DE-Net: Dynamic Text-guided Image Editing Adversarial Networks(DE-Net: 动态文本引导图像编辑对抗网络)
1.DE-Net: Dynamic Text-guided Image Editing Adversarial Networks(DE-Net: 动态文本引导图像编辑对抗网络) 2022

2.机构:南京邮电大学
github:
https://github.com/tobran/DE-Net\
2.摘要:
文本引导的图像编辑模型已经显示出显着的效果。然而,仍然存在两个问题。首先,他们采用固定的操作模块来满足各种编辑需求(例如,颜色变化、纹理变化、内容添加和删除),这导致过度编辑或编辑不足。其次,它们没有清楚地区分需要文本的部分和与文本无关的部分,从而导致编辑不准确。为了解决这些限制,我们提出:
(i)动态编辑块(DEBlock),它动态地组合不同的编辑模块以满足各种编辑要求。
(ii) 一个组合预测器 (Comp-Pred),它根据对目标文本和源图像的推断来预测 DEBlock 的组合权重。
(iii) 动态文本自适应卷积块 (DCBlock),它查询源图像特征以区分需要文本的部分和与文本无关的部分。
3.介绍
图1。受益于动态编辑设计,我们的DE-Net可以处理各种编辑任务 (例如,颜色更改,内容编辑)。此外,DCBlock中的文本自适应卷积可以实现更精确的操作。
4.贡献
1. 我们提出了一种新颖的动态文本引导编辑块 (DEBlock),以使我们的模型可以通过不同编辑模块的动态组成自适应地处理各种编辑任务
2. 我们提出了一个新颖的构图预测器(CompPred),它根据文本和视觉特征的推断来预测DEBLOCK的构图权重。
3.我们提出了一种新颖的动态文本自适应卷积块 (DCBlock),它可以区分源图像的文本必需部分和与文本无关的部分
4. 与当前最先进的方法相比,我们的DE-Net在常用的公共数据集上实现了更好的性能
5.The Proposed DE-Net。方法
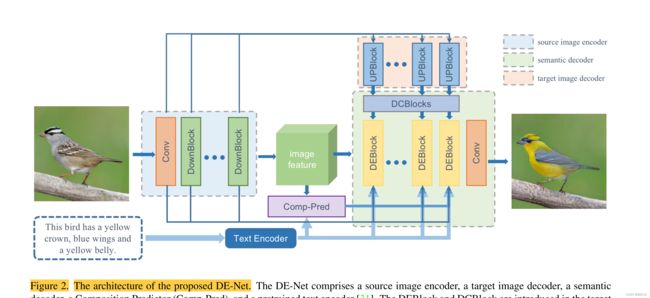
图 2. 提出的 DE-Net 的架构。 DE-Net 包括源图像编码器、目标图像解码器、语义解码器、组合预测器 (Comp-Pred) 和预训练文本编码器 [31]。在目标图像解码器中引入了 DEBlock 和 DCBlock,以分别实现有效和准确的操作 。
6.Dynamic Text-guided Image Editing Frame-work:
(一) our DE-Net can be formulated as:
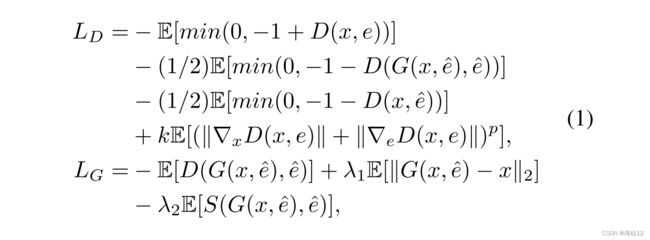
其中,x表示源图像; e表示源句嵌入,![]() 表示目标句嵌入,G表示生成器网络,D表示鉴别器网络,k和p是鉴别器的两个超参数,以平衡梯度惩罚的有效性。S表示由预先训练的DAMSM网络 预测的编码视觉和文本特征之间的余弦相似性。λ1和 λ2是发电机的两个平衡系数.
表示目标句嵌入,G表示生成器网络,D表示鉴别器网络,k和p是鉴别器的两个超参数,以平衡梯度惩罚的有效性。S表示由预先训练的DAMSM网络 预测的编码视觉和文本特征之间的余弦相似性。λ1和 λ2是发电机的两个平衡系数.
(二) Composition Predictor
为了使我们的DE-Net能够根据当前的源图像和文本指导来组成合适的编辑过程,我们提出了组成预测器 (Comp-Pred)。如图2和图3所示,对于视觉信息,它采用编码的4 × 4图像特征,并通过两个卷积层将其映射到视觉矢量V。对于文本信息,它采用文本编码器提供的句子嵌入,并通过onehidden-layer MLP将其映射到文本向量T。然后,我们将V和T连接起来,并通过MLP获得V 和T ,以缩小视觉和文本域之间的差距。计算差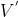 −
− 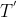 和元素积 * 并与原始向量V和T连接,以增强文本和视觉信息之间的距离。最后,我们采用MLP和Sigmoid函数来预测目标图像解码器中N个块块的空间编辑和信道编辑的组合权重 α
和元素积 * 并与原始向量V和T连接,以增强文本和视觉信息之间的距离。最后,我们采用MLP和Sigmoid函数来预测目标图像解码器中N个块块的空间编辑和信道编辑的组合权重 α

(三)Dynamic Text-guided Image Editing Block (DEBlock)
如图3(b) 所示,解块由上采样层,卷积层和两种仿射层组成。一个是通道方向仿射层 (C-Affine),另一个是空间仿射层 (S-Affine)。为了完全操纵源图像特征,我们的块块操纵空间和通道尺寸,并通过Comp-Pred预测的组合权重 α n动态地组合这两个操纵。

具体来说,在 C-Affine 中,文本句子向量 t 被发送到两个不同的单隐藏层 MLP,以预测每个通道的缩放参数 γc 和移位参数 θc:

从MLPs得到 γ c和 θ c参数后,C-Affine变换可以形式化表示如下:

与 C-Affine仿射不同,S-Affine在图像特征的空间维度上应用仿射变换。空间缩放参数 γ h,w和移位参数 θ h,w由DCBlock和两个卷积层针对图像特征中的每个像素预测。如图4所示,DCBlock采用文本自适应卷积层得到文本参与的视觉特征f。然后,通过两个卷积层对预测的文本参与的视觉特征进行空间缩放和移位参数的预测
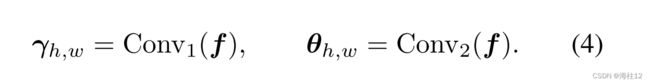

我们的模型在DEBlock中集成了C仿射和S仿射。并且目标图像解码器中的第n个解块通过Comp-Pred预测的组合权重 α n动态地组合了这两个操作:

(四)Dynamic Text-adaptive Convolution Block(DCBlock)
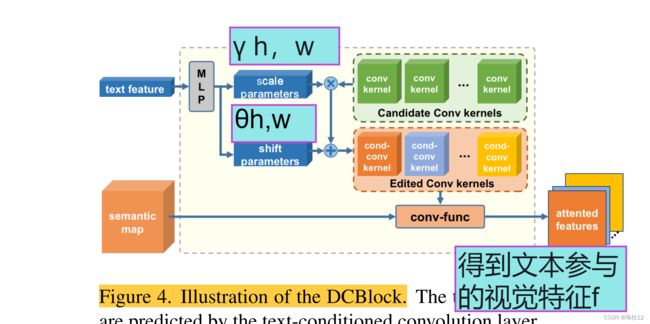 图4。DCBlock的插图。文本参与特征由文本条件卷积层预测
图4。DCBlock的插图。文本参与特征由文本条件卷积层预测
为了提高操作模块的编辑精度,我们提出了DCBlock作为编辑定位模块。如图4所示,根据给定的文本指导来调整DCBlock中卷积核的权重。但是,直接生成卷积内核的所有参数不仅需要很高的计算成本,而且还会导致对训练文本描述的过度拟合。为了解决这个问题,我们对每个候选卷积内核应用缩放和移位操作。首先,我们使用两个mlp来预测卷积内核的缩放参数 φ c in和移位参数 ω c in。一个卷积核上的调制可以正式表示如下:

6.Experiments
我们在两个具有挑战性的数据集上进行实验: 幼鸟 [27] 和可可 [14]。对于幼鸟数据集,有11,788图像属于200种鸟类,每个图像对应十种语言描述。对于COCO数据集,它包含用于训练的80k图像和用于测试的40k图像。每个图像对应5种语言描述。

7.可视化结果
图5。不同方法对幼崽和可可测试一下集的定性比较
8.conclusion 结论
在本文中,我们为文本引导的图像编辑任务提出了一种新颖的 DE-Net。与以前的模型相比,我们的 DE-Net 可以更正确、更准确地根据文本引导操作源图像。通过 DENet,我们提出了一个动态文本引导编辑块(DEBlock),使我们的模型能够通过不同编辑模块的动态组合来自适应地处理各种编辑任务。我们还提出了一种新颖的合成预测器(Comp-Pred),它比较源图像特征和给定的文本指导,并预测 DEBlock 的组合权重。此外,我们提出了一种带有语义解码器的新动态文本自适应卷积块 (DCBlock),以帮助目标图像解码器区分需要文本和与文本无关的部分。广泛的实验结果表明,所提出的 DE-Net 在 CUB 和 COCO 数据集上都显着优于最先进的模型。