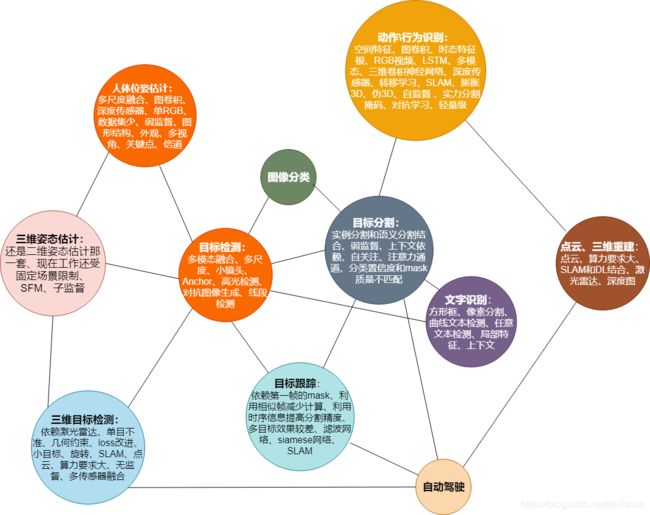
2019计算机视觉方向调研
文章目录
- 一、二维
-
- 方向:
-
- 图像分类、识别(19)(好像有点晚了)
- 目标检测(38)(很火的,很多人都在做)
- 图像分割(也很火,比检测难,但用到分割的方向很多)(50)
- 行为\动作识别(13)
- 人体位姿估计(26)
- 时序动作检测(19)
- 目标跟踪(Deep Learning 还不能完全取代滤波)(单目标短视频短时间难以突破)(20)
- OCR、文字识别(10)(不太感兴趣)
- 图像增强、超分辨(24)(貌似快做到顶了)
- GAN、图像文本生成(还不了解)(25)
- 行人重识别、行人检测(录用文章这么少,说明了什么?)(9)
- 优化方向
- 二、三维
-
- 现在三维方向存在的问题
- 难点
- 方向
-
- 点云、三维重建(涉及多视图几何,单目+炼丹风险较大)(44)
- 姿态估计
- 目标检测
- 发展趋势
- 参考文章
- 三、水下图像问题:
-
- 存在的问题
- 深度学习方法想要达到的效果
- 可针对的点
- 方向
-
- 图像增强
- 参考文章
- 四、趋势
- 五、总结
本文完全自用,看了三十来篇论文的Abstract、Introduction和Related Work,只是想知道一些方向的人在做什么、怎么做的,有些方法可能写的完全不对,但是我现在只要知道有这种方法就行了
一、二维
CVPR进展
方向:
括号内数字是2019CVPR录用数量
图像分类、识别(19)(好像有点晚了)

目标检测(38)(很火的,很多人都在做)
SIGAI目标检测综述
二维目标检测实现和优化方向包括backbone、IoU、损失函数、NMS、anchor、one shot learning/zero shot learning等。
SIGAI目标检测总结与展望
目标检测至今仍然是计算机视觉领域较为活跃的一个研究方向,虽然One-Stage检测算法和Two-Stage检测算法都取得了很好的效果,但是对于真实场景下的应用还存在一定差距,目标检测这一基本任务仍然是非常具有挑战性的课题,存在很大的提升潜力和空间。
论文:
- Stereo R-CNN based 3D Object Detection for Autonomous Driving
现在的大多方法还严重依赖激光雷达,单目深度测不准,作者使用了立体相机,左右照射,基于区域的光度校准,不需要深度输入,用一个新的分支来预测稀疏关键点、视点、对象维度。
作者认为3D目标定位是深度学习辅助几何的问题,而不是端到端的回归问题。

- Generalized Intersection over Union
引入广义GIoU,人们对性能提升的注意力主要放在了架构和提取特征,忽略了改进IoU

- ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape
一种基于深度学习的3D单目检测和特征提取方法,对6D位姿估计和纹理恢复方面效果不错,作者还提出了新的loss公式。
单目图像的深度学习方法已经证明与多传感器方法相比,在三维目标检测,6D位姿跟踪,深度预测,或形状恢复等重要的不适定问题上具有竞争力。作者的改进主要是通过合并强隐式或显式先验来实现的,这些先验将约束不足的输出空间规则化为几何相干解。
- Bi-Directional Cascade Network for Perceptual Edge Detection
边缘检测,提出了一个双向级联网络结构,主要是在多尺度方向上的突破。图像边缘检测可以看作分割、检测、识别的基础。性能已经提到了0.815,但还有提升空间
边缘检测方面存在的问题:1.对象级边界和局部细节:(人体轮廓和手势形状)。有些人用很深的网络,想获得多尺度特征,但是很难训练,推断成本也很高,作者引入了一个尺度增强模型(SEM)。2.CNN网络问题
- RepMet: Representative-based metric learning for classification and few-shot object detection
距离度量学习(DML),在分类的模型上作者做出了创新,用的是多种模式的混合模型来表示每一个类,作者还提出了一个数据集。每类只有几个训练样本来训练分类器的小概率学习问题,DML在小镜头目标检测和目标分类方面很有效。few-shot对象检测,端到端。
三个贡献:架构;DML;基准
- Region Proposal by Guided Anchoring
新的anchor生成方法,现在的一些方法都是密集固定anchor方案,但固定的anchor有两个问题:1.针对不同的问题,要重新定义更好的 2。为了维持足够高的recall,选用大量anchor。
作者的这种方法在Fast RCNN、Faster RCNN、RetinaNet中都有提高。生成anchor有两个准则:对齐和一致性。提出这个方案的动机是观察到物体不是均匀的分布在图像上,所以就想生成稀疏anchor。

- Less is More: Learning Highlight Detection from Video Duration
高光检测有可能极大地简化视频浏览,现在的多是有监督地,需要人类手动识别视频中的高光,作者利用视频时长提出了一个无监督地解决方法,更倾向于短视频。
- AIRD: Adversarial Learning Framework for Image Repurposing Detection
谣言检测和语义完整性检测是较新的研究领域,这一块主要问题是缺少训练和评估的数据,作者设计了一个对抗图像重设检测(AIRD),自己来伪造数据,然后对抗,AIRD包括两个模型:一个伪造者和一个检测器,他们是反向训练的。
- Learning Attraction Field Representation for Robust Line Segment Detection
线段检测,得到线段地图来提供紧凑的结构信息,方便许多高层视觉任务 ,如3D侦察结构,图像分割,立体匹配,场景解析,相机姿态估计,图像拼接等。LSD分两步:线热图生成和线段模型拟合。

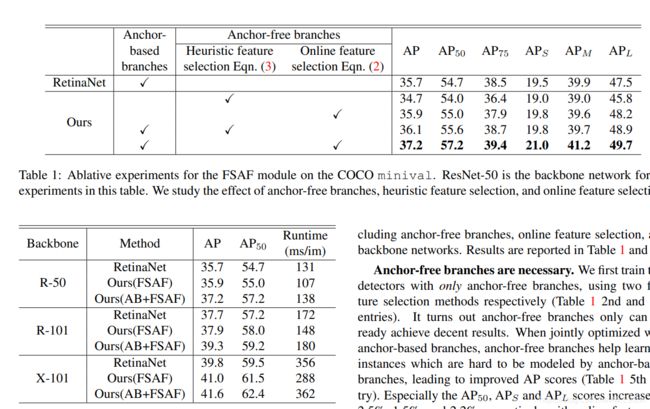
- Feature Selective Anchor-Free Module for Single-Shot Object Detection
提出了一种简单有效的单镜头目标检测模块:特征选择无anchor模块FSAF,它可以插入具有特征金字塔结构的单镜头探测器。FSAF模块解决了传统锚固检测带来的两个局限性:1)启发式引导的有限元结构选择???;2)基于覆盖锚取样。FSAF在coco上比基于anchor的同类模块更好,同时引入了几乎free的推理开销,44.6%的map
针对的是尺度变化这一难点,针对这一难点大多使用的多级特征金字塔。
图像分割(也很火,比检测难,但用到分割的方向很多)(50)
SIGAI视频语义分割
FCN让语义分割有了很大的进步,目前视频语义分割主要研究的重点大致有两个方向:第一个是如何利用视频帧之间的时序信息来提高图像分割的精度,第二个是如何利用帧之间的相似性来减少模型计算量,提高模型的运行速度和吞吐量。
三种分割的区别
论文:
- Attention-guided Unified Network for Panoptic Segmentation
将实例分割和语义分割结合,一种全光分割。
利用上下文信息,注意力选择空间特征,基于分割来聚合线索等。


- Data augmentation using learned transformations for one-shot medical image segmentation
提出了一种自动标注的方法。主要针对医学图像

- FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
之前的方法都过于依赖第一帧的掩码(siammask就是如此),然后后面的自动生成。为了最大限度地保证视频对象的实际能力,本文提出了一种视频对象分割方法,设计目标如下:1.一种VOS方法应该简单:只使用单个神经网络,不使用模拟数据2.在Darticular上,该模型并不依赖于首帧端到端微调:3.多对象分割问题,即每个视频包含不同数量的对象,以端到端的方式解决。
这个方法或许可以用来改进siammask

- FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference。
弱监督情况下,通过随机选择隐藏单元,来获得激活分数,进行图像分类。由于语义分割的数据集很难获取,这个问题就得通过弱监督来解决,以往的弱监督分割效果较差,多用分类器来发现像素之间的关系。使用dropout方法实现FickleNet,发现图像中位置间的关系,扩大了分类器激活的区域,还引入了一种拓展特征图的方法。
相关工作:类激活映射CAM,能识别出贡献较大的隐藏单元


- Dual Attention Network for Scene Segmentation ※
基于自关注机制,通过捕获丰富的上下文依赖关系来处理场景分割任务,提出了双重注意网络DANet来自适应的融合全局特征,而不使用多尺度特征融合。作者认为,像素级的识别,应增强特征表示的识别能力。
近年来,有合并拓展卷积的,还有改变内核大小的方法。尽管有很多中高层语义特征的结构,但是这些也只是对不同大小的对象检测有帮助,没有利用全局视图中对象和内容之间的关系。作者使用了两个注意力模块,一个是位置注意模块,一个是信道注意模块。集成相关特征。
相关工作:特征金字塔,编解码器,上下文的局部特征,递归神经网络,自注意力机制,注意力通道


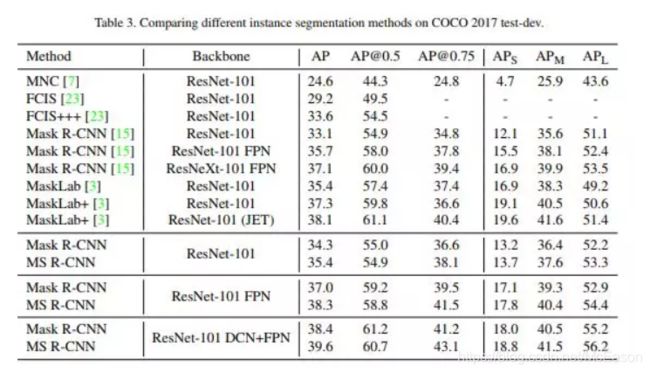
- Mask Scoring R-CNN
这篇论文从实例分割中mask 的分割质量角度出发,提出过去的经典分割框架存在的一个缺陷:用bounding box的classification confidence作为mask score,导致mask score和mask quality 不配准,classification confidence不能代表mask的分割质量。因此文章基于Mask R-CNN提出一个新的框架Mask Scoring R-CNN,能自动学习出mask quality,试图解决不配准的问题。Mask R-CNN其实Faster R-CNN系列的延伸,其在Faster R-CNN的基础上添加一个新的分支用来预测object mask,该分支以检测分支的输出作为输入,mask的质量一定程度上依赖于检测分支。这种简单粗暴的做法取得了SOTA的性能,近年来COCO比赛的冠军或者前几名基本是Mask R-CNN及其变体,但依然有上升的空间。
作者motivation就是想让mask的分数更合理,从而基于mask rcnn添加一个新的分支预测来得到更准确的分数,做法简单粗暴,从结果来看也有涨点。其实mask的分割质量也跟box输出结果有很大关系,这种detection-based分割方法不可避免,除非把detection结果做的非常高,不然mask也要受制于box的结果。这种做法与IoU-Net类似,都是希望直接学习最本质的metric方式来提升性能。
行为\动作识别(13)
SIGAI视频理解
论文:
- An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition
基于骨骼的动作识别中,探索骨架序列的时空特征很重要。作者提出了关注度高的图卷积 LSTM网络(AGC-LSTM),用于从骨骼数据进行人体动作识别,可以捕获空间构型和时间动态的判别特征;提出了一种时态层次结构,增加了AGC-LSTM的时态接受域,提高了高层语义表示的学习能力。
基于RGB视频的方法的局限性:背景杂波、光照变化、外观变化等。三维骨架数据用关键点的三维坐标位置表示身体结构,因此不含颜色信息,不受RGB视频的限制。
现有一些方法:使用LSTM来选择有区别的时空特征;使用CNN学习4、14、10个骨骼的时空特征。使用GCN进行动作识别;用图卷积和LSTM分别表示空间和时间信息。
如何有效的提取识别性空间特征和节奏特征仍然是一个具有挑战性的问题。相关的工作主要都是基于图来做的。


- Improving the Performance of Unimodal Dynamic Hand-Gesture Recognition with Multimodal Training
提出了一种利用多模式知识训练单模态三维卷积神经网络(3D- cnns)进行动态手势识别的有效方法。引入了**“时空语义对齐**”损失(SSA)来对齐来自不同ent网络的特征内容。此外,作者提出的“焦点正则化参数”来规范这种损失,以避免内联知识传递。(???这也太强了吧,一个网络一个loss一个参数)。本文介绍了第三种利用多模态数据在训练过程中的知识,提高单模态系统在测试过程中的性能的框架。三个模态单独使用3D-CNNs
相关工作:基于手工特征提取的手势识别方法,通常用外观、动作线索、骨架来执行手势分类。提出了3D-CNN,融合来自多个传感器的数据流,包括短程雷达、颜色、深度传感器进行识别;多模态数据+注意力模型;主要两个大方法:转移学习,多模态融合。
- Collaborative Spatiotemporal Feature Learning for Video Action Recognition
时空特征学习是视频动作识别的核心内容。现有的深度神经网络工作模型要么独立地学习空间和时间特征(C2D),要么与无约束参数(C3D)联合学习。作者提出了一种新的神经运算方法,通过对可学习参数施加一个权值共享的约束来协同编码时空特征。还是用的二维卷积。对于每一帧的处理可以用深度学习,难点是如何适当融合空间和时间特征。之前的尝试是建立时间信息模型,与空间信息并行。另一方面提出三维卷积神经网络C3D来处理三维立体视频数据。C3D还是计算效率有缺陷。作者提出CoST,将一个三维视频张量压平成三组二维图像,然后对每组进行卷积。
相关工作:之前还是SLAM那一套传统方法,现在C3D用的多了,还有伪3D,膨胀3D(膨胀C2D模型的参数来初始化C3D的参数)。作者的方法是切片CNN

- Neural Scene Decomposition for Multi-Person Motion Capture
引入一种自我监督的学习方法,称之为神经场景分解(NSD),可以用于三维姿态估计,包含三个抽象层:根据边界框和相对深度的空间布局;基于实例分割掩码的二维形状表示;特定主题的外观和3D姿态信息,自监督端到端。目前最先进的三位姿态估计方法是使用深度网络直接从图像返回到三维关节位置或二维关节位置,然后使用另一个深度网络将其提升到三维(两步走)。在这两种情况下,这需要大量的训练数据,可能很难获得。很大的一个挑战就是没有数据集。作者的方法和现有的相比,能处理全帧输入和多个人员。通过转移学习[38]、交叉模态变分[60]和对抗性[83]学习,能解决一定的数据集太少的问题。


- DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition(Facebook)
有个问题在于视频帧计算流是非常耗时的。而且运动矢量有噪声,作者提出了以一个轻量级的运动矢量生成网络,可以减少矢量中的噪声,并限制运动细节。DMC-Net,精度接近使用流,速递比使用光流快两个数量级。作者也提到了三个独立CNNs,设计的网络基于堆叠的运动矢量和残差。最后的效果是每帧0.106ms。作者的贡献:提出了DMC-Net框架;一个轻量级生成器网络。
相关工作:1. 注重视觉中的时间结构和运动信息。使用三维卷积神经网络和光流融合精度很高,但计算成本大。2. 压缩视频动作识别3. 传统光流对动作识别影响不是很多,运动特征学习更测重于生成描述性的动作线索。

人体位姿估计(26)
论文:
- Deep High-Resolution Representation Learning for Human Pose Estimation
该架构从作为第一阶段的高分辨率子网开始,逐步逐个添加高到低分辨率的子网,以形成更多的阶段并连接并行的多分辨率子网。通过在整个过程中反复进行跨越多分辨率并行子网络的信息交换来实现多尺度融合。
使用重复的多尺度融合,利用相同深度和相似级别的低分辨率表示来提高高分辨率表示,反之亦然,从而使得高分辨率表示对于姿态的估计也很充分。因此,该网络预测的热图可能更准确。
- 3D Hand Shape and Pose Estimation from a Single RGB Image
这项工作解决了一个新颖和具有挑战性的问题,从一个单RGB图像估计完整的3D手形状和姿势,作者提出了一种基于图卷积神经网络的方法来重建一个完整的首部曲面三维网格,包含了丰富的手部三维形状和姿态信息。以前的方法用了深度传感器,作者只是用单RGB图像来估计,这种方法现在还不多见。作者用端到端的方法从单RGB图像恢复三维手网格。想做这一块也没有训练数据,作者创建了一个大规模的合成数据集,但是这种效果也不好。所以训练的时候用到了深度图,但在测试的时候还是只用RGB图。
相关工作:最近的单RGB估计三维人体形状和姿态以来SMPL,一种身体形状和姿态模型。为了更好地利用网格拓扑中顶点间的关系,作者提出了利用图神经网络对三维网格顶点进行初始化处理的方法。此外,作者建议在没有3D网格或3D位姿标注的真实世界数据集上进行训练时,利用深度图作为弱3D监督,而不是使用2D剪影或2D关键点来对网络训练进行弱监督。


- Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views
本文研究了在几种标定的摄像机视点下,对多人进行三维姿态估计的问题。该问题的主要挑战是在噪声和不完整的二维位姿预测中寻找交叉视图的响应。以前的大多数方法都是通过使用图形结构模型直接在3D中进行推理来解决这一挑战,由于其巨大的状态空间,这种方法的效率很低。我们提出了一种快速、健壮的方法来解决这个问题。对检测到的二维位姿进行聚类。现在通常二阶段:1.单独的2D图中检测人体关键点部分,2.用这些关键点或部分来重建3D姿态。剩下的挑战是找到被检测关键点之间的跨视图对应关系以及它们属于哪个人。现在二阶段有个3DPS模型,但是开销还是很多。作者观点是:外观线索被忽略了。


- Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
难点是由于近距离相互作用的场景、遮挡和不同的人体尺度,很难获得精确的定位结果。但是深度学习能一定程度上改善这个问题。现有的方法大致可分为两类:,自顶向下框架123,16,4 3]和自底向上框架I 1526]。前者首先检测图像中所有的人类边界框,然后独立估计每个框中的姿态。后者首先独立地检测所有的身体关键点,然后将检测到的身体关节组合成多个人体姿态。这就要求有精准的定位。作者提出了一个信道转移模块 CSM,在此基础上,又设计了一种基于空间的信道智能注意剩余瓶颈(SCARB)算法,对融合后的地形图进行自适应增强。
相关工作:前人经常忽略低层信息。SE只考虑了通道信息,忽略了地形中空间的注意力。在多姿态估计中,空间注意力和信道注意力的应用还很少。

参考文章:
跨视角的方法,如paper3
综述调研及基本方法
单人位姿估计已经做的差不多了
深度学习人体姿态估计算法综述
之前常用先识别各个部分,然后形成连接以创建姿态的方法。
多人姿态估计常用两种方法:1. 比较简单的方法是先使用一个人体检测器,然后再估计检测器检出的每个人的关节,进而恢复每个人的姿态。这种方法被称为自顶向下的方法。2. 另外一种方法是先检测出一幅图像中的所有关节(即每个人的关节),然后将检出的关节连接 / 分组,从而找出属于各个人的关节。这种方法叫做自底向上方法。
深度学习几种方法:1. OpenPose( https://arxiv.org/pdf/1812.08008.pdf )2. DeepCut( https://arxiv.org/abs/1511.06645 )3. RMPE( https://arxiv.org/abs/1612.00137 ) 4. Mask RCNN( https://arxiv.org/abs/1703.06870 )
发展史
回归关键点出来
时序动作检测(19)
目标跟踪(Deep Learning 还不能完全取代滤波)(单目标短视频短时间难以突破)(20)
论文:
- DaSiamRPN的升级版,视觉目标跟踪之SiamRPN++
商汤新工作,DaSiamRPN的升级版:SiamRPN++,在多个跟踪数据集上都是state-of-the-art ,目前论文已被CVPR2019接收(oral)。
利用网络预测长宽比
- CVPR2019 | SiamMask:视频跟踪精度最高,速度最快
在SiamRPN++的基础上,网络主干问题已经被解决,我们可以做更多方向的探索。我们可以非常简单的让输出做更复杂的预测,这就催生了SiamMask这篇文章。
是否更有空间? 文章中还说了些优化方向
单目标:
用到的东西:滤波网络,siamese网络,无监督
成果:Graph Convolutional Tracking 一种在siamese网络下训练GCNS的视觉追踪方法,实现了存在遮挡、突然运动、背景杂波情景下的鲁棒视觉追踪
感觉还是离不开滤波,DL还不能完全取代滤波
跟踪与分割:
SiamMask,在视频跟踪任务上达到最优性能,并且在视频目标分割上取得了当前最快的速度。
MOTS:多目标跟踪到了瓶颈,想要精进要到像素级别才行,到不了像素就解决不了重叠问题,他们做的数据集对像素级的端到端训练效果不错
3D目标跟踪:
还是离不开滤波
参考文章:
论文盘点
综述
MOT方法性能很大程度上取决于目标检测器
未来方向:视频自适应、多摄像机、三维多目标跟踪、场景理解、深度学习、
SIGAI写的深度跟踪综述
近年来,基于深度学习的单目标跟踪算法取得了长足的进步。相对来说,深度学习在多目标跟踪领域的应用,比较多的局限于匹配度量的学习。主要的原因是,在图像识别领域中,例如图像分类、行人重识别问题中,深度学习取得的进展能够较好的直接应用于多目标跟踪问题。然而,考虑对象到之间的交互以及跟踪场景复杂性,多目标跟踪问题中深度学习算法的应用还远没有达到充分的研究。随着深度学习领域理论的深入研究和发展,近年来基于生成式网络模型和基于强化学习的深度学习越来越得到大家的关注,在多目标跟踪领域中,由于场景的复杂性,研究如何采用生成式网络模型和深度强化学习来学习跟踪场景的适应性,提升跟踪算法的性能是未来深度学习多目标跟踪领域研究的趋势。

SIGAI写的视觉跟踪综述
单目标比多目标更广泛,然而单目标的SiamMask已经很强了
单目标常用算法:Mean shift算法,用卡尔曼滤波、粒子滤波进行状态预测,TLD等基于在线学习的跟踪,KCF等基于相关性滤波的算法等。
多目标存在的问题:1. 跟踪目标的自动初始化和自动终止,即处理新目标的出现,老目标的消失 2. 跟踪目标的运动预测和相似度判别,即准确的区分每一个目标 3. 跟踪目标之间的交互和遮挡处理 4. 跟丢目标再次出现时,如何进行再识别问题
多目标算法的多种分类:按照预测校正的跟踪和按照关联方式的跟踪,按照离线方式的关联跟踪和按照在线方式的跟踪,按照确定性推导的跟踪算法和按照概率统计最大化的跟踪等。

OCR、文字识别(10)(不太感兴趣)
SIGAI文本识别综述
论文:
- Shape Robust Text Detection with Progressive Scale Expansion Network
现有挑战两方面:1)现有的基于四边形边界盒的检测器难以定位任意形状的文本,难以将文本完美地封闭在矩形中;2)大多数基于像素分割的检测器可能无法将非常接近的文本实例分离开。作者提出了一个新颖的进行式规模扩展网络(PSENet),它被设计成一个基于分段的检测器,为每个文本实例提供多个预测,这些预测通过将原始文本实例缩小到不同的范围而产生不同的“内核”,提出渐进尺度拓展算法,然后逐步恢复。因为缩小了,所以边界就大了,就更好将实例分割开。
现在的基于bounding box回归和语义分割的融合检测器性能并不理想,曲线文本检测还有很大提升空间,任意形状文本的检测还需要进一步的探索。


- Towards Robust Curve Text Detection with Conditional Spatial Expansion
这篇文章是针对曲线文本检测的,提出一种新的空间条件拓展机制CSE来提供曲线文本检测性能。和以往不同的是,不把曲线文本堪称多边形回归或分类问题,而是把它看作是区域拓展过程。根据CNN和合并特征的上下文信息导出的局部特征,来逐步合并邻近区域(这个和基于图的检测好像啊???)
现在已经很好的解决了不同大小或方向的单词或文本行检测问题。曲线文本检测的挑战来自于不规则的形状和高度变化的方向。两件段的检测和细化生成框的方法,都过度依赖RPN(这个问题好眼熟,之前哪个文章也说过于以来RPN来着???),所以总结:分割和回归的方法都不好!区域拓展之外还有空间依赖关系的计算
相关工作:还是用到了一些目标检测的东西(说到底也确实就是检测),旋转区域建议网络RRPN,旋转区域区域CNN(R2CNN)是Faster RCNN变体,还有EAST和DeepReg。用分割来提取图像中的长文本行已经做的不错了,将FCN和MSER结合起来识别文本块。



- Handwriting Recognition in Low-resource Scripts using Adversarial Learning
手写体单词识别和定位问题,提出了一种学习方法的逆特征变形模块AFDM
图像增强、超分辨(24)(貌似快做到顶了)
自从 Done 等[14]提出应用卷积神经网络的单帧图像超分辨率重建算法(Image Super Resolution Using Conventional NeuralNetwork,SRCNN)以后,就打开了深度学习通往图像超分辨率重建的大门,同时解决了以前需要人为设计特征提取方式的不便,实现了端对端的学习,提高了图像重建的精度

论文
- SKNet——SENet孪生兄弟篇
- CVPR 2019 | 神奇的超分辨率算法DPSR:应对图像模糊降质
- ICCV 2019 | RankSRGAN:排序学习 + GAN 用于超分辨率
- 让模糊图片变视频,找回丢失的时间维度,MIT这项新研究简直像魔术
- 告别AV画质:实时把动画变成4k高清,延时仅3毫秒,登上GitHub趋势榜
极小人脸
方法及缺点
基于前馈深度网络的方法:
- 基于卷积神经网络的SR方法
该方法的特点是将传统的稀疏编码与深度学习的SR方法联系在一起。虽然该方法展现出更好的重建效果,但是,SRCNN在加深网络层数的同时并未获得更好的效果, 其不足之处还包括不适用多尺度放大,训练收敛速度慢,图像块上下文依赖等。
该方法表明深度神经网络端到端的联合优化优于浅层学习方法将特征提取、特征映射和图像重建独立优化。
- 基于极深网络的SR方法
该方法表明极深的网络结构有望进一步提升图像重建质量;采用残差学习和可调梯度裁剪的策略可解决训练过程中梯度消失、梯度膨胀等问题。
- 基于整合先验知识的卷积神经网络SR方法
相比于单任务,多任务学习可有效提高PSNR值。但随着放大倍数的增加,多任务学习与单任务的PSNR值相差不大, 甚至会随着放大倍数的增加而重建失效。在SRCNN-Pr方法的基础上,如何在更高的放大下提高PSNR值成为值得探索的问题。
相比于SRCNN的方法,SRCNN-Pr方法的PSNR值提高优势较弱。该方法表明浅层的卷积神经网络与图像先验信息相结合的方法提升能力有限, 但是, 该方法为领域先验与数据驱动的深度学习训练方法的结合提供了思路。
- 基于卷积稀疏编码的SR方法
该方法表明LR和HR滤波器学习对深度学习网络的滤波器组的设计具有重要的指导意义,有助于保持图像的空间信息并提升重建效果。
表1总结比较了5种前馈深度网络的图像超分辨率算法的不同特点。SRCNN方法将传统的稀疏编码与深度学习相结合,完成了用于图像复原的深度神经网络建设,但也存在一些不足。在SRCNN的基础上,一些方法(VDSR、SRCNN-pr、SCN和CSCSR) 分别从网络结构、先验信息嵌入、滤波器组学习等方法作出改进。VDSR的结果表明“更深的网络, 更好的性能”;SRCNN-pr表明多任务学习可提高算法运算速度;SCN为网络学习稀疏先验提供指导;CSCSR的结果证明ADMM算法可应用于滤波器组学习,并为深度网络的滤波器组学习提供指导。

- 基于反馈深度网络的方法:
反馈深度网络由多个解码器叠加而成,可分为反卷积神经网(Deconvolutional networks,DN) 和层次稀疏编码网络 (Hierarchical sparse coding,HSC) 等。其特点是通过解反卷积或学习数据集的基,对输入信号进行反解。层次稀疏编码网络和反卷积网络相似,仅是在反卷积网络中对图像的分解而在稀疏编码中采用矩阵乘积的方式。 - 基于快速反卷积网络的SR方法
该方法表明,快速反卷积的方法可以达到整合先验信息目的,且反卷积对网络建设提供参考。
- 基于深度递归网络的SR方法
该方法表明递归网络与跳跃连接结合的方法可实现图像层间信息反馈及上下文信息关联,对网络层间连接的建设提供指导。
- 基于深度边缘指导反馈残差网络的SR方法
该方法表明嵌入先验信息到深度网络可以指导边缘特征重建。此外,将图像信号分解到不同的频带分别重建再进行组合的方式可保留图像重要的细节信息。
表2总结比较了三种反馈深度网络的超分辨率算法的优缺点。FD方法的特点是算法运算速度较快, 但生成图像质量一般;针对极深网络层间信息缺乏连接的问题, DRCN方法采用递归监督的策略实现层间信息连接; DEGREE的方法的特点是建立多个损失函数, 完成网络结构优化。

基于双向深度网络的方法:
双向深度网络的方法将前馈网络和反馈网络相结合。既含前馈网络反向传播的特点, 又与反馈网络预训练方法类似。
双向深度网络包括深度玻尔兹曼机 (Deep Boltzmann machines,DBM) 、深度置信网络 (Deep belief networks,DBNs) 和栈自编码器 (Stacked auto-encoders,SAE) 等。
- 基于受限玻尔兹曼机的SR方法
该方法采用对比散度算法, 训练速度较快。相比于SCSR,SCSR与RBM相结合的性能得到进一步提升。
-
基于深度置信网络的SR方法
-
基于堆协同局部自编码的SR方法
该方法表明,NLSS与CLA的组合方式可实现图像高频纹理增强及抑制噪声等功能。
表3总结比较了三种双向深度网络SR算法的优缺点。其中,RBM的算法运算速度较快,但重建图像质量一般;DBNS能较好地恢复图像细节信息, 但算法运行速度一般;DNC有效抑制噪声,并得到纹理信息增强的重建图像。

GAN、图像文本生成(还不了解)(25)
行人重识别、行人检测(录用文章这么少,说明了什么?)(9)
SIGAI文章
优化方向

二、三维
现在三维方向存在的问题
-
之前的都是2D迁移,现在有直接从3D点云下手的方法
《Deep Hough Voting for 3D Object Detection in Point Clouds》 2019.4
《A Simple Pooling-Based Design for Real-Time Salient Object Detection》跟M2Det有点像 -
纯视觉单目3D目标检测在准确率上离预期还有较大差距,可以考虑引入采用深度神经网络结合稀疏激光点云生成稠密点云#对检测结果进行修正目前大多是采用One-Stage的方法进行3D目标的姿态回归,可以考虑使用Two-Stage的方法来,并利用分割的Mask信息目前3D目标检测的标注数据较少,可以考虑引入非监督学习使用更多的几何约束
难点
3D视觉目标检测的难点主要在于:
- 遮挡,遮挡分为两种情况,目标物体相互遮挡和目标物体被背景遮挡
- 截断,部分物体被图片截断,在图片中只能显示部分物体
- 小目标,相对输入图片大小,目标物体所占像素点极少
- 旋转角度学习,物体的朝向不同,但是对应特征相同,旋转角的有效学习有较大难度
- 缺失深度信息,2D图片相对于激光数据存在信息稠密、成本低的优势,但是也存在缺失深度信息的缺点
方向
点云、三维重建(涉及多视图几何,单目+炼丹风险较大)(44)
论文:
- The Perfect Match: 3D Point Cloud Matching with Smoothed Densities
点云不适合在卷积上处理,太耗时了,计算资源消耗大。而且没法指定具有几何意义的卷积核(二维就很好解决),这些内核还学要表现出平移不变性来识别数据中类似的局部结构。所以,现在一般不使用卷积核。
- DeepMapping: Unsupervised Map Estimation From Multiple Point Clouds
深度映射,传统的映射过程包括手工数据关联、传感器姿态初始化和全局优化。对梯度进行了优化,在交点云之间施加几何约束,深度映射可以很容易扩散到解决激光雷达SLAM问题。深度学习不能很好的见图一方面在于,强大的深层语义在准确估计和建模环境的几何属性方面存在限制。
大多数全局方法从两个点云提取特征描述符,用于建立3D到3D的对应关系,用于相对姿态估计,鲁棒估计,例如RANSAC通常用来处理不匹配。前人尝试过使用深度学习来解决视觉历程测量和SLAM问题;用变分自动编码器VAE来表达密集的几何结构;作者的方法不需要任何预训练,是完全的无监督。
姿态估计
论文:
- ICCV 2019 | 微软开源跨视图融合的3D人体姿态估计算法,大幅改进SOTA精度
- 深度学习热度下降,图神经网络、BERT崛起,ICLR 2020提交论文主题分析
- ICCV2019|基于Anchor point的手势及人体3D姿态估计方法A2J
- CVPR2019 | 6D目标姿态估计,李飞飞夫妇等提出DenseFusion
目标姿态估计对许多重要的现实应用都很关键,例如机器人抓取与操控、自动导航、增强现实等。理想情况下,该问题的解决方案要能够处理具有各种形状、纹理的物体,且面对重度遮挡、传感器噪声、灯光条件改变等情况都极为稳健,同时还要有实时任务需要的速度

可能有进展的点:
未来方向:非受限条件下三维人体位姿预测
现在的工作还受一定的固定场景的限制
有用的方法:
- 自监督学习的价值显然是人工智能研究的一个重点。
- SfM(Structure From Motion),主要基于多视觉几何原理,用于从运动中实现3D重建,也就是从无时间序列的2D图像中推算三维信息,是计算机视觉学科的重要分支
目标检测
论文“
- MLOD:基于鲁棒特征融合方法的多视点三维目标检测
- 贾佳亚等提出Fast Point R-CNN,利用点云快速高效检测3D目标
- VoxelRPN
发展趋势

参考文章
写了目前很多方法,还有这些方法的缺陷
三维重建和DL数据集
三、水下图像问题:
存在的问题
图像光照不足、色彩偏离严重
传统处理方法缺陷:
- 依赖退化模型和效率低
- 无法处理好降噪和进行对比度增强之间的先后关系,进而导致重建得到的图像存在噪声消除不够完善或者细节受损的问题;
- 数字图像的多为二维或者三维数字矩阵,数据量十分庞大,算法的迭代耗时过长,从而无法实现实时性。
深度学习方法想要达到的效果
- 信噪比高、清晰度好
- 使用深度估计的深卷积
- 神经网络来解决光场图像的去散射问题
可针对的点
光照不均匀、图像纹理细节模糊、对比度低
会有一些专门用于特定场景的专门图像复原算法
方向
图像增强
论文:
54、CVPR2019 | 港中文&腾讯优图等提出:暗光下的图像增强
提出基于深度学习优化光照的暗光下的图像增强模型,用端到端网络增强曝光不足的照片。
53、CVPR2019 |AR版“神笔马良”:从单张2D图片建立3D人物运动模型,华盛顿大学与Facebook 3D重建
华盛顿大学与Facebook的CVPR论文,从一张普通的2D图片建立一个活生生的3D人物运动模型。
方法:
ResNeXt 和 Inception。
参考文章
2019汇总
四、趋势
参考文章


五、总结