模型层面基本上都是CNN的变体,或者是直接从原始的wave来作为输入,通过加入不同滤波器,也有可能达到很好性能,还有采用多尺度信息。
真实语音基频较为清晰,高频比较模糊,如何提取这些信息很重要,可以通过Attention,关注那些最可能不一样的地方,从各种不同的角度看假在哪里。实验证明,注意力机制可以较好的改善系统的性能。
有一个改进思路:熟悉的人,更容易辨别真伪,利用说话人信息提高防伪性能。第一在特征层面,第二个层面是embedding层面,将LightCNN+AF-SIA对拼接的x-vector进行降维消融实验。
未来工作中,像网络改进、跨模态、标签错误等,Hard Trials和两阶段或者图网络、预训练+声纹或者超大规模(参数百万级以上)都可以多多关注。语音防伪方面主要是与训练+防伪或者考虑学术研究和现实应用中会发生可用性快速下降的问题,做GAN时候可不可以分为真、假或者不确定的情况?
深伪音频鉴别研究进展
关键词: 深伪音频、攻击检测
深伪(Deep Fake),随技术的发展,伪造技术越来越成熟,在商业、艺术、医疗行业也有积极应用,在电信、经济政治社会国民等领域带来诸多风险和威胁。
首先是VAD(切掉静音部分)对鉴伪性能的影响分析,鲁棒性差、VAD导致鉴伪系统性能严重下降。不同伪造方法的静音是有较大差异的,静音部分还是存在鉴别信息的,因此我们可以很好利用静音的区分性进行鉴伪。实验表明,实际上VAD后只用语音信息增加了过拟合,采用纯静音鉴伪效果更好,VAD后的语音如果增加了静音长度信息,效果得到了明显的改善。
第二是双频带融合的语音鉴伪方法,语音合成和转换方法有很多,不同伪造方法对频谱的影响分布在不同频域。低频特征相对于全频带和高频特征,获得了最好的性能。双拼带融合对于VAD后的语音是有效的,双频带融合对于不同特征都有效。
第三个是基于交叉子带算法的回放攻击检测,需要解决的是不匹配数据集上训练获得更好的鲁棒性。非语音部分包含了大量的伪影信息,只是用VAD切出非语音部分训练,但是实验结果不尽人意,可能是因为训练数据不匹配带来了干扰。高频信噪比低于低频,表明高频部分伪影更容易被学习,测试时使用与训练相异的子带可以强迫模型取消对于语音频谱的关注,而是关注更多伪影存在的噪声频谱部分。实验表明在数据集不匹配的情况下,交叉子带算法性能有所提升,且不需要额外的数据加强。交叉子带算法能增加数据广泛度,减少过拟合。
最后是伪造语音的溯源,即用什么算法合成的语音。从声纹图中看不同模型还是有一定区别的,是否存在“模型指纹”存在?变声和合成高频差异较大,找到一些不同声码器的曲线特征:

实验表明声码器溯源还是效果比较好的。
其它还有面向未知算法的伪音频检测、防伪冒音频检测等等。
特定人合成及变声与录音回放语音攻击检测
关键词: 录音回放、攻击方法
Multi-Speaker Text-to-Speech,用到了类似feedback constraint,一般先做文本编码、attention和decoder,目标声纹通过编码器编码。数据分为文本相关、文本无关(实际场景下更多)两个类别,有时候数据中有人的数据是有bias的,constraint可以强制输入和输出一致,使得攻击更有针对性。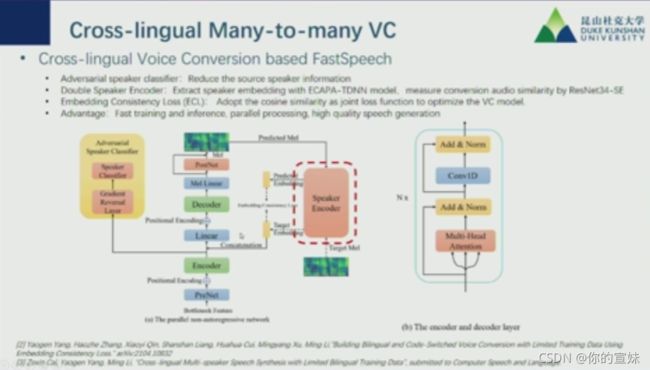
Zero-shot Voice Conversion,训练数据和测试数据是不相干的,可以用中间层梅尔谱表示加speaker encoder输出Mid Embedding全能表示向量。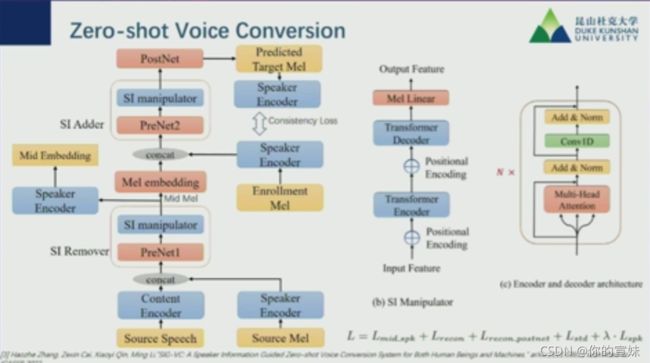
假设一些编码器对于人声来说重建效果好,对于小的干扰没有很好的预测。
声码器越好,能够越能完美重建人声,忽略信道中的噪声等信息。采用GMM和VAE训练,发现两个效果差不多。
鲁棒说话人表征技术
关键词: 鲁棒声纹表征、语音生成、声纹攻击
首先基于二元时间通道频率的说话人表征(DTCF),CNN不能学习通道间的关系,因此引入注意力机制改善通道间交互的学习。因此引入了DTCF在时间和频率维度上聚合全局上下文来重新矫正表征。远场声纹可能有mismatch问题,为解决这个问题,引入ResNet-BAM和DAT减少远近场之间的说话人表征差异,还有前端数据预处理和数据增广来解决。
进场到远场的多级迁移学习,这里用到了Teacher-Student模型,用教师干净语音模型督导带噪语音训练的学生模型。实验表明,效果要好很多,进行可视化可以看出,不同说话人边界较为模糊,通过迁移后发现speaker类之间的间距更加清晰。
Glow-WaveGAN消除声学模型和声码器的鸿沟,提出两段式建模,声学模型到声码器。中文来说音调是很重要的,还通过其他模型提高音质。
当目标声纹样本量很小甚至只有一个,能否完美复制其音色?研究Glow-WaveGAN在不同说话人空间对zero-shot任务的作用。两种方法,第一个是pretrain的encoder,第二种是joint,先训练embedding,后同模型一起进行训练,pre较joint更具复刻UNSEEN说话人的推广能力。
语音增强,能够提升语音质量,实际环境有很多干扰,需要语音前端提升信号质量。DCCRN(复数神经网络语音增强),降噪效果非常好。
在降噪量和语音过度抑制需要平衡,在DCCRN上进行改进,提出很多方案:

改进后语谱保留比较明显。
有可能需要更高采样率需求,提出超宽带语音增强模型S-DCCRN,专门对高频信息进行建模。
在此基础上还有很多拓展方案,可以看到也有其他的拓展,现在有基于声纹先验的语音增强,进行目标说话人提取,效果很不错。
最后是基于查询的说话人识别的黑盒攻击,包含生成攻击、重放攻击和对抗样本攻击(故意添加细微干扰导致预测错误)。攻击分为黑白盒攻击,还有按照攻击者的目的分类,分为目标攻击和非目标攻击。黑盒攻击考察三个方面:对抗样本的迁移性、替代模型和基于心理声学的不可感知扰动。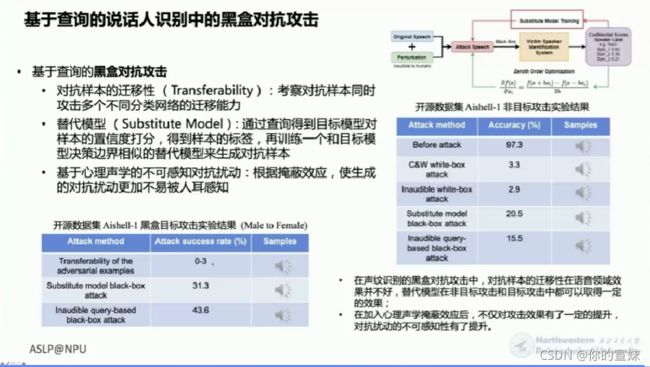
几个数据集的介绍:AISHELL-4多通道录音,AliMeeting数据集语音重叠比例很高,WenetSpeech中文有标注数据集
该模型可能对没有见过的数据有敏感性,如何增强拓展性是一个重要的研究方向。
声纹识别中的鲁棒性学习方法研究
关键词: 信息融合、多任务学习、域匹配
说话人识别一般用在很多保密工作当中,实际应用存在很多问题,例如复杂场景下有噪声、远场、域不匹配、短时不定时长、时间漂移的问题,一般分为两个部分,前端提取特征embedding,后端通过模型处理比对相似性,鲁棒性学习方法需要源和目标域分布基本一致,如果分布存在差异,需要做自监督的域自适应学习。
常用的前端深度模型有很多,如果把网络加深加宽等性能虽然有提升,但是会付出很大的代价,可以采用集成技术,融合多个模型的结果,但是只在结果层面进行融合,却忽视了模型内部的融合。提出融合ResNet和DenseNet(VGG)构建骨干网络,捕捉不同时频分辨率的信息,同时加强特征的重复利用,有串行和并行两种方式,有顺序的结构,也有残差和条约的部分,模型复杂度可控。
与堆叠更多卷积层来加深模型的方法比较,串行DenseR结构用密集连接把残差单元连起来,不会过多增加网络复杂度;与增大通道维度来加宽模型的方法相比较,并行的DenseR结构中,密集连接分量和残差分量不断地进行拼接和分割,对不同的信息进行融合。相对于集成技术把多个模型的输出结果进行融合,这里在每个DenseR单元实现特征的融合。
第二是基于多任务学习框架的说话人识别,前端特征学习通常基于SID(确认,给出样本和标签softmax的形式)任务进行优化,而后端是SV(给两句话判断是不是一个人)任务,两者有差异,而且学习是分阶段的,后端无法对前端特征学习进行指导。联合SID和SV提出多任务学习的框架,融合过程中发现两个loss不匹配。
和triplet loss比较,相同点是都需要构造正负样本对,但是需要计算embedding之间的距离,拉近正例,推开负例,需要一个分类器对正负例进行判别。
第三个是基于自监督的域鲁棒说话人深度特征学习,源域和目标域的分布可能不一致,而且存在多个潜在的子域(很相似的数据但是不同),随后是缺乏目标说话人的标签信息。在后端模型中,对齐两个域的分布,在前端模型中,学习域鲁棒的深度特征,但是主要作用在网络深层或者后端,依赖域的标签信息,难以处理未知的不匹配子域,没有用到潜在说话人的标签信息。
(好像很多方法都是基于框架的问题进行改进的,说明框架的设计很重要)
聚类学习获得的标签存在噪声,聚类结果不准确,类别数也难以确定;对比学习的正负例构造的有效性难以保证,未考虑源域和目标域分布的差异。
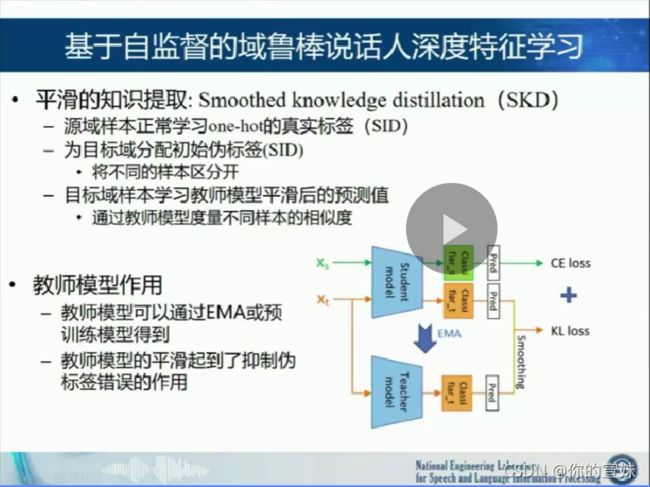
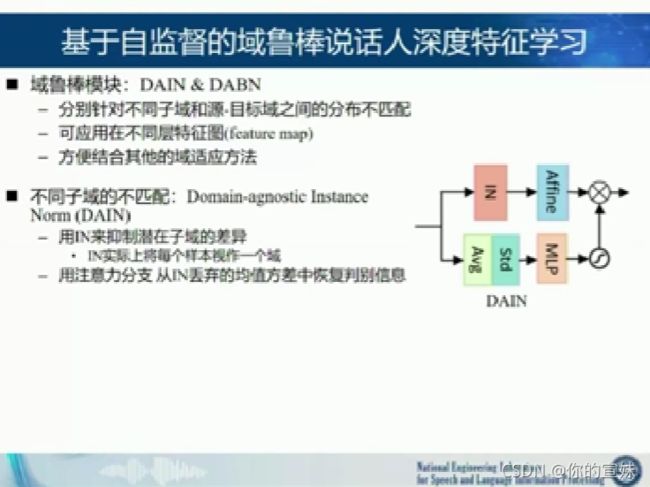
今后可以通过无监督和生成的方式生成样本。
标签噪声干扰下的说话人识别关键技术研究
关键词:
深度模型具有优势,是因为有标签数据的提供,但是通常情况下一般获得的都是错误标记、缺乏标签和干扰的数据。在图像分类领域对标签的研究还是比较早的,标签噪声指的是对样本数据提供了错误的标签。各大数据集会有或多或少的标签错误,那么在采集数据时有两种方法,人工标注或者是网络爬虫众包采集。
方法有修改损失函数,引入正则项,如果遇到标签错误样本,就会赋予比较小的更新权重;数据分段重组,把可能存在标签噪声样本切分出来,作为正确标注样本的增强数据;最后是协同训练,在能够同时训练两个说话人的空间互相监督,减少误标数据带来的影响。还有一种是改进的PLDA,通过引入标签作为隐变量,利用变分贝叶斯估计标签噪声,优化PLDA。
提出方法的框架,神经网络前端优化中,首先是基于标签置信度的训练策略,将源标签和预测标签一起加入模型训练,加上后验概率的权重调整和Sub-Center AM softmax;还有PLDA后端的优化,引入标签隐变量和改进的PLDA模型NL-PLDA,前后端结合能较好的防止噪声干扰。
基于标签置信度的训练策略中,损失函数引入网络预测标签,设计动态权重曲线,损失函数的预测标签权重动态变化效果更好,即更加相信预测标签值。其中很有可能网络单一分类,为了尽量减小loss,把所有数据归为一类,增加正则化项,来约束后验概率逼近平均概率。增加后验概率的权重调整项,可以弱化标签噪声带来的影响。Sub-Center AM softmax相当于正确样例的子中心。
后端针对NL-PLDA数据集的训练,设置了标签的隐变量,对应每个元素 z n , m z_{n,m} zn,m表示第n个样本属于第m个说话人的可能性,更新隐变量时同时计算标签的错误率,这样可以过滤高置信度的标签噪声,设置阈值过滤被错误标注的样本。
数据训练集随机添加各个百分比的噪声,网络设计了6中前端架构配置。实验中对每个部分都做了验证和说明。
应用上做了标签修正后的数据进行对比,性能达到进一步提升,错误率下降非常大;第二个应用是标签清洗,筛选出预测标签和给定标签不一致的样本,NL-PLDA筛选出正确概率较小的样本,实验证明性能提升很大。
我们可以看出标签对模型的负面影响,同时前后端的优化效果较好,可以应用在标签修正、标签清洗的场景。
但是有一些问题,标签噪声和难样本问题,不知道到底是不是错误标签;还可以利用无监督数据,拓展到半监督学习;更加注重实际应用场景。
心得
首先是一般来说,包含的领域和框架是固定的,当然还包括没有发掘的方法。创新可能来源于几个部分,前端、后端和结果等。首先是确定一个框架,上面几个部分的重点在哪,哪个部分有缺陷,选择一个自己感兴趣的领域或者方法。在框架设计当中,需要不断地实验佐证创新的点,通过合理的可视化和对比展示结果。需要注意展望部分,之前介绍了自己做了哪些工作、自己工作解决了什么问题,这里需要介绍还有什么待改进的方向或者未完成的想法等等。