刘老师的《Pytorch深度学习实践》 第十二讲:循环神经网络(基础篇) 代码
循环神经网络适用于具有序列链接的输入的数据:金融、股市、自然语言处理

import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
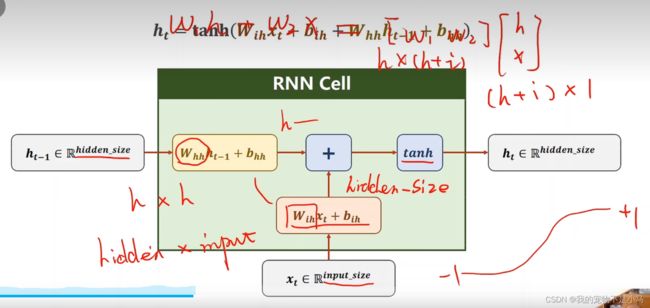
cell = torch.nn.RNNCell(input_size = input_size,hidden_size = hidden_size)
dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size) #h0初始化为全0
for idx,input in enumerate(dataset):
print('=' * 20,idx,'=' * 20)
print('Input size:',input.shape)
hidden = cell(input,hidden)
print('outputs size:',hidden.shape)
print(hidden)

import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
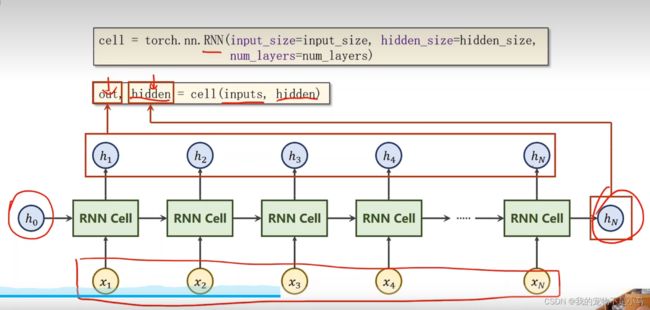
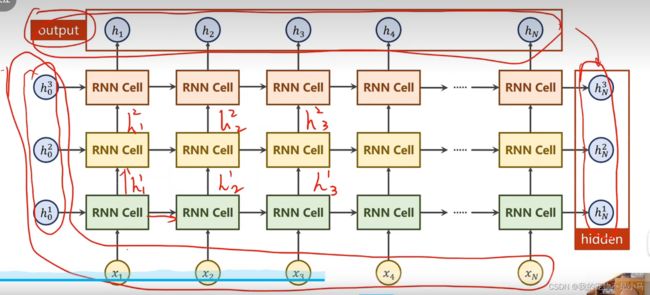
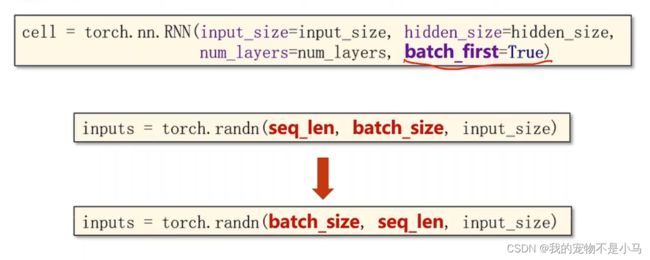
cell = torch.nn.RNN(input_size = input_size,hidden_size = hidden_size,num_layers = num_layers)
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size) #h0初始化为全0
out,hidden = cell(inputs,hidden)
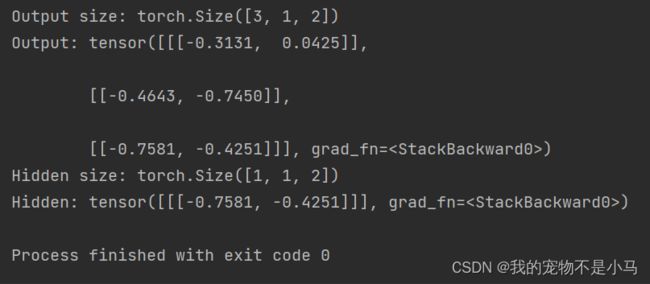
print('Output size:',out.shape)
print('Output:',out)
print('Hidden size:',hidden.shape)
print('Hidden:',hidden)
文本转为向量:


import torch
batch_size = 1
input_size = 4
hidden_size = 4
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1)
class Model(torch.nn.Module):
def __init__ (self,input_size,hidden_size,batch_size):
super(Model,self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size = self.input_size,hidden_size = self.hidden_size)
def forward(self,input,hidden):
hidden = self.rnncell(input,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net = Model(input_size,hidden_size,batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string:',end = '')
for input,label in zip(inputs,labels): #shape of inputs:(seqLen,batchSize,inputSize),input:(batchSize,inputSize),labels:(seqSize,1),label:(1)
hidden = net(input,hidden)
loss += criterion(hidden,label) #每一步损失的累加
_,idx = hidden.max(dim = 1)
print(idx2char[idx.item()],end = '')
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss = %.4f' % (epoch + 1,loss.item()))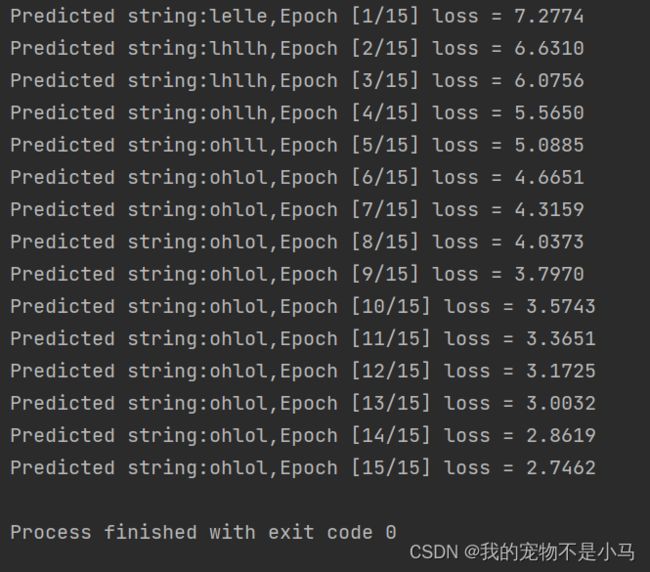
原文中lr为0.1,未训练出ohlol,改为0.05后解决
RNN
import torch
num_layers = 1
batch_size = 1
input_size = 4
hidden_size = 4
seq_len = 5
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__ (self,input_size,hidden_size,batch_size,num_layers = 1):
super(Model,self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size = self.input_size,hidden_size = self.hidden_size,num_layers = num_layers)
def forward(self,input):
hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
out,_ = self.rnn(input,hidden)
return out.view(-1,self.hidden_size)
net = Model(input_size,hidden_size,batch_size,num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
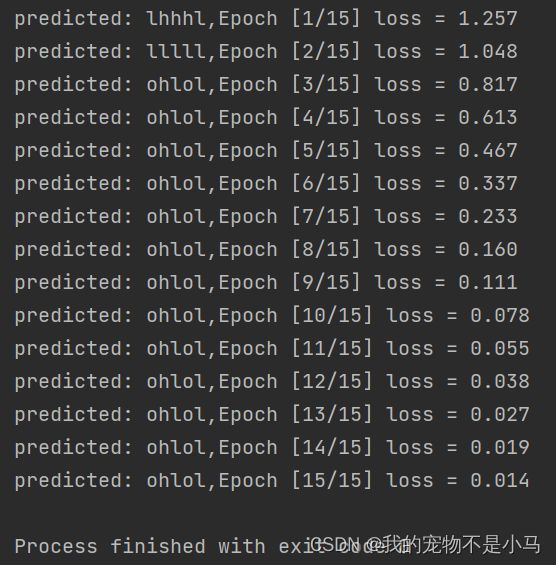
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx = outputs.max(dim = 1)
idx = idx.data.numpy()
print('predicted:',''.join([idx2char[x] for x in idx]),end = '')
print(',Epoch [%d/15] loss = %.3f' % (epoch + 1,loss.item()))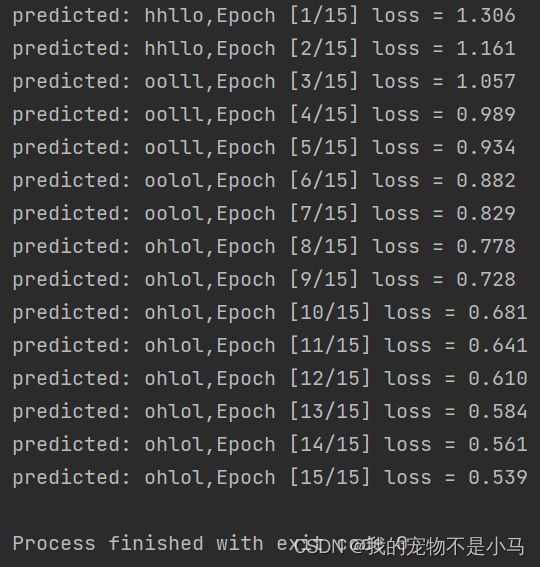
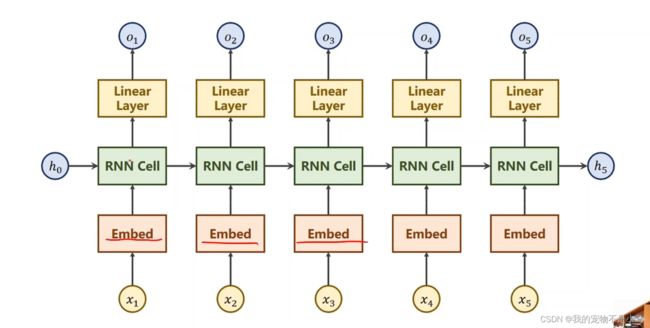
import torch
num_class = 4
num_layers = 2
batch_size = 1
input_size = 4
hidden_size = 8
seq_len = 5
embedding_size = 10
idx2char = ['e','h','l','o']
x_data = [[1,0,2,2,3]]
y_data = [3,1,2,3,2]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__ (self):
super(Model,self).__init__()
self.emb = torch.nn.Embedding(input_size,embedding_size)
self.rnn = torch.nn.RNN(input_size = embedding_size,hidden_size = hidden_size,num_layers = num_layers,batch_first = True)
self.fc = torch.nn.Linear(hidden_size,num_class)
def forward(self,x):
hidden = torch.zeros(num_layers,x.size(0),hidden_size)
x = self.emb(x)
x,_ = self.rnn(x,hidden)
x = self.fc(x)
return x.view(-1,num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr = 0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_,idx = outputs.max(dim = 1)
idx = idx.data.numpy()
print('predicted:',''.join([idx2char[x] for x in idx]),end = '')
print(',Epoch [%d/15] loss = %.3f' % (epoch + 1,loss.item()))