【深度学习】Anaconda3 + PyCharm 的环境配置 4:手把手带你运行 train.py 文件,史上最全的问题解决记录
前 言
文章性质:实操记录
主要内容:主要记录了运行 train.py 文件时遇到的错误以及相应的解决方案。
项目源码:GitHub - SZU-AdvTech-2022/213-Rethinking-Image-Restoration-for-Object-Detection
相关文档:睿智的目标检测 26 :Pytorch 搭建 yolo3 目标检测平台
冷知识+1:小伙伴们不经意的 点赞 与 收藏 ✨ 可以让作者更有创作动力!
目 录
Q1:ModuleNotFoundError: No module named 'tensorboard'
Q2:ImportError: cannot import name 'OrderedDict' from
Q3:ModuleNotFoundError: No module named 'cv2'
Q4:ValueError: Error initializing torch.distributed using env://
Q5:RuntimeError: Distributed package doesn't have NCCL built in
Q6:KeyError: 'LOCAL_RANK'
Q7:FileNotFoundError: [Errno 2] No such file or directory:
Q8:ModuleNotFoundError: No module named 'past'
Q9:RuntimeError: CUDA out of memory.
Q10:OMP: Error #15: Initializing libiomp5md.dll, but found
附:voc_annotation.py
Q1:ModuleNotFoundError: No module named 'tensorboard'
【遇到错误】ModuleNotFoundError: No module named 'tensorboard'

【解决方法】在 Terminal 终端执行 pip install tensorboard 命令,注意在指定的虚拟环境中执行!可用 activate 环境名 激活指定的虚拟环境。
pip install tensorboard
Q2:ImportError: cannot import name 'OrderedDict' from
【遇到错误】ImportError: cannot import name 'OrderedDict' from 'typing' (D:\Anaconda3\envs\rethink\lib\typing.py)

【解决方法】根据错误提示,打开 maxvit.py 文件,查看其第 3 行,这里的 OrderedDict 应该用 typing_extensions 包里的,将第 3 行改为:
from typing import Any, Callable, List, Optional, Sequence, Tuple
from typing_extensions import OrderedDict

Q3:ModuleNotFoundError: No module named 'cv2'
【遇到错误】ModuleNotFoundError: No module named 'cv2'

【解决方法】在 Terminal 终端执行 pip install opencv-python 命令,注意在指定的虚拟环境中执行!可用 activate 环境名 激活指定的虚拟环境。

Q4:ValueError: Error initializing torch.distributed using env://
【遇到错误】ValueError: Error initializing torch.distributed using env:// rendezvous: environment variable RANK expected, but not set
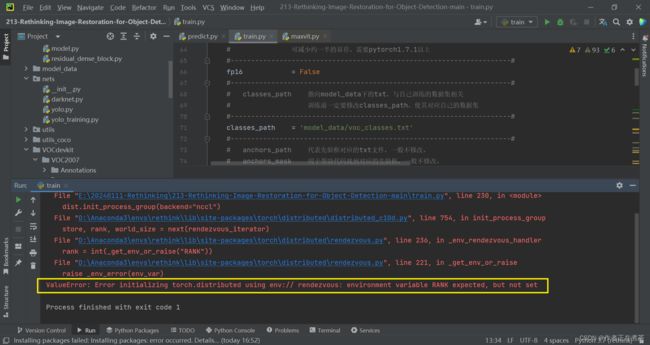
【解决方法】在代码的合适位置处增加:
import torch.distributed as dist
import os
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '5678'
dist.init_process_group(backend="nccl", init_method='env://', rank=0,
world_size=int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1)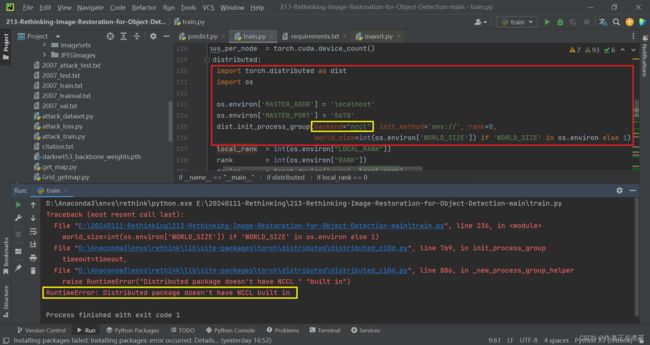
Q5:RuntimeError: Distributed package doesn't have NCCL built in
【遇到错误】RuntimeError: Distributed package doesn't have NCCL built in
【解决方法】将 dist.init_process_group 中 backend 的值改为 "gloo" 。

Q6:KeyError: 'LOCAL_RANK'
【遇到错误】KeyError: 'LOCAL_RANK'
【解决方法】将 distributed 的值改为 False 。注意 distributed 用于指定是否使用单机多卡分布式运行。

Q7:FileNotFoundError: [Errno 2] No such file or directory:
【遇到错误】FileNotFoundError: [Errno 2] No such file or directory: '/data/yks/yolov3/VOCdevkit/VOC2007/...

【解决方法】修改 voc_annotation.py 中的 annotation_mode=2 ,运行 voc_annotation.py 重新生成根目录下的 2007_train.txt 和 2007_val.txt 。

【说明】由于源代码链接中未提供 voc_annotation.py 文件,因此我从 Bubbliiiing 的 GitHub 项目中拿了~我把代码放在了文章的最后!
Q8:ModuleNotFoundError: No module named 'past'
【遇到错误】ModuleNotFoundError: No module named 'past'
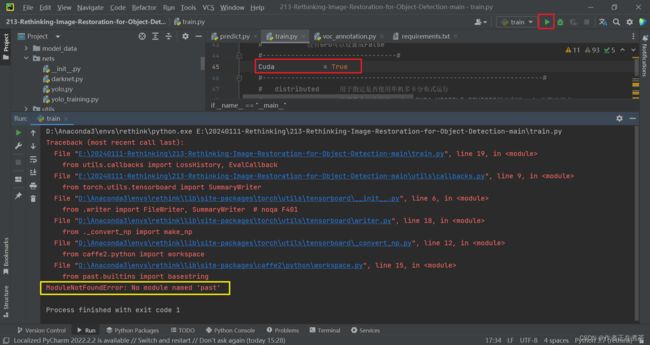
【解决方法】在 Terminal 终端执行 pip install future 命令,注意在指定的虚拟环境中执行!可用 activate 环境名 激活指定的虚拟环境。
pip install future
Q9:RuntimeError: CUDA out of memory.
【遇到错误】RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 2.00 Gi...
【解决方法】调整 batch_size 的大小,在这里是将 Freeze_batch_size 的值改为 4 ,将 Unfreeze_batch_size 的值改为 2 。


Q10:OMP: Error #15: Initializing libiomp5md.dll, but found
【遇到错误】OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.

【解决方法】在代码的合适位置处添加:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"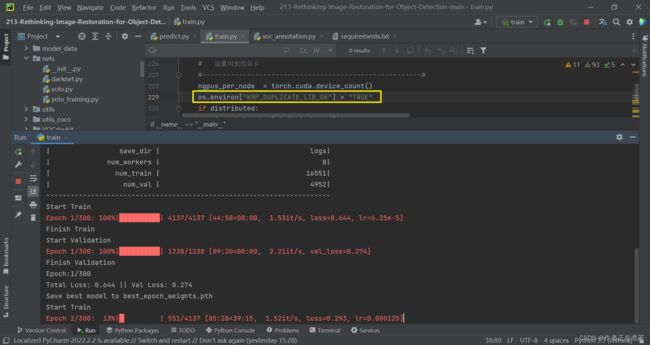
附:voc_annotation.py
import os
import random
import xml.etree.ElementTree as ET
from utils.utils import get_classes
#--------------------------------------------------------------------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#--------------------------------------------------------------------------------------------------------------------------------#
annotation_mode = 2
#-------------------------------------------------------------------#
# 必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
# 与训练和预测所用的classes_path一致即可
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
# 仅在annotation_mode为0和2的时候有效
#-------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#--------------------------------------------------------------------------------------------------------------------------------#
# trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
# train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
# 仅在annotation_mode为0和1的时候有效
#--------------------------------------------------------------------------------------------------------------------------------#
trainval_percent = 0.9
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'
VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)
def convert_annotation(year, image_id, list_file):
in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml'%(year, image_id)), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
if __name__ == "__main__":
random.seed(0)
if annotation_mode == 0 or annotation_mode == 1:
print("Generate txt in ImageSets.")
xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("train size",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
if annotation_mode == 0 or annotation_mode == 2:
print("Generate 2007_train.txt and 2007_val.txt for train.")
for year, image_set in VOCdevkit_sets:
image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt'%(year, image_set)), encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg'%(os.path.abspath(VOCdevkit_path), year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
print("Generate 2007_train.txt and 2007_val.txt for train done.")