2021TPAMI/图像处理:Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation
2021TPAMI/图像处理: Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation:利用深层生成先验进行多功能图像恢复和处理
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.图像先验
- 2.2.图像恢复和操作
- 2.3.GAN反演
- 3.方法
-
- 3.1.深层生成图像先验
- 3.2.鉴别器引导渐进重建
- 3.3.技术细节
- 4.应用
-
- 4.1.图像恢复
-
- 4.1.1.着色
- 4.1.2.图像修复
- 4.1.3.超像素
- 4.1.4.DGP的灵活性
- 4.1.5.DGP的泛化能力
- 4.1.6.消融实验
- 4.1.7.应用于StyleGAN和PGGAN
- 4.1.8.对抗的防御
- 4.2.图像处理
-
- 4.2.1.随机抖动
- 4.2.2.图像变形
- 4.2.3.类别转换
- 5.分析与讨论
-
- 5.1.微调生成器的影响
- 5.2.DGP是外部学习+内部学习
- 5.3.失败案例
- 6.结论
- 参考文献
论文下载
代码地址
0.摘要
学习良好的图像先验知识是图像恢复和处理的长期目标。虽然像深度图像先验(DIP)这样的现有方法捕获低级图像统计信息,但对于捕获丰富图像语义(包括颜色、空间一致性、纹理和高级概念)的图像先验来说,仍然存在差距。这项工作提供了一种有效的方法来利用在大规模自然图像上训练的生成性对抗网络(GAN)捕获的图像。如图1所示,深度生成先验(DGP)提供了令人信服的结果来恢复各种退化图像的缺失语义,例如颜色、面片、分辨率。它还支持各种图像处理,包括随机抖动、图像变形和类别转移。这种高度灵活的恢复和操作是通过放宽现有GAN反演方法的假设而实现的,这些方法倾向于固定发生器。值得注意的是,我们允许生成器以渐进的方式进行动态微调,通过GAN中鉴别器获得的特征距离进行正则化。我们表明,这些易于实现且实用的更改有助于保留重建以保留在多个自然图像中,从而导致对真实图像进行更精确和可靠的重建
1.概述
学习图像先验模型对于解决图像恢复和处理的各种任务至关重要,如图像彩色化[1]、[2]、图像修复[3]、超分辨率[4]、[5]和对抗防御[6]。在过去的几十年中,人们提出了许多图像先验知识来获取自然图像的某些统计信息。尽管他们取得了成功,但这些先验知识通常都有其特定的用途。例如,马尔可夫随机场[7]、[8]、[9]通常用于建模相邻像素之间的相关性,而暗通道先验[10]和总变差[11]则分别用于去噪和去噪。
人们对通过深度学习模型获取更丰富图像统计信息的更一般先验知识的兴趣激增。例如,关于深度图像先验(DIP)[12]的开创性工作表明,随机初始化卷积神经网络(CNN)的结构隐式捕获纹理级图像先验,因此可以通过微调它来重建损坏的图像,从而用于图像恢复。SinGAN[13]进一步表明,随机初始化的生成性对抗网络(GAN)模型在从单个图像进行训练后,能够捕获丰富的补丁统计信息。这些先验知识在一些低级别图像恢复和处理任务(如超分辨率和协调)上显示了令人印象深刻的结果。在这两部具有代表性的作品中,CNN和GAN都是从一个感兴趣的图像开始训练的。
在这项研究中,我们有兴趣更进一步,研究如何利用在大规模自然图像上训练的GAN,获得比单个图像更丰富的先验知识。GAN是一种很好的自然图像流形逼近器。通过从大型图像数据集学习,它获取了有关自然图像的丰富知识,包括颜色、空间一致性、纹理和高级概念,这些知识对于更广泛的图像恢复和操作效果非常有用。具体来说,我们将折叠图像(例如灰度图像)作为原始自然图像的部分观察,并使用GAN在观察空间(例如灰度空间)中重建它,GAN的图像先验将倾向于以忠实的方式恢复缺失的语义(例如颜色),以匹配自然图像。尽管GAN具有巨大的潜力,但将其作为常规图像恢复和处理的先验知识仍然是一项具有挑战性的任务。关键的挑战在于需要处理来自性质明显不同的不同任务的任意图像。重建还需要生成符合自然图像流形的清晰、逼真的图像。
对于我们的问题,一个可行的选择是GAN反转[15][16][17][18]。现有的GAN反演方法通常通过优化潜在代码来重建目标图像,即z∗= arg minz∈Rd L(x, G(z;θ)),其中x为目标图像,G为固定生成器,z和θ分别为潜在代码和生成器参数。在实践中,我们发现这种策略在处理复杂的现实世界图像时失败了。特别是,它经常导致不匹配的重建,其细节(如物体、纹理和背景)与原始图像不一致,如图2 (b)©所示。一方面,现有的GAN反演方法仍然存在模式崩溃[19]和生成器容量有限的问题,影响了其获取所需数据流形的能力。另一方面,可能一个更关键的限制是,当生成器是固定的,GAN不可避免地受到训练分布的限制,其反演不能很好地重建不可见的复杂图像。当使用GAN作为一般图像恢复和操作的先验时,进行这样的假设是不可行的。
尽管近似流形和真实流形之间存在差距,GAN生成器仍然能捕获自然图像的丰富统计信息。为了在利用这些统计数据的同时避免上述局限性,本文提出了一种较为宽松、实用的GAN先验挖掘重构公式。我们的第一个重新表述是允许生成器参数在目标图像上实时微调,即θ∗,z∗= arg minθ,z L(x, G(z;θ))。这解除了将重构限制在训练分布内的限制。然而,通过微调来放松假设仍然不足以保证任意目标图像的良好重建质量。我们发现,在DIP中使用标准损失(如知觉损失[20]或均方误差(MSE))进行微调可能会冒着抹掉原有丰富先验的风险。因此,在重建退化图像的过程中,重建可能变得越来越不自然。图2(d)显示了一个例子,表明需要一种新的损失和重建策略。
因此,在我们的第二次重组中,我们设计了一个有效的重组战略,该战略包括两个部分:
- 由耦合鉴别器引起的特征匹配损失-我们充分利用训练GAN的鉴别器来正则化重构过程。注意,在训练过程中,生成器经过优化,通过鉴别器提供的梯度来模拟大量的自然图像。在引导生成器匹配单个图像时,仍然采用鉴别器是合理的,因为该鉴别器比其他距离度量更好地保留了生成器的原始参数结构。因此,从鉴别器中获得特征匹配损失有助于维持重建保持在自然图像空间。虽然鉴别器特征匹配损失在文献[21]中并不新鲜,但其对GAN重建的意义尚未被研究。
- 在重建退化的图像时,随内容的变化而变化。这是因为在高级配置对齐之前,生成器的深层层开始匹配低级纹理。为了解决这个问题,我们提出了一个渐进重建策略,从最浅层到最深层逐步微调生成器。这允许重构从匹配高级配置开始,并逐渐将其焦点转移到低级细节上
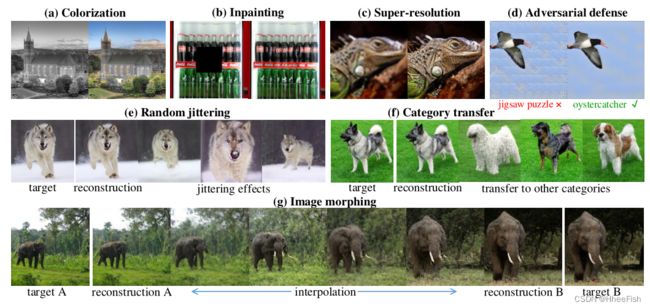
图1所示。这些图像恢复(a)(b)©(d)和操作(e)(f)(g)的效果是通过仅仅利用GAN的丰富生成先验而没有任务特定的建模来实现的。GAN在训练中看不到这些图像。
由于所提出的技术能够在保持生成先验的同时很好地重建,我们的方法,即深度生成先验(Deep generate prior, DGP),很好地推广到各种图像恢复和操作任务,尽管我们的方法不是专门为每个任务设计的。当在任务相关的观测空间中重构被破坏的图像时,DGP倾向于恢复缺失的信息,同时保持已有的语义信息不变。如图1 (a)(b)©所示,分别很好地恢复了给定图像的颜色、缺失斑块和细节。如图1 (e)(f)所示,我们可以通过调整生成器的潜在代码或类别条件来操纵图像的内容。图1 (g)表明,通过在两个微调生成器的参数和这些图像对应的潜在代码之间插值,图像变形是可能的。据我们所知,这是第一次在ImageNet[22]这样复杂结构的图像上实现这些抖动和变形效果。我们在实验和补充材料中展示了更多有趣的例子。
本文在以下几个方面扩展了我们以前的会议版本[23]:1)它提供了更多的直观、可视化和解释,说明了我们的方法是如何工作的,以及它与以前工作的比较。2)它包含了更全面的实验结果,包括它在更多GAN架构[24],[25]上的应用,与最近的方法[26],[27]的比较,在新的数据集上的评估,以及更多的定性结果。3)提供了更多的技术细节和我们方法的分析。
2.相关工作

图2所示。利用GAN在灰度观测空间下重建灰度图像的各种方法的比较。传统的GAN反转策略(b)[15]和©[18])对现有语义产生不精确的重建。在这项工作中,我们放松了生成器,使其可以实时微调,实现更精确的重建,如(d)(e)(f),其中优化分别基于(d) VGG感知损失,(e)鉴别器特征匹配损失,(f)结合递进重建。我们强调鉴别器对于保留生成先验是很重要的,这样可以更好地恢复缺失的信息(即颜色)。建议的渐进策略消除了(e)中红框所示的“信息滞留”工件。
2.1.图像先验
图像先验在图像恢复和编辑中起着重要的作用。描述自然图像各种统计信息的先验在计算机视觉中得到了广泛的发展和应用,包括马尔可夫随机场[7]、[8]、[9]、暗通道先验[10]和全变分正则化[11]等。这些传统的手工制作的先验通常捕获某些统计数据,并服务于专门的目的。
近年来,深度图像先验(DIP)[12]的开创性工作表明,深度卷积神经网络的结构隐式捕获图像统计信息,这也可以用作恢复受损图像的先验。SinGAN[13]微调单个图像补丁上随机初始化的GAN,实现各种图像编辑或恢复效果。由于DIP和SinGAN是从零开始训练的,它们对输入图像之外的图像统计信息的访问有限,这限制了它们在图像着色等任务中的适用性。也有其他深度先验为低水平恢复任务开发,如深度去噪先验[28],[29],TNRD[30]和LCM[31],但与它们竞争不是我们的目标。相反,我们的目标是研究和开发在GAN中捕获的多用途恢复以及操作任务的先验。现有的使用预训练GAN作为图像统计来源的尝试包括[32]和[33],它们分别适用于图像处理,如编辑图像的部分区域,和图像恢复,如人脸的压缩感知和超分辨率。正如我们将在我们的实验中展示的,通过使用基于鉴别器的距离度量和渐进式微调策略,DGP可以更好地保存GAN学习到的图像统计信息,从而允许更丰富的恢复和操作效果。
最近,一种多码GAN先验[27]并行工作也通过解决GAN反演问题进行图像处理。该方法使用多个潜在码重建目标图像,并保持生成器不变,而我们的方法通过允许动态微调使生成器图像自适应。另一个并发工作PULSE[34]使用预先训练的StyleGAN实现了人脸的超分辨率。我们将展示我们的方法是任务不可知论的,并适用于更多样化的图像。
2.2.图像恢复和操作
在本文中,我们展示了将DGP应用于图像处理的多种任务的效果,包括图像着色[1]、图像修复[3]、超分辨率[4]、[5]、对抗防御[6]和语义操作[15]、[35]、[36]。为了在特定的恢复任务[1]、[2]、[3]、[4]、[5]、[6]、[37]上获得更好的性能,人们提出了许多特定任务的模型和损失函数,也有一些应用GAN,设计特定任务管道来实现[21]、[32]、[35]、[36]、[38]的各种图像处理效果,如CycleGAN[35]和StarGAN[36]。另一种工作是简单地采用GAN图像合成预训练来进行图像处理[15],[39],[40],[41],[42],[43],但仅限于GAN本身的合成图像或复杂性有限的真实图像,如人脸。
在这项工作中,我们感兴趣的是发现潜在的利用GAN先验作为一个任务不可知论的解决方案的真实复杂的图像,我们提出了几个技术来实现这一目标。此外,如图1(e)(g)所示,经过改进的重构过程,我们在ImageNet上成功实现了图像抖动和变形,而之前的方法不足以处理这些对如此复杂数据的影响。
2.3.GAN反演
利用生成先验的一种自然的方法是通过GAN反演进行图像重建。GAN反演的目的是在潜在空间中找到一个能最好地重建给定图像的向量,其中GAN生成器通常是固定的。以前的尝试包括通过梯度反向传播[16]、[17]直接优化潜在代码,利用额外的编码器将图像映射到潜在代码[44]、[45]或它们的混合方法[15]、[46]。Bau,[18]等人进一步提出在发电机的浅区块中加入小的扰动,以简化反演任务。虽然这些方法可以处理复杂性有限的数据集或GAN本身采样的合成图像,但我们在实验中经验地发现,对于复杂的真实场景,例如ImageNet[22]中的图像,它们可能会产生不精确的重建。最近,StyleGAN[24]的工作通过在松弛的中间潜在空间[26]、[46]中工作,为GAN反演提供了一种新方法,但仍观察到明显的不匹配,vanilla GAN(如BigGAN[47])的反演仍具有挑战性。在本文中,我们设计了一种更实用的方法来重建给定的图像,而不是直接使用标准的GAN反演,使用生成先验,这表明可以获得更好的重建结果。
3.方法
在讨论如何利用DGP进行图像恢复和操作之前,我们首先对DIP和GAN进行一些初步介绍。
深度图像先验
Ulyanov等人[12]表明,图像统计信息被CNN的结构隐式捕获。这些统计数据可以被视为一种图像先验,它可以被利用在各种图像恢复任务中,通过调整退化图像上随机初始化的CNN: θ※= arg minθ E(xˆ, f(z;θ)), x※= f(z;θ※),其中E是任务相关的距离度量,z是随机抽样的潜在代码,f是一个以θ为参数的CNN。xˆ和x※分别是退化的影像和恢复的影像。DIP的一个局限性是恢复过程主要依赖于输入图像中已有的统计信息,因此对于需要更一般统计信息的任务,如图像着色[1]、操作[15]等,无法使用DIP进行恢复
生成对抗网络(GANs)
GANs广泛用于自然图像[14]、[24]、[48]、[49]等复杂数据的建模。在GAN中,自然图像的底层流形是通过参数生成器G和先验潜在空间Z的组合来逼近的,因此可以通过从Z中采样潜在代码Z并将G应用为G(Z)来生成图像。GAN通过一个参数鉴别器D以一种对抗的方式联合训练G,其中D被认为可以区分生成的图像和真实的图像。虽然在提高GAN的功率方面已经做了大量的努力,但由于容量不足和模式崩溃等问题,GAN的近似流形与实际流形之间不可避免地存在差距。
3.1.深层生成图像先验
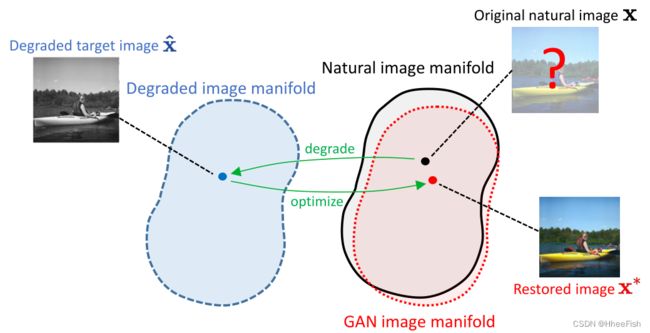
图3所示。以GAN为先决条件进行图像恢复。对于退化的目标图像,我们将GAN图像流形视为近似的自然图像流形,在观察空间中搜索与目标图像匹配的图像,即恢复图像。
假设xˆ通过xˆ = φ(x)得到,其中x是原始自然图像,φ是退化变换。例如,φ可以是将x转换为灰度图像的灰度变换。对于xˆ,许多图像恢复任务都可以看作是恢复x。一种常见的做法是学习从xˆ到x的映射,这通常需要针对不同的φs进行特定于任务的训练。或者,我们也可以使用存储在某些先验中的x统计数据,并在x空间中搜索最匹配xˆ的最优x,将xˆ视为x的部分观察值。
虽然在第二行研究中已经提出了各种各样的先验[7],[12],[13],但在本文中,我们感兴趣的是研究一种更通用的图像先验,即在大规模自然图像上训练的GAN生成器用于图像合成。具体来说,一个直接的实现是基于GAN反演的重构过程,它优化了以下目标
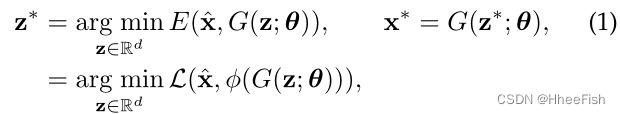
其中L是一个距离度量,如L2距离,G是一个由θ参数化的GAN生成器,并在自然图像上训练。理想情况下,如果G足够强大,可以很好地在G中捕获自然图像的数据流形,那么上述目标将在潜在空间中拖动z,并定位到最优的自然图像x※= G(z ※;θ),它包含xˆ的缺失语义,并在φ下匹配x。例如,如果φ是一个灰色变换,那么x※将是一个带有自然颜色配置的图像,其主题是φ(x※)=xˆ,如图3所示。然而,实际情况并非总是如此。
由于在Eq.(1)及其改进版本中GAN生成器是固定的,例如增加了一个额外的编码器[15],[44],这些基于标准GAN反演的重建方法都存在固有的局限性,即自然图像的近似形与实际图像之间存在差距。一方面,由于模式崩溃和容量不足等问题,GAN生成器不能完美地掌握由自然图像数据集表示的训练流形。另一方面,训练流形本身也是实际流形的近似。这两个层次的近似不可避免地会导致差距。因此,经常会检索到一个次优的x※,它经常包含与xˆ的显著不匹配,特别是当原始图像x是一个复杂的图像时,例如ImageNet[22]图像,或者位于训练流形之外的图像。如图2和已有文献[18]、[44]所示
一种松弛GAN重建配方
尽管近似流形和真实流形之间的差距,一个训练有素的GAN生成器仍然涵盖了丰富的自然图像统计。为了利用这些统计数据,同时避免上述限制,我们提出了一种宽松的GAN重建公式,允许生成器的参数θ与潜在代码z进行适度微调。θ上的这种弛豫产生了一个更新的目标:
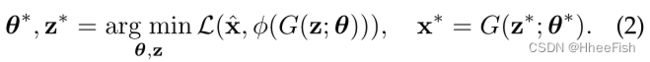
我们将这个更新的目标称为深度生成先验(Deep Generative Prior, DGP)。有了这种松弛,DGP显著提高了为xˆ找到最佳x※的机会,因为与完全捕获数据流形相比,将生成器拟合到单个图像更容易实现。注意G中隐藏的生成先验,例如,它输出真实自然图像的能力,可能会在微调过程中退化。保持生成先验的关键在于设计一个良好的距离度量L和适当的优化策略。
3.2.鉴别器引导渐进重建
图4所示。当微调生成器重建图像时,比较不同的损失类型
为了使GAN生成器适应输入图像xˆ,同时保持自然输出,在本节中,我们引入了基于距离度量的鉴别器和渐进微调策略。
鉴别器
给定一个输入图像xˆ, DGP将以初始潜在代码z0开始。在实际应用中,我们通过从潜在空间Z中随机抽取几百个候选者,并选择其对应的图像G(Z;θ)在公式(2)中使用的度量L下最类似xˆ。如图4所示,L的选择对式(2)的优化有显著影响。现有文献多采用均方误差(Mean-Squared-Error, MSE)[12]或基于AlexNet/VGGNet的知觉损失[15]、[20]为L,分别强调像素化外观和低/中级纹理。然而,我们的经验发现,在Eq.(2)中使用这些指标往往会导致优化开始时的不正确的输出,导致最后的次优结果。因此,我们建议用一个基于鉴别器的距离度量来代替它们,它测量鉴别器特征空间中的L1距离:
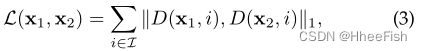
式中x1、x2为两幅图像,分别对应xˆ、φ(G(z;θ))。式中,D为与发生器耦合的鉴别器。D(x, i)返回x在D的第i块处的特征,i是已使用块的索引集。与基于AlexNet/VGGNet的感知损失相比,鉴别器D是和G一起训练的,而不是单独训练一个任务。D作为距离度量,因此不太可能破坏G的参数结构,因为它们在训练前已经很好地对齐了。此外,我们发现使用这种距离度量的优化DGP在视觉上类似于图像变形过程。例如,如图4所示,保留了船上的人,所有的中间输出都是生动的自然图像。值得再次指出的是,虽然特征匹配损失并不新鲜,但这是第一次在GAN重构过程中作为正则化器。
渐进重建

图5所示。与同时对所有参数进行微调相比,生成器的逐步重建可以更好地保持缺失语义和现有语义之间的一致性。这里中间显示的图片列表是生成器在不同微调阶段的输出。
通常,在Eq.(2)的优化过程中,我们会同时对θ的所有参数进行微调。然而,我们观察到“信息滞留”的不利影响,即缺失的语义(如颜色)不会随着现有的上下文而变化。以图4 ©为例,最左边的苹果出现时没有继承初始苹果的绿色。一个可能的原因是,在高级配置完全对齐之前,生成器G的深层块开始匹配低级纹理。为了克服这个问题,我们对一些恢复任务提出了一个渐进重建策略。
具体来说,如图5所示,我们首先对生成器的最浅层块进行微调,然后逐渐对较深的块进行继续微调,使DGP一开始就能控制全局配置,并逐渐将注意力转移到较低层次的细节。图4 (d)展示了所提出的策略,在图4 (d)中,DGP首先将苹果从1分割到2,然后将数字增加到5,最后细化苹果的细节。与非渐进策略相比,这种渐进策略更好地保留了缺失语义和现有语义之间的一致性
3.3.技术细节
架构
大部分实验采用1282和2562分辨率的BigGAN[47]架构。之所以选择BigGAN,是因为它在不同对象类别的图像生成方面表现出色。在实验中也对其他gan进行了研究。对于1282分辨率,我们使用[47]的最佳设置,它的通道乘数为96,批大小为2048。对于2562分辨率,由于GPU资源有限,通道乘法器和批大小分别设置为64和1920。我们在ImageNet训练集上训练GANs, 1282和2562版本的Inception分数分别为103.5和94.5。我们的实验是基于PyTorch[50]进行的
初始化
为了简化本文方程4的优化目标,从产生近似重构的潜在向量z开始是一个很好的做法。因此,我们使用GAN随机抽取500幅图像,并选择目标图像在鉴别器特征度量下的最近邻域作为起点。由于基于编码器的方法对于退化的输入图像往往会失败,因此在这项工作中不使用它们
注意,在BigGAN中,需要一个类条件作为输入。因此,为了重建一幅图像,需要它的类条件。这个图像分类问题可以通过训练一个相应的深度网络分类器来解决,这不是本工作的重点,因此我们假设除对抗性防御任务外,类标签是给定的。对于未给出类别的对抗性防御图像,随机抽取潜在向量z和类别条件。
微调
利用上述预训练的BigGAN和初始化的潜在向量z,我们对生成器和潜在向量进行微调,以重建目标图像。由于在微调时批大小仅为1,我们对批归一化(BN)[51]层使用跟踪的全局统计信息(即运行均值和运行方差),以防止统计估计不准确。BigGAN的判别器由多个残差块组成(1282和2562分辨率版本分别为6块和7块)。这些块的输出特性作为鉴别器损耗,如本文式(6)所示。为了防止潜在向量过分偏离先验高斯分布,我们在潜在向量z上增加了一个额外的L2损失,其损失权重为0.02。我们所有的实验都采用了ADAM优化器[52]。补充材料中提供了各种任务的详细培训训练设置。
对于修复和超分辨率,我们使用了一个加权组合鉴别器损耗和MSE损耗,因为MSE损耗有利于PSNR度量。对于超分辨率,我们研究了两种设置,一种偏向于MSE损失,另一种偏向于鉴别器损失。我们对抗性防御的定量结果是基于2562分辨率模型的,而其他任务的定量结果是基于1282分辨率模型的。
4.应用
我们首先将我们的方法与其他GAN反演方法进行重建,然后展示DGP在一些图像恢复和图像操作任务中的应用。按照第3.3节中描述的技术细节,对于大多数实验,我们采用BigGAN[47]基于鉴别器特征丢失逐步重建给定图像。对于数据集,我们使用BigGAN没有观察到的ImageNet[22]验证集。为了定量评估我们的图像恢复任务方法,我们对来自ImageNet验证集的1k张图像进行测试,其中每个类的第一张图像被收集起来组成测试集。
与其他GAN反演方法的比较
首先,我们与其他GAN反演方法[15],[16],[17],[18],[27]进行图像重建比较。如表1所示,我们的方法获得了非常高的PSNR和SSIM分数,大大超过了其他GAN反演方法。由图6可以看出,传统的GAN反演方法重构图像与目标图像存在明显的不匹配,细节甚至内容都没有对齐好。相比之下,DGP的重建误差在视觉上几乎难以察觉。在接下来的章节中,我们展示了我们的方法在各种应用中也很好地利用了生成先验。
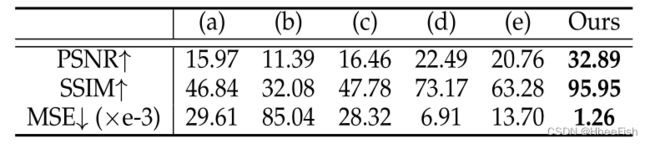
T ABLE 1与其他GAN反演方法的比较,包括(a)优化潜在码[16],[17],(b)学习编码器[15],© (a)(b)[15]的组合,(d)基于©[18]在早期阶段添加小扰动,(e)使用多个潜在码[27]。我们报道了图像重建的PSNR、SSIM和MSE。在1k ImageNet验证集上评估结果。

4.1.图像恢复
4.1.1.着色
图7所示。着色。定性比较Autocolorize[1],其他GAN反转方法[18][32],mGANprior[27]和我们的DGP
图像上色的目的是将灰度图像xˆ∈RH×W恢复为RGB通道x∈R3×H×W的彩色图像。要从彩色图像x中获得xˆ,退化变换φ是一个只保留x亮度的灰色变换。通过将这个退化变换带入公式(2),目标变成寻找与xˆ的灰度图像相同的彩色图像x※。我们使用反向传播和3.2节中基于渐进鉴别器的重构技术优化Eq.(2)。重建过程如图4(d)所示。注意,着色任务只需要预测Lab颜色空间的“ab”维度。因此,我们将x※变换到Lab空间,并采用它的“ab”维度和给定的亮度维度xˆ来生成最终的彩色图像。
图7为与Autocolorize[1]等方法的定性比较。注意,Autocolorize是直接优化的,可以从灰度图像中预测颜色,而我们的方法没有采用这种任务特定的训练。尽管如此,我们的方法在视觉上更好或可与自动着色相媲美。为了评估着色质量,我们报告了ResNet50[53]模型对着色图像的分类精度。ResNet50对Autocolorize [1], Bau等[18],Bau等[32],mGANprior[27]和我们的准确性分别为51.5%,56.2%,56.0%,7.3%和62.8%,表明DGP在这个感知度量上优于其他基线。
4.1.2.图像修复

TABLE2 图像修复。我们报告了内涂区域的PSNR和SSIM。在1k ImageNet验证集上评估结果。
图8所示。修补。与DIP、[18]、[32]和mGANprior相比,在缺失区域较大的图像修复中,所提出的DGP能够保持图像的空间一致性
图像修复的目的是恢复图像中缺失的像素。相应的退化变换是将原始图像与一个二值掩模相乘m: φ(x) = x⊙m,⊙是哈达玛积(就是两个矩阵的对应元素相乘)。与之前一样,我们将这种退化变换代入Eq.(2)中,重建缺失方框的目标图像。由于生成器的生成图像先验,缺失的部分往往会在与上下文协调的情况下得到恢复,如图8所示。相反,缺乏学习到的图像先验会导致像DIP那样混乱的修复结果。定量结果表明,DGP方法在很大程度上优于DIP等GAN反演方法,如表2所示。我们还观察到,mGANprior方法不太适合我们实现中的BigGAN模型,因为它最初是为PGGAN设计的。我们会在以后的实验中加入基于PGGAN的比较
4.1.3.超像素
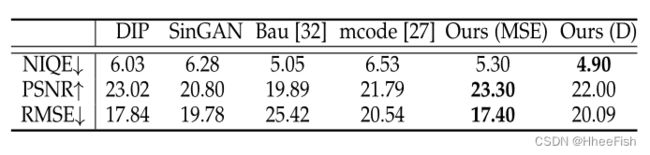
T ABLE 3超分辨率(×4)评估。我们报道了广泛使用的NIQE[54]、PSNR和RMSE评分。在1k ImageNet验证集上评估结果。(MSE)和(D)表示哪种损失DGP是偏置的。
图9所示。64 × 64尺寸图像的超分辨率(×4)。我们的方法与DIP、SinGAN、[32]和mGANprior的比较显示,其中DGP产生更清晰的超分辨率结果。

图12所示。各种图像恢复任务中DGP的重建过程
在本任务中,给出一个低分辨率图像xˆ∈R3×H×W,目的是生成对应的高分辨率图像x∈R^3×f H×f W^,其中f为上采样因子。在这种情况下,退化变换φ是对输入图像进行因子f的下采样。继DIP[12]之后,我们采用了Lanczos下采样算子。
图9和表3显示了DGP与DIP、SinGAN、Bau等[32]和mGANprior[27]的比较。我们的方法获得了比其他方法更清晰、更可靠的超分辨率结果。对于定量结果,我们可以在NIQE这样的感知质量和常用的PSNR评分之间进行权衡,在最后的微调阶段使用不同的鉴别器损失和MSE损失的组合比例。例如,当使用更高的MSE损耗时,DGP具有出色的PSNR和RMSE性能,并在所有涉及的指标上优于其他同行。通过对鉴别器丢失的偏倚,可以进一步提高感知质量NIQE。
上述图像恢复任务的重建过程如图12所示。尽管在开始时不匹配,但重建最终匹配目标图像,并恢复缺失的语义。
4.1.4.DGP的灵活性

图10所示。(a)在不同等级条件下对图像着色。(b)同时进行上色、涂漆、超分辨率(×2)。
DGP的通用范式在恢复任务中提供了更大的灵活性。例如,灰度鸟的图像在颜色空间中恢复时可能有多种可能性。由于我们的方法中使用的BigGAN是一个条件GAN,所以在恢复图像时,我们可以通过使用不同的类条件来实现着色的多样性,如图10 (a)所示。此外,我们的方法允许混合修复,即联合进行着色、涂漆和超分辨率。这可以通过使用降级变换φ(x) = φa(φb(φc(x)))的复合实现,如图10 (b)所示。
4.1.5.DGP的泛化能力
图11所示。对非ImageNet图像进行DGP评估,包括(a)“浣熊”,一个不属于ImageNet类别的类别,(b)来自Places数据集[55]的图像,©一个没有前景对象的图像,(d)一幅画,和(e)窗口。(a)©(d)(e)从互联网上刮走。
我们还在不属于ImageNet的图像上测试我们的方法。如图11所示,DGP较好地恢复了这些图像的颜色和缺失的斑块。特别的是,与DIP相比,DGP填补了缺失的补丁,以更好地与上下文对齐。这表明,DGP确实捕捉了自然图像的“空间一致性”,而不是记忆ImageNet数据集。我们进一步在用于涂装的Places[55]验证集的500张图像上评估我们的方法。我们的方法、DIP和[18]的PSNR分别为16.52、14.17和14.59,与ImageNet上的结果一致。
这种泛化能力体现在几个方面。首先,用于训练的ImageNet数据集非常多样化,涵盖了大规模的对象类别。其次,众所周知,卷积神经网络具有归纳偏差,以对图像进行泛化。第三,图像的一些统计属性,如空间相干性,在不同域的图像之间是共享的,如图11(e)所示。然而,像许多数据驱动的方法一样,DGP也会注意到在完全不同的领域的性能下降,如图11(d)所示的绘画着色。这种情况可能需要更仔细的处理,如迁移学习或领域适应。
4.1.6.消融实验
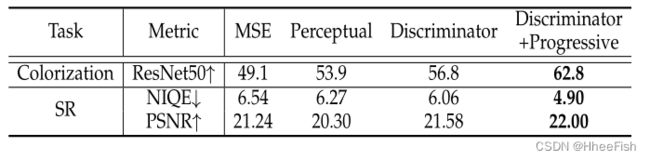
TABLE 4不同损失类型和微调策略的比较。

图14所示。不同损失类型的比较和优化技术在着色和超分辨率。
为了验证本文提出的鉴别器引导渐进重构方法的有效性,我们在表4中比较了不同的微调策略。鉴别器特征匹配损失较MSE和感知损失有明显改善,并结合递进重建进一步提高了性能。图14提供了定性比较。结果表明,渐进策略能够有效地消除“信息滞留”的假象。
4.1.7.应用于StyleGAN和PGGAN
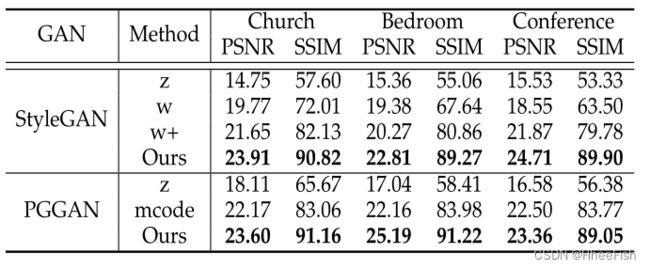
T ABLE 5与其他方法在StyleGAN和PGGAN图像修复上的比较。’ z ‘表示优化原始潜伏代码,’ w ‘表示优化StyleGAN的中间潜伏代码。’ w+ ‘是’ w ‘的放宽版本,它对应于Image2StyleGAN方法[26]。’ mcode '是使用多个潜在代码,如[27]。
图13所示。本文方法在StyleGAN和PGGAN图像修复中的应用。我们的方法显示了更好的重建在蒙面和未蒙面区域。
我们的方法并不局限于特定的GAN模型。在这里,我们将我们的方法应用于StyleGAN[24]和PGGAN[25],并与Image2StyleGAN[26]和mGANprior[27]进行比较,这分别是StyleGAN和PGGAN最先进的GAN反演方法。图像修复的结果如图13和表5所示,定量结果是根据mGANprior存储库1中的数据样本计算的。与其他基线相比,该方法在掩蔽区域和非掩蔽区域均能实现更精确的重建。结果与BigGAN的结果一致。
4.1.8.对抗的防御

表6对抗性防御评估。我们报道了ResNet50的分类精度。在1k ImageNet验证集上评估结果。

图15所示。对抗的防御。DGP能够通过重建来过滤掉敌对样品中的非自然扰动。
对抗性攻击的目的是对目标图像x[56]添加一定的扰动∆x来欺骗CNN分类器。相反,对抗性防御旨在防止模型被攻击者愚弄。具体来说,DefenseGAN[6]的工作提出了通过GAN重建被扰动的图像,将其恢复为自然图像。对于像MNIST这样的简单数据,它工作得很好,但是对于像ImageNet这样的复杂数据,由于重建不好,它就会失败。这里我们展示了在黑盒攻击设置[57]下,DGP在对抗性防御中的潜力,其中攻击者不能访问分类器和防御者。
对于对抗性攻击,退化变换为φ(x) = x +∆x,其中∆x为攻击者产生的扰动。由于计算φ(x)一般是不可微的,这里我们采用DGP方法直接重建对抗性图像xˆ。为了防止x※过拟合到xˆ,我们在MSE损失达到5e-3时停止重构。我们采用对抗变换网络攻击者[57]来生成对抗样本2。
如图15所示,生成的对抗图像包含非自然的扰动,导致对ResNet50[53]的误分类。采用DGP方法重构敌对样本后,扰动得到很大程度的缓解,从而使样本得到正确的分类。我们的方法与DefenseGAN和DIP的比较见表6。由于重建不准确,DefenseGAN产生较差的防御性能。而DGP的表现优于DIP,这得益于之前学习的图像,可以生成更自然的恢复图像。
4.2.图像处理
由于DGP能够在保持生成属性的同时实现精确的GAN重建,因此将GAN的迷人功能应用于真实图像就变得很直接,比如随机抖动、图像变形和类别转移。在本节中,我们将展示我们的方法在这些图像处理任务中的应用。
4.2.1.随机抖动
图16所示。随机抖动。重构后,我们可以在潜在码中加入随机噪声,以获得不同的随机抖动效果。

图17。比较使用SinGAN(上)和DGP(下)的随机抖动。
我们展示了DGP的随机抖动效应,并与SinGAN进行了比较。具体来说,在使用DGP重构目标图像后,我们向潜伏代码z※加入高斯噪声,观察输出如何变化。如图17所示,图像中的狼在姿态、动作和大小上都发生了变化,每一种变化看起来都像原始图像的自然偏移。然而,对于SinGAN来说,抖动的效果似乎保留了一些纹理,但失去了“狼”的概念。这是因为它不能通过只看一只狼来学习狼的有效表征。相比之下,在DGP中,生成器以一种适度的方式微调,使生成器捕获的图像流形结构得到很好的保留。因此,扰动z※对应于移动自然图像流形中的图像。
4.2.2.图像变形

图18所示。图像变形方法。为了在两幅图像之间进行插值,我们使用DGP重建图像,然后在潜在码和生成器参数之间进行插值。在生成器参数之间插值对应于创建一系列图像流形,这也产生自然图像
图19所示。图像变形。我们的方法通过插值潜在码和生成器来实现视觉上逼真的图像变形效果。

图21。比较图像变形的各种方法,包括(a)使用DIP, (b)优化预训练GAN的潜在向量z, ©(d)(e)使用© MSE损失优化z和发生器参数θ, (d)使用VGG网络感知损失,(e)鉴别器特征匹配损失。(b)重建不准确,(a)©(d)插值结果不真实。相比之下,我们在(e)中的结果要好得多。
图像变形的目的是实现从一个图像到另一个图像的视觉过渡。给定GAN发生器G和两个潜在码zA和zB,通过在zA和zB之间插入,可以很自然地在G(zA)和G(zB)之间进行变形。而在DGP情况下,重建两个目标图像xA和xB将得到两个发生器GθA和GθB,以及相应的潜在码zA和zB。受到[58]的启发,为了在xA和xB之间变形,我们对潜在码和发生器参数进行了线性插值:z = λzA +(1−λ)zB, θ = λθA +(1−λ)θB, λ∈(0,1),并生成具有新的z和θ的图像,如图18所示。由于发生器是适度微调的,θA和θB是相似的。因此,它们的插值仍然是有效的生成器参数,可以产生合理的输出图像。
如图19所示,我们的方法实现了高度逼真的图像变形效果。虽然背景复杂,但图像内容的转换却很自然。为了定量评价图像变形质量,我们对ImageNet验证集中每个类的每个连续图像对应用图像变形,并收集λ = 0.5的中间图像。对于50k个图像和1k个类,这将生成49k个图像。我们使用Inception Score (IS)[19]评价图像质量,并将DGP与采用类似网络插值策略的DIP进行比较。最后,DGP获得了令人满意的IS值59.9,而DIP无法产生有效的变形结果,导致IS值只有3.1。
我们还在图21中提供了我们的方法与DIP和其他GAN反演方法的定性比较。实验结果表明,DGP算法的性能明显优于其他算法,说明鉴别器特征匹配损失较好地保留了GAN发生器的特性。
4.2.3.类别转换

图20。类别转移。DGP允许通过改变输入类条件来编辑图像中对象的语义
在条件GAN中,类条件控制要生成的内容。因此,在通过DGP重构给定图像后,我们可以通过调整类条件来操作其内容。图1 (f)和图20给出了转移给定图像的对象类别的示例。我们的方法可以在不改变姿势、大小和图像配置的情况下将狗和鸟转移到其他各种类别。
5.分析与讨论
5.1.微调生成器的影响
图22。可视化微调发生器的效果。对于每个例子,我们都显示了重构图像G(z *;θ∗)和原发生器G(z∗;θ)。我们还展示了随机抽样潜伏码(z1, z2, z3)的结果。潜在代码与整体布局匹配,而通过微调生成器来调整细节。
虽然我们的方法允许生成器参数适应单个目标图像,但研究微调后生成器如何变化,以及这种变化如何影响其他样本,将是有趣的。给定一个目标图像x,我们显示重构图像G(z※;θ※)和使用原始发生器G(z※;θ),如图22所示。我们观察到G(z ※;θ※)和G (z※;θ)在高层概念和总体布局上是相似的(如站在雪地上的狼),但主要是在一些中低层次的位置和纹理上有所不同,如腿的确切位置、嘴是否张开、皮毛的图案等。这表明潜在代码可以匹配整体布局,但不足以对齐细节,这就是为什么我们仍然需要相应地调整生成器的权重。此外,我们进一步可视化了其他随机潜在码(图22中的z1、z2和z3)的θ和θ *的差值。有趣的是,在这些新样本中,生成器微调的影响继承了G(z※;θ※)和G (z※;θ)。例如,在第一个例子中,地面越来越亮,而背景越来越暗,狼离镜头越来越远。第二个例子,狗的鼻子和脸变轻了。这些结果证明,生成器的语义转换是可推广的,而不是特定于实例的。也就是说,通过使生成器适应目标图像,生成器学习到该图像的一些属性,这些属性也可以推广到其他样本,表明生成器的生成属性仍然保持不变。
5.2.DGP是外部学习+内部学习
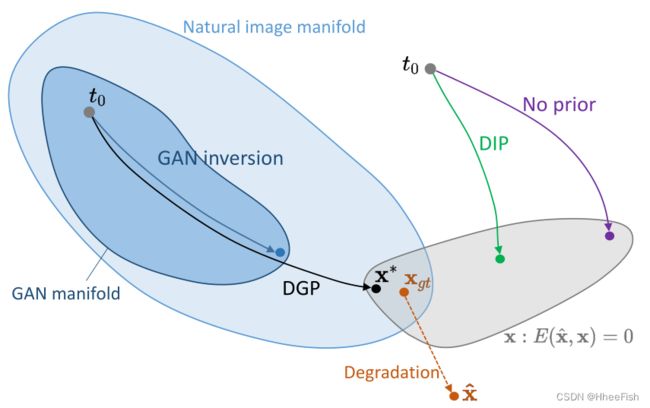
图22。可视化微调发生器的效果。对于每个例子,我们都显示了重构图像G(z *;θ∗)和原发生器G(z∗;θ)。我们还展示了随机抽样潜伏码(z1, z2, z3)的结果。潜在代码与整体布局匹配,而通过微调生成器来调整细节。
由于DIP和SinGAN只从目标图像中学习,它们属于内部学习[59]范式。相比之下,传统的GAN反演方法属于外部学习,因为它们使用固定的预训练的GAN。在DGP中,预训练的GAN也从目标图像中学习,因此可以看作是外部学习和内部学习的结合。这种策略的优势如图23所示。在许多情况下,内部学习方法可能不足以正则化自然图像流形的结果,例如,用于着色。虽然GAN反演可以使解看起来很自然,但由于GAN流形比真实图像流形小得多,往往无法与观测空间中的目标图像匹配。通过整合外部学习和内部学习,解决方案达到空间x: E(xˆ, x) = 0,而停留在或接近自然图像流形。如图11 (d)和其他实验所示,外部学习往往有助于内部学习,它们的整合表现优于任何个体。
5.3.失败案例
图24。我们的方法在着色和涂装上的失败案例。
虽然我们的方法已经显示出令人信服的结果作为一个通用的图像先验,负面的结果也观察到一些具有挑战性的情况。图24给出了一些典型的失效案例。例如,当图像中有多个物体或小面孔时,其中一些可能没有被正确还原,例如第一个例子中的一些蔬菜没有得到正确的颜色。一个可能的原因是GAN的图像流形可能会错过这些数据“模式”,这是由于众所周知的GAN[19]的“模式崩溃”问题。改善GANs[60]模式覆盖的技术可以缓解这一问题[61]。
6.结论
总而言之,我们已经展示了在大量自然图像上训练的GAN生成器可以用作通用的图像先验,即深度生成先验(DGP)。该算法利用自然图像的丰富知识,在鉴别器度量下逐步重建退化图像,从而恢复图像缺失或损坏的信息。值得注意的是,该重建策略解决了GANs精确重建图像的挑战,实现了多种视觉逼真的图像处理效果。我们的结果揭示了由GAN在图像恢复和操作中捕获的通用图像先验的潜力。
未来的工作有几个可能的方向。首先,当前基于优化的方法处理一个图像通常需要一分钟左右。我们可以通过训练一种可以将目标图像映射到潜在代码的降级不可知论编码器来加速这一过程。我们还可以学习预测生成器参数的变化,以减少微调所需的迭代次数。其次,我们也希望通过扩大GANs的模式覆盖范围来提高其在具有挑战性的案例中的表现。这可能通过扩大训练数据和GAN模型来实现,或通过利用明确激励模式寻找[60]的算法来实现,[61]。第三,我们的方法现在假设已知的退化变换用于恢复。如何将DGP扩展到退化变换没有给出的盲恢复设置,仍然是一个有趣的问题。最后,我们认为GAN的图像先验还没有得到充分的探索,可能会扩展到更广泛的任务,如图像去模糊、图像协调和图像增强。
参考文献
[1] G. Larsson, M. Maire, and G. Shakhnarovich, “Learning representations for automatic colorization,” in ECCV. Springer, 2016, pp. 577–593.
[2] R. Zhang, P . Isola, and A. A. Efros, “Colorful image colorization,” in ECCV. Springer, 2016, pp. 649–666.
[3] R. A. Yeh, C. Chen, T. Yian Lim, A. G. Schwing, M. HasegawaJohnson, and M. N. Do, “Semantic image inpainting with deep generative models,” in CVPR, 2017, pp. 5485–5493.
[4] C. Dong, C. C. Loy , K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” in TP AMI, vol. 38. IEEE, 2015, pp. 295–307.
[5] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in CVPR, 2017, pp. 4681–4690.
[6] P . Samangouei, M. Kabkab, and R. Chellappa, “Defense-gan: Protecting classifiers against adversarial attacks using generative models,” in ICLR, 2018.
[7] S. Roth and M. J. Black, “Fields of experts: A framework for learning image priors,” in CVPR, 2005, pp. 860–867.
[8] S. C. Zhu and D. Mumford, “Prior learning and gibbs reactiondiffusion,” TP AMI, vol. 19, no. 11, pp. 1236–1250, 1997.
[9] S. Geman and D. Geman, “Stochastic relaxation, gibbs distributions, and the bayesian restoration of images,” TP AMI, no. 6, pp. 721–741, 1984.
[10] K. He, J. Sun, and X. Tang, “Single image haze removal using dark channel prior,” TP AMI, vol. 33, no. 12, pp. 2341–2353, 2010.
[11] L. I. Rudin, S. Osher, and E. Fatemi, “Nonlinear total variation based noise removal algorithms,” Physica D: nonlinear phenomena, vol. 60, no. 1-4, pp. 259–268, 1992.
[12] D. Ulyanov , A. V edaldi, and V . Lempitsky , “Deep image prior,” in CVPR, 2018, pp. 9446–9454.
[13] T. R. Shaham, T. Dekel, and T. Michaeli, “Singan: Learning a generative model from a single natural image,” in ICCV, 2019, pp. 4570–4580.
[14] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley , S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in NIPS, 2014, pp. 2672–2680.
[15] J.-Y . Zhu, P . Krähenb ühl, E. Shechtman, and A. A. Efros, “Generative visual manipulation on the natural image manifold,” in ECCV, 2016.
[16] A. Creswell and A. A. Bharath, “Inverting the generator of a generative adversarial network,” in IEEE transactions on neural networks and learning systems, 2018.
[17] M. Albright and S. McCloskey , “Source generator attribution via inversion,” in CVPR Workshops, 2019.
[18] D. Bau, J.-Y . Zhu, J. Wulff, W. Peebles, H. Strobelt, B. Zhou, and A. Torralba, “Seeing what a gan cannot generate,” in ICCV, 2019, pp. 4502–4511.
[19] T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” in NIPS, 2016.
[20] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in ECCV. Springer, 2016, pp. 694–711.
[21] T.-C. Wang, M.-Y . Liu, J.-Y . Zhu, A. Tao, J. Kautz, and B. Catanzaro, “High-resolution image synthesis and semantic manipulation with conditional gans,” in CVPR, 2018.
[22] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR, 2009, pp. 248–255.
[23] X. Pan, X. Zhan, B. Dai, D. Lin, C. C. Loy , and P . Luo, “Exploiting deep generative prior for versatile image restoration and manipulation,” in ECCV, 2020.
[24] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in CVPR, 2019, pp. 4401–4410.
[25] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality , stability , and variation,” in ICLR, 2018.
[26] R. Abdal, Y . Qin, and P . Wonka, “Image2stylegan: How to embed images into the stylegan latent space?” in ICCV, 2019, pp. 4432– 4441.
[27] J. Gu, Y . Shen, and B. Zhou, “Image processing using multi-code gan prior,” CVPR, 2020.
[28] K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep cnn denoiser prior for image restoration,” in CVPR, 2017, pp. 3929– 3938.
[29] S. A. Bigdeli, M. Zwicker, P . Favaro, and M. Jin, “Deep mean-shift priors for image restoration,” in NIPS, 2017, pp. 763–772.
[30] Y . Chen and T. Pock, “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” TP AMI, vol. 39, no. 6, pp. 1256–1272, 2016.
[31] S. Athar, E. Burnaev , and V . Lempitsky , “Latent convolutional models,” in ICLR, 2018.
[32] D. Bau, H. Strobelt, W. Peebles, J. Wulff, B. Zhou, J.-Y . Zhu, and A. Torralba, “Semantic photo manipulation with a generative image prior,” ACM T ransactions on Graphics (TOG), vol. 38, no. 4, p. 59, 2019.
[33] S. A. Hussein, T. Tirer, and R. Giryes, “Image-adaptive gan based reconstruction,” arXiv preprint arXiv:1906.05284, 2019.
[34] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “Pulse: Self-supervised photo upsampling via latent space exploration of generative models,” in CVPR, 2020.
[35] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros, “Unpaired image-toimage translation using cycle-consistent adversarial networks,” in ICCV, 2017.
[36] Y . Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo, “Stargan: Unified generative adversarial networks for multi-domain imageto-image translation,” in CVPR, 2018.
[37] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Generative image inpainting with contextual attention,” in CVPR, 2018.
[38] C. Yang, Y . Shen, and B. Zhou, “Semantic hierarchy emerges in deep generative representations for scene synthesis,” arXiv preprint arXiv:1911.09267, 2019.
[39] Y . Shen, J. Gu, X. Tang, and B. Zhou, “Interpreting the latent space of gans for semantic face editing,” CVPR, 2020.
[40] R. Abdal, Y . Qin, and P . Wonka, “Image2stylegan++: How to edit the embedded images?” in CVPR, 2020.
[41] Y . Shen and B. Zhou, “Closed-form factorization of latent semantics in gans,” arXiv preprint arXiv:2007.06600, 2020.
[42] E. Hrknen, A. Hertzmann, J. Lehtinen, and S. Paris, “Ganspace: Discovering interpretable gan controls,” in NeurIPS, 2020.
[43] X. Pan, B. Dai, Z. Liu, C. C. Loy , and P . Luo, “Do 2d gans know 3d shape? unsupervised 3d shape reconstruction from 2d image gans,” 2021.
[44] J. Donahue, P . Krähenb ühl, and T. Darrell, “Adversarial feature learning,” in ICLR, 2017.
[45] M. Huh, R. Zhang, J.-Y . Zhu, S. Paris, and A. Hertzmann, “Transforming and projecting images into class-conditional generative networks,” 2020.
[46] J. Zhu, Y . Shen, D. Zhao, and B. Zhou, “In-domain gan inversion for real image editing,” 2020.
[47] A. Brock, J. Donahue, and K. Simonyan, “Large scale gan training for high fidelity natural image synthesis,” in ICLR, 2019.
[48] Y . Xiangli*, Y . Deng*, B. Dai*, C. C. Loy , and D. Lin, “Real or not real, that is the question,” in ICLR, 2020.
[49] B. Dai, S. Fidler, R. Urtasun, and D. Lin, “Towards diverse and natural image descriptions via a conditional gan,” in ICCV, 2017, pp. 2970–2979.
[50] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
[51] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML, 2015, pp. 448–456.
[52] D. P . Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
[53] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
[54] A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a completely blind image quality analyzer,” IEEE Signal processing letters, vol. 20, no. 3, pp. 209–212, 2012.
[55] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” TP AMI, vol. 40, pp. 1452–1464, 2017.
[56] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in CVPR, 2015, pp. 427–436.
[57] S. Baluja and I. Fischer, “Adversarial transformation networks: Learning to generate adversarial examples,” arXiv preprint arXiv:1703.09387, 2017.
[58] X. Wang, K. Yu, C. Dong, X. Tang, and C. C. Loy , “Deep network interpolation for continuous imagery effect transition,” in CVPR, 2019, pp. 1692–1701.
[59] A. Shocher, N. Cohen, and M. Irani, “zero-shot super-resolution using deep internal learning,” in CVPR, 2018.
[60] Q. Mao, H.-Y . Lee, H.-Y . Tseng, S. Ma, and M.-H. Yang, “Mode seeking generative adversarial networks for diverse image synthesis,” in CVPR, 2019.
[61] N. Yu, K. Li, P . Zhou, J. Malik, L. Davis, and M. Fritz, “Inclusive gan: Improving data and minority coverage in generative models,” in ECCV, 2020.