Kubernetes云原生开源分布式存储介绍

Kubernetes存储介绍

为何引入PV、PVC以及StorageClass?
熟悉Kubernetes的都对PV、PVC以及StorageClass不陌生,我们经常用到,因此这里不再详细介绍PV、PVC以及StorageClass的用法,仅简单聊聊为什么需要引入这三个概念。
我们看下最早期Pod使用Volume的写法:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- image: ...
name: test-pod
volumeMounts:
- mountPath: /data
name: data
volumes:
- name: data
capacity:
storage: 10Gi
cephfs:
monitors:
- 172.16.0.1:6789
- 172.16.0.2:6789
- 172.16.0.3:6789
path: /opt/eshop_dir/eshop
user: admin
secretRef:
name: ceph-secret
这种方式至少存在两个问题:
Pod声明与底层存储耦合在一起,每次声明Volume都需要配置存储类型以及该存储插件的一堆配置,如果是第三方存储,配置会非常复杂。
开发人员的需求可能只是需要一个20GB的卷,这种方式却不得不强制要求开发人员了解底层存储类型和配置。
比如前面的例子中每次声明Pod都需要配置Ceph集群的mon地址以及secret,特别麻烦。
于是引入了PV(Persistent Volume),PV其实就是把Volume的配置声明部分从Pod中分离出来:
apiVersion: v1
kind: PersistentVolume
metadata:
name: cephfs
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
cephfs:
monitors:
- 172.16.0.1:6789
- 172.16.0.2:6789
- 172.16.0.3:6789
path: /opt/eshop_dir/eshop
user: admin
secretRef:
name: ceph-secret
我们发现PV的spec部分几乎和前面Pod的Volume定义部分是一样的。
有了PV,在Pod中就可以不用再定义Volume的配置了,直接引用即可,Volume定义和Pod松耦合了。
但是这没有解决Volume定义的第二个问题,存储系统通常由运维人员管理,开发人员并不知道底层存储配置,也就很难去定义好PV。
为了解决这个问题,引入了PVC(Persistent Volume Claim),声明与消费分离,开发与运维责任分离。
运维人员负责存储管理,可以事先根据存储配置定义好PV,而开发人员无需了解底层存储配置,只需要通过PVC声明需要的存储类型、大小、访问模式等需求即可,然后就可以在Pod中引用PVC,完全不用关心底层存储细节。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cephfs
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 8Gi
PVC会根据声明的大小、存储类型(如storageClassName)、accessModes等关键字查找PV,如果找到了匹配的PV,则会与之关联。
通过PV以及PVC,开发人员的问题是解决了,但没有解决运维人员的问题。运维人员需要维护一堆PV列表和配置,如果PV不够用需要手动创建新的PV,PV空闲了还需要手动去回收,管理效率太低了。
于是又引入了StorageClass,StorageClass类似声明了一个非常大的存储池,其中一个最重要的参数是provisioner,这个provisioner声明了谁来提供存储源,我们熟悉的OpenStack Cinder、Ceph、AWS EBS等都是provisioner。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: aws-gp2
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
fsType: ext4
有了StorageClass后,Kubernetes会根据开发人员定义的PVC中声明的StorageClassName以及大小等需求自动创建PV,即Dynamic Provisioning。
而运维人员只需要声明好StorageClass以及Quota配额,无需维护PV。
通过PV、PVC以及StorageClass,开发和运维的工作彻底解放了。
Kubernetes存储方案发展过程概述
我们知道Kubernetes存储最开始是通过Volume Plugin实现集成外部存储系统,即不同的存储系统对应不同的Volume Plugin。
Volume Plugin实现代码全都放在了Kubernetes主干代码中(in-tree),也就是说这些插件与核心Kubernetes二进制文件一起链接、编译、构建和发布。
这种方案至少存在如下几个问题:
在Kubernetes中添加新存储系统支持需要在核心Kubernetes增加插件代码,随着存储插件越来越多,Kubernetes代码也会变得越来越庞大。
Kubernetes与具体的存储Plugin耦合在一起,一旦存储接口发生任何变化都需要重新修改Plugin代码,也就是说不得不修改Kubernetes代码,这会导致Kubernetes代码维护越来越困难。
如果Plugin有bug或者存储系统故障导致crash,可能导致整个Kubernetes集群整体crash。
这些插件运行时无法做权限管控,具有Kubernetes所有组件的所有权限,存在一定的安全风险。
插件的实现必须通过Golang语言编写并与Kubernetes一起开源,可能对一些厂商不利。
因此从1.8开始,Kubernetes停止往Kubernetes代码中增加新的存储支持, 并推出了一种新的插件形式支持外部存储系统,即FlexVolume,不过FlexVolume其实在1.2就提出了。
FlexVolume类似于CNI插件,通过外部脚本集成外部存储接口,这些脚本默认放在/usr/libexec/kubernetes/kubelet-plugins/volume/exec/,需要安装到所有Node节点上。
这样每个存储插件只需要通过外部脚本(out-of-tree)实现attach、detach、mount、umount等接口即可集成第三方存储,不需要动Kubernetes源码,可以参考官方的一个LVM FlexVolume Demo[1]。
但是这种方法也有问题:
脚本文件放在host主机上,因此驱动不得不通过访问宿主机的根文件系统去运行脚本。
这些插件如果还有第三方程序依赖或者OS兼容性要求,还需要在所有的Node节点安装这些依赖并解决兼容问题。
因此这种方式虽然解决了in-tree的问题,但显然这种方式用起来不太优雅,不太原生。
因此Kubernetes从1.9开始又引入了Container Storage Interface(CSI)容器存储接口,并于1.13版本正式GA。
CSI的实现方案和CRI类似通过gRPC与Volume Driver进行通信,存储厂商需要实现三个服务接口Identity Service、Controller Service、Node Service:
Identity Service用于返回一些插件信息;
Controller Service实现Volume的CURD操作;
Node Service运行在所有的Node节点,用于实现把Volume挂载在当前Node节点的指定目录,该服务会监听一个Socket,controller通过这个Socket进行通信,可以参考官方提供的样例CSI Hostpath driver Sample[2]。
更多有关CSI介绍可以参考官方的设计文档CSI Volume Plugins in Kubernetes Design Doc[3]。
通过CSI基本解决了如上in-tree以及FlexVolume的大多数问题,未来Kubernetes会把in-tree的存储插件都迁移到CSI。
当然Flex Volume Plugin也会与新的CSI Volume Plugin并存以便兼容现有的第三方FlexVolume存储插件。
为什么需要云原生分布式存储
通过CSI接口或者Flex Volume Plugin解决了Kubernetes集成外部存储的问题,目前Kubernetes已经能够支持非常多的外部存储系统了,如NFS、GlusterFS、Ceph、OpenStack Cinder等,这些存储系统目前主流的部署方式还是运行在Kubernetes集群之外单独部署和维护,这不符合All In Kubernetes的原则。
如果已经有分布式存储系统还好,可以直接对接。但如果没有现成分布式存储,则不得不单独部署一套分布式存储。
很多分布式存储部署相对还是比较复杂的,比如Ceph。而Kubernetes天生就具有快速部署和编排应用的能力,如果能把分布式存储的部署也通过Kubernetes编排管理起来,则显然能够大大降低分布式存储的部署和维护成本,甚至可以使用一条apply命令就可以轻松部署一个Ceph集群。
这主要有两种实现思路:
第一种思路就是重新针对云原生平台设计一个分布式存储,这个分布式存储系统组件是微服务化的,能够复用Kubernetes的调度、故障恢复和编排等能力,如后面要介绍的Longhorn、OpenEBS。
另一种思路就是设计微服务组件把已有的分布式存储系统包装管理起来,使原来的分布式存储可以适配运行在Kubernetes平台上,实现通过Kubernetes管理原有的分布式存储系统,如后面要介绍的Rook。
Container Attached Storage,容器存储的未来?
我们知道组成云计算的三大基石为计算、存储和网络,Kubernetes计算(Runtime)、存储(PV/PVC)和网络(Subnet/DNS/Service/Ingress)的设计都是开放的,可以集成不同的方案,比如网络通过CNI接口支持集成Flannel、Calico等网络方案,运行时(Runtime)通过CRI支持Docker、Rkt、Kata等运行时方案,存储通过Volume Plugin支持集成如AWS EBS、Ceph、OpenStack Cinder等存储系统。
但是我们发现目前主流的方案中存储与计算、网络稍有不同,计算和网络都是以微服务的形式通过Kubernetes统一编排管理的,即Kubernetes既是计算和网络的消费者,同时也是计算和网络的编排者和管理者。
而存储则不一样,虽然Kubernetes已经设计了PV/PVC机制来管理外部存储,但只是弄了一个标准接口集成,存储本身还是通过独立的存储系统来管理,Kubernetes根本不知道底层存储是如何编排和调度的。
社区认为既然计算和存储都由我Kubernetes统一编排了,是不是存储也考虑下?
于是社区提出了Container Attached Storage(CAS)理念,这个理念的目标就是利用Kubernetes来编排存储,从而实现我Kubernetes编排一切,这里的一切包括计算、存储、网络,当然更高一层的还包括应用、服务、软件等。
这个方案如何实现呢?CAS提出如下方案:
每个Volume都由一个轻量级的Controller来管理,这个Controller可以是一个单独的Pod。
这个Controller与使用该Volume的应用Pod在同一个Node(Sidecar模式)。
不同的Volume的数据使用多个独立的Controller Pod进行管理。

CAS
由于Pod是通过Kubernetes编排与调度的,因此毫无疑问通过这种形式其实就实现了Kubernetes编排和调度存储: )
Kubernetes毕竟是目前主流趋势,通过Kubernetes编排和管理存储也必然是一种发展趋势,目前OpenEBS就是CAS的一种开源实现,商业存储如PortWorx、StorageOS也是基于CAS模式的。
更多关于CAS的可以参考CNCF官宣文章Container Attached Storage: A Primer[4]。
简单好用的Longhorn
Longhorn简介
Longhorn在我之前的文章《轻量级Kubernetes k3s初探》已经简单介绍过,最初由Rancher公司开发并贡献给社区,专门针对Kubernetes设计开发的云原生分布式块存储系统,因此和Kubernetes契合度很高,主要体现在两个方面,一是它本身就直接运行在Kubernetes平台上,通过容器和微服务的形式运行;其二是能很好的与PV/PVC结合。
与其他分布式存储系统最大的不同点是,Longhorn并没有设计一个非常复杂的控制器来管理海量的Volume数据卷,而是将控制器拆分成一个个非常轻量级的微控制器,这些微控制器能够通过Kubernetes、Mesos等平台进行编排与调度。
每个微控制器只管理一个Volume,换句话说,一个Volume一个控制器,每个Volume都有自己的控制器,这种基于微服务的设计使每个volume相对独立,控制器升级时可以先选择一部分卷进行操作,如果升级出现问题,可以快速选择回滚到旧版本,升级过程中只可能会影响正在升级的volume,而不会导致其他volume IO中断。
Longhorn的实现和CAS的设计理念基本是一致的,相比Ceph来说会简单很多,而又具备分布式块存储系统的一些基本功能:
支持多副本,不存在单点故障;
支持增量快照;
支持备份到其他外部存储系统中,比如S3;
精简配置(thin provisioning);
……
我觉得Longhorn还有一个特别好的功能是内置了一个Web UI,通过UI能够很方便的管理Node、Volume以及Backup,不得不说Longhorn真是麻雀虽小五脏俱全。
根据官方的说法,Longhorn并不是为了取代其他分布式块存储系统,而是为了设计一个更简单的适合容器环境的块存储系统,其他分布式存储有的一些高级功能Longhorn并没有实现,比如去重(Deduplication)、压缩、分块、多路径等。
Longhorn存储管理机制比较简单,当在Longhorn中Node节点增加物理存储时,其本质就是把Node对应的路径通过HostPath挂载到Pod中,我们可以查看该路径的目录结构,在replicas目录中一个Volume一个子目录,文件内容如下:
# find replicas/int32bit-volume-3-ab6717d6/
replicas/int32bit-volume-3-ab6717d6/
replicas/int32bit-volume-3-ab6717d6/volume.meta
replicas/int32bit-volume-3-ab6717d6/volume-head-000.img
replicas/int32bit-volume-3-ab6717d6/revision.counter
replicas/int32bit-volume-3-ab6717d6/volume-head-000.img.meta
其中int32bibt-volume-3是Volume名称,ab6717d6对应副本名称,子目录中包含一些Volume的metadata以及img文件,而img文件其实就是一个raw格式文件:
# qemu-img info volume-head-000.img
image: volume-head-000.img
file format: raw
virtual size: 20G (21474836480 bytes)
disk size: 383M
raw格式其实就是Linux Sparse稀疏文件,由于单个文件大小受文件系统和分区限制,因此Longhorn volume会受单个磁盘的大小和性能的限制,不过我觉得Kubernetes Pod其实也很少需要用到特别大的Volume。
更多关于Longhorn的技术实现原理可以参考官宣文章Announcing Longhorn: an open source project for microservices-based distributed block storage[5]。
Longhorn部署
Longhorn部署也非常简单,只需要一个kubectl apply命令:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
创建完后就可以通过Service或者Ingress访问它的UI了:

Longhorn WebUI
在Node页面可以管理节点以及物理存储,Volume页面可以管理所有的Volumes,Backup可以查看备份等。
Volume详情页面可以查看Volume的挂载情况、副本位置、对应的PV/PVC以及快照链等:

Longhorn Volume
除此之外,Longhorn还支持创建备份计划,可以通过cron指定时间点或者定时对Volume进行快照或者备份到S3中。

Longhorn backup
Kubernetes集成Longhorn存储
Longhorn既支持FlexVolume也支持CSI接口,安装时会自动根据Kubernetes版本选择FlexVolume或者CSI。
Kubernetes集成Longhorn,根据前面对StorageClass的介绍,我们需要先安装Longhorn StorageClass:
kubectl create -f \
https://raw.githubusercontent.com/longhorn/longhorn/master/examples/storageclass.yaml
声明一个20Gi的PVC:
# kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-volv-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 2Gi
创建Pod并使用新创建的PVC:
# kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: test-volume-longhorn
spec:
containers:
- name: test-volume-longhorn
image: jocatalin/kubernetes-bootcamp:v1
volumeMounts:
- name: volv
mountPath: /data
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-volv-pvc
通过Longhorn Dashboard查看Volume状态已经挂载到Pod中:

Longhorn PVC
Longhorn Volume不仅可以通过PV形式挂载到Kubernetes容器,还可以直接通过ISCSI接口挂载到Node节点上:

longhorn_attach_to_host
此时可以通过lsblk在OS查看到块存储设备,通过iscsiadm命令可以查看Node节点连接的设备会话:
# lsblk -S
NAME HCTL TYPE VENDOR MODEL REV TRAN
sda 0:0:0:1 disk IET VIRTUAL-DISK 0001 iscsi
# iscsiadm -m session
tcp: [3] 10.244.0.50:3260,1 iqn.2019-10.io.longhorn:int32bit-volume-1 (non-flash)
CAS开源实现OpenEBS
OpenEBS简介
OpenEBS[6]是MayaData(之前叫CloudByte)公司开源的云原生容器存储项目,命名上可能参考了AWS EBS(Elastic Block Storage)。
OpenEBS也是目前Container Attached Storage的一种开源实现方案,因此它直接运行在Kubernetes平台上,通过Kubernetes平台进行编排与调度。
OpenEBS支持如下三种存储类型,分别为cStor、Jiva以及LocalPV。
Jiva
后端实现其实就是前面介绍的Longhorn,也就是使用了raw格式sparse稀疏文件作为虚拟磁盘实现容器Volume,这个和虚拟机的本地虚拟磁盘实现类似,可以通过qemu-img info查看Volume分配的虚拟大小以及实际使用的空间,稀疏文件默认路径为/var/openebs,所以Volume的容量总大小取决于这个路径挂载的文件系统大小。
实现上使用了Longhorn早期版本设计,即一个3副本的Volume会有4个Pod控制器管理,一个是主控制器,三个副本控制器,其中主控制器运行了iSCSI Target服务,通过Service暴露ISCSI 3260端口,主控制器会把IO复制到所有副本的控制器。

OpenEBS Jiva
cStor
这是OpenEBS最推荐的存储类型,测试最完备,经过了生产部署考验,支持多副本、快照、克隆、精简配置(thin provisioning)、数据强一致性等高级特性。
和Jiva不一样的是,cStor使用了类似ZFS或者LVM的Pool的概念,BlockDevices就相当于LVM的PV,而Pool则类似LVM的VG概念,Volume类似LVM的LV,其中BlockDevice对应物理上的一块磁盘或者一个分区,多个BlockDevices组成Pool,这些BlockDevices如何存储落盘取决于Pool策略,cStor支持的Pool策略包括striped、mirrored、raidz、raidz2,这些概念都不陌生。

cStor Pool
Pool是一个单Node节点层面的概念而不是分布式的,创建一个cStor Pool实际上会在每个Node节点创建相同策略的Pool实例,因此即使使用striped策略,数据打散后也只是存储在本地的多块磁盘,不会跨节点存储,当然volume副本是跨节点的。
OpenEBS通过ISCSI接口实现Volume的挂载,每当创建一个cStor Volume,OpenEBS就会创建一个新的cStor target Pod,cStor target会创建对应的LUN设备。
cStor target除了负责LUN设备管理,还负责副本之间的数据同步,每当用户有数据写入时,cStor target会把数据拷贝到其他所有副本中去。
比如假设创建了一个三副本的cStor PV,当用户写入数据时,cStor target会同时往三个副本写入数据,只有等三个副本都写成功后,才会响应用户,因此显然OpenEBS是一个强一致性分布式存储系统。

cstor-for-deployment
不过这也是cStor性能比较差的原因之一,它不像Ceph一样一个RBD image会分块存储在多个节点多个硬盘的多个OSD上,可以避免单节点的IO性能瓶颈问题。
LocalPV
LocalPV就是直接把本地磁盘(Local Disk)挂载到容器,这个其实就是Kubernetes LocalPV的增强版,因为直接读取本地磁盘,相对iSCSI需要走网络IO来说性能肯定是最好的,不过缺点是没有多副本、快照、克隆等高级特性。
OpenEBS部署
直接使用kubectl安装:
kubectl apply -f \
https://openebs.github.io/charts/openebs-operator-1.8.0.yaml
如上会把所有的/dev下的块设备都当作OpenEBS的block devices,建议修改下openebs-ndm-configConfigmap,通过path-filter指定分给OpenEBS的物理设备。
正如LVM有了PV还需要创建VG一样,cStor需要手动创建一个Pool:
apiVersion: openebs.io/v1alpha1
kind: StoragePoolClaim
metadata:
name: cstor-disk-pool
annotations:
cas.openebs.io/config: |
- name: PoolResourceRequests
value: |-
memory: 2Gi
- name: PoolResourceLimits
value: |-
memory: 4Gi
spec:
name: cstor-disk-pool
type: disk
poolSpec:
poolType: striped
blockDevices:
blockDeviceList:
- blockdevice-ad96d141bd7804554d431cb13e7e61bc
- blockdevice-b14cd44f3bfcbd94d3e0bda065f6e2bd
- blockdevice-e3a5cf960033d7a96fdee46a5baee9d2
其中poolType选择Pool策略,如果使用mirror需要注意每个Node的磁盘数量必须是偶数,这里我们选择striped,即数据会打散分布存储在Node Pool的所有磁盘。
blockDevices选择要放入该Pool的物理设备,这里作为测试每个Node节点只有一块盘,实际生产时应该至少使用3块盘以上,使用mirror则至少两块盘以上。
可以通过如下命令查看可用的blockDevices:
# kubectl get blockdevices --all-namespaces -o wide
NAMESPACE NAME NODENAME PATH SIZE CLAIMSTATE STATUS AGE
openebs blockdevice-ad96d141bd7804554d431cb13e7e61bc ip-192-168-193-6.cn-northwest-1.compute.internal /dev/nvme0n1 107374182400 Claimed Active 4d17h
openebs blockdevice-b14cd44f3bfcbd94d3e0bda065f6e2bd ip-192-168-193-172.cn-northwest-1.compute.internal /dev/nvme0n1 107374182400 Claimed Active 4d17h
openebs blockdevice-e3a5cf960033d7a96fdee46a5baee9d2 ip-192-168-193-194.cn-northwest-1.compute.internal /dev/nvme0n1 107374182400 Claimed Active 4d17h
其中Claimed表示已分配,PATH对应物理设备路径。
使用CR cstorpools可以查看Pool:
# kubectl get cstorpools.openebs.io --all-namespaces
NAME ALLOCATED FREE CAPACITY STATUS READONLY TYPE AGE
cstor-disk-pool-9tey 272K 99.5G 99.5G Healthy false striped 4m50s
cstor-disk-pool-lzg4 272K 99.5G 99.5G Healthy false striped 4m50s
cstor-disk-pool-yme1 272K 99.5G 99.5G Healthy false striped 4m50s
可见OpenEBS会在所有的Node节点创建Pool实例,与前面的解释一致。
Kubernetes集成OpenEBS块存储
本小节主要以cStor为例演示下如何使用OpenEBS,前面已经创建了cStor Pool,接下来只需要再创建对应的StorageClass即可:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cstor-disk-pool
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk-pool"
- name: ReplicaCount
value: "3"
provisioner: openebs.io/provisioner-iscsi
其中StoragePoolClaim指定使用的Pool名称,ReplicaCount指定Volume的副本数。
创建完StorageClass后就可以创建PVC了:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-openebs-cstor
namespace: default
spec:
storageClassName: cstor-disk-pool
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-openebs-cstor
namespace: default
spec:
containers:
- name: test-openebs-cstor
image: jocatalin/kubernetes-bootcamp:v1
volumeMounts:
- name: test-openebs-cstor
mountPath: /data
volumes:
- name: test-openebs-cstor
persistentVolumeClaim:
claimName: test-openebs-cstor
每创建一个PV,OpenEBS就会创建一个Target Pod,这个Pod通过一个单副本的Deployment管理,这个Pod会创建一个LUN并export,通过Service暴露iSCSI端口:
# kubectl get pvc --all-namespaces
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
default test-openebs-cstor Bound pvc-6673e311-0db1-4f15-b480-aafb16a72d46 50Gi RWO cstor-disk-pool 31m
# kubectl get pod -n openebs | grep pvc-6673e311-0db1-4f15-b480-aafb16a72d46
pvc-6673e311-0db1-4f15-b480-aafb16a72d46-target-55bb467574mf7hf 3/3 Running 1 31m
# kubectl get deployments.apps -n openebs | grep pvc-6673e311-0db1-4f15-b480-aafb16a72d46
pvc-6673e311-0db1-4f15-b480-aafb16a72d46-target 1/1 1 1 32m
# kubectl get svc -n openebs | grep pvc-6673e311-0db1-4f15-b480-aafb16a72d46
pvc-6673e311-0db1-4f15-b480-aafb16a72d46 ClusterIP 10.96.24.35 3260/TCP,7777/TCP,6060/TCP,9500/TCP 32m
毫无疑问,OpenEBS的所有服务运行、存储调度、服务之间通信以及存储的管理都是通过Kubernetes完成的,它就像集成到Kubernetes的一个内嵌功能一样,一旦配置完成,基本不需要额外的运维和管理。
一个Volume对应一个Target Pod,这完全遵循了CAS的设计理念。
让分布式存储简化管理的Rook
Rook简介
Rook也是目前开源中比较流行的云原生存储编排系统,它和之前介绍的LongHorn和OpenEBS不一样,它的目标并不是重新造轮子实现一个全新的存储系统,最开始Rook项目仅仅专注于如何实现把Ceph运行在Kubernetes平台上。
随着项目的发展,格局也慢慢变大,仅仅把Ceph搞定是不够的,项目当前的目标是将外部已有的分布式存储系统在云原生平台托管运行起来,借助云原生平台具有的自动化调度、故障恢复、弹性扩展等能力实现外部存储系统的自动管理、自动弹性扩展以及自动故障修复。
按照官方的说法,Rook要把原来需要对分布式存储系统手动做的一些运维工作借助云原生平台能力(如Kubernetes)实现自动化,这些运维工作包括部署、初始化、配置、扩展、升级、迁移、灾难恢复、监控以及资源管理等,这种自动化甚至不需要人去手动触发,而是云原生平台自动触发的,因此叫做self-managing,真正实现NoOpts。
比如集群增加一块磁盘,Rook能自动初始化为一个OSD,并自动加入到合适的故障域中,这个OSD在Kubernetes中是以Pod的形式运行的。
目前除了能支持编排管理Ceph集群,还支持:
EdgeFS
CockroachDB
Cassandra
NFS
Yugabyte DB
不同的存储通过不同的Operator实现,但使用起来基本一致,Rook屏蔽了底层存储系统的差异。
Rook部署
安装部署Rook非常简单,以Ceph为例,只需要安装对应的Operator即可:
git clone --single-branch --branch release-1.3 \
https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph
kubectl create -f common.yaml
kubectl create -f operator.yaml
kubectl create -f cluster.yaml
通过Rook管理Ceph,理论上不需要直接通过Ceph Client命令行接口与Ceph集群直接交互。不过如果有需要,可以通过如下方式进行简单配置:
kubectl create -f toolbox.yaml # 安装Ceph client工具
export CEPH_TOOL_POD=$(kubectl -n rook-ceph \
get pod -l "app=rook-ceph-tools" \
-o jsonpath='{.items[0].metadata.name}')
alias ceph="kubectl -n rook-ceph exec -it $CEPH_TOOL_POD -- ceph"
alias rbd="kubectl -n rook-ceph exec -it $CEPH_TOOL_POD -- rbd"
使用Ceph命令查看集群状态:
# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
TOTAL 0 B 0 B 0 B 0 B 0 B 0 B 0
MIN/MAX VAR: -/- STDDEV: 0
我们发现Ceph集群是空的,没有任何OSD,这是因为我的机器没有裸磁盘(即没有安装任何文件系统的分区)。
DeamonSet rook-discover会定时监视Node节点是否有新的磁盘,一旦有新的磁盘,就会自动启动一个Job进行OSD初始化。如下是Node节点增加磁盘的结果:

ceph osd prepare
如果运行在公有云上,Rook还会根据节点的Region以及AZ自动放到不同的故障域,不需要手动调整crushmap:
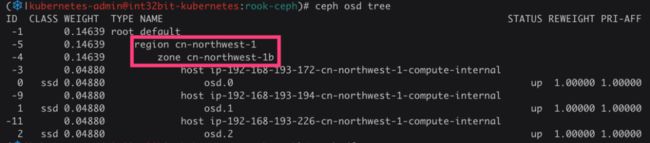
ceph osd tree
如图,由于我的测试集群部署在AWS上,并且三个节点都放在了一个AZ上,因此三个OSD都在zone cn-northwest-1b中,实际生产环境不推荐这么做。
我们发现整个磁盘以及OSD初始化过程,无需人工干预,这就是所谓的self-manage。
想想我们平时在做Ceph集群扩容,从准备磁盘到crushmap配置,没有半个小时是搞不定的,而通过Rook我们几乎不用操心OSD是如何加到集群的。
Rook默认还会安装Ceph Dashboard,可以通过Kubernetes Service rook-ceph-mgr-dashboard进行访问,admin的密码保存在secret rook-ceph-dashboard-password中,可通过如下命令获取:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password \
-o jsonpath="{['data']['password']}" \
| base64 --decode && echo
Ceph Dashboard
Rook会把Ceph集群的监控导出,便于与Prometheus集成。
Kubernetes集成Rook Ceph存储
Longhorn、OpenEBS都只提供了块存储接口,意味着一个Volume只能挂载到一个Pod,而Rook Ceph则同时提供了块存储、共享文件系统存储以及对象存储接口,其中共享文件系统存储以及对象存储都能实现跨节点的多个Pod共享。
接下来我们通过例子演示下如何使用。
块存储
Ceph通过RBD实现块存储,首先我们在Kubernetes上安装StorageClass:
kubectl create -f \
cluster/examples/kubernetes/ceph/csi/rbd/storageclass.yaml
我们首先需要创建一个Ceph Pool,当然我们可以通过ceph osd pool create命令手动创建,但这样体现不了self-managing,我们应该屏蔽Ceph集群接口,直接使用Kubernetes CRD进行声明:
# kubectl apply -f -
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
通过如上方式,我们基本不需要使用Ceph命令,即创建了一个3副本的rbd pool。
可以通过kubectl get cephblockpools查看Pool列表:
# kubectl get cephblockpools
NAME AGE
replicapool 107s
创建一个Pod使用CephBlockPool新建Volume:
# kubectl apply -f -
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-ceph-blockstorage-pvc
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-ceph-blockstorage
spec:
containers:
- name: test-ceph-blockstorage
image: jocatalin/kubernetes-bootcamp:v1
volumeMounts:
- name: volv
mountPath: /data
volumes:
- name: volv
persistentVolumeClaim:
claimName: test-ceph-blockstorage-pvc
输出结果如下:
# kubectl get pod test-ceph-blockstorage
NAME READY STATUS RESTARTS AGE
test-ceph-blockstorage 1/1 Running 0 5m4s
# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-ceph-blockstorage-pvc Bound pvc-6ff56a06-86a1-437c-b04f-62bb18e76375 20Gi RWO rook-ceph-block 5m8s
# rbd -p replicapool ls
csi-vol-e65ec8ef-7cc1-11ea-b6f8-ce60d5fc8330
从输出结果可见PV volume对应Ceph的一个RBD image。
共享文件系统存储
共享文件系统存储即提供文件系统存储接口,我们最常用的共享文件系统存储如NFS、CIFS、GlusterFS等,Ceph通过CephFS实现共享文件系统存储。
和创建Ceph Pool一样,同样使用Kubernetes即可声明一个共享文件系统实例,完全不需要调用Ceph接口:
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
dataPools:
- replicated:
size: 3
preservePoolsOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
可以通过如下命令查看mds服务是否就绪:
# kubectl -n rook-ceph get pod -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-f87d59467-xwj84 1/1 Running 0 32s
rook-ceph-mds-myfs-b-c96645f59-h7ffr 1/1 Running 0 32s
# kubectl get cephfilesystems.ceph.rook.io
NAME ACTIVEMDS AGE
myfs 1 111s
创建cephfs StorageClass:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
clusterID: rook-ceph
fsName: myfs
pool: myfs-data0
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
我们知道CephFS是共享文件系统存储,支持多个Pod共享,首先我们创建一个ReadWriteMany的PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: rook-cephfs
通过Deployment创建三个Pod共享这个PVC:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cephfs-demo
labels:
k8s-app: cephfs-demo
kubernetes.io/cluster-service: "true"
spec:
replicas: 3
selector:
matchLabels:
k8s-app: cephfs-demo
template:
metadata:
labels:
k8s-app: cephfs-demo
spec:
containers:
- name: cephfs-demo
image: jocatalin/kubernetes-bootcamp:v1
volumeMounts:
- name: volv
mountPath: /data
volumes:
- name: volv
persistentVolumeClaim:
claimName: cephfs-pvc
readOnly: false
等待Pod初始完成后,我们从其中一个Pod写入数据,看另一个Pod能否看到写入的数据:

CephFS Demo
如上图,我们往Pod cephfs-demo-5799fcbf58-2sm4b写入数据,从cephfs-demo-5799fcbf58-bkw9f可以读取数据,符合我们预期。
在Ceph Dashboard中我们也可以看到myfs实例一共有3个 clients:

CephFS Dashboard
对象存储
Ceph通过RGW实现对象存储接口,RGW兼容AWS S3 API,因此Pod可以和使用S3一样使用Ceph RGW,比如Python可以使用boto3 SDK对桶和对象进行操作。
首先我们需要创建RGW网关:
apiVersion: ceph.rook.io/v1
kind: CephObjectStore
metadata:
name: my-store
namespace: rook-ceph
spec:
metadataPool:
failureDomain: host
replicated:
size: 3
dataPool:
failureDomain: host
erasureCoded:
dataChunks: 2
codingChunks: 1
preservePoolsOnDelete: true
gateway:
type: s3
sslCertificateRef:
port: 80
securePort:
instances: 1
网关就绪后,我们就可以创建bucket了,虽然bucket不是Volume,但Rook也把bucket抽象封装为StorageClass:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-bucket
provisioner: ceph.rook.io/bucket
reclaimPolicy: Delete
parameters:
objectStoreName: my-store
objectStoreNamespace: rook-ceph
region: us-east-1
接下来就像声明PVC一样创建bucket了,不过不叫PVC,而是叫OBC(Object Bucket Claim):
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ceph-bucket
spec:
generateBucketName: ceph-bkt
storageClassName: rook-ceph-bucket
其中AK(Access key)以及SK(Secret key)保存在Secret ceph-bucket中,我们可以通过如下命令获取:
export AWS_ACCESS_KEY_ID=$(kubectl -n default \
get secret ceph-bucket -o yaml \
| grep AWS_ACCESS_KEY_ID \
| awk '{print $2}' | base64 --decode)
export AWS_SECRET_ACCESS_KEY=$(kubectl -n default \
get secret ceph-bucket -o yaml \
| grep AWS_SECRET_ACCESS_KEY \
| awk '{print $2}' | base64 --decode)
# S3 Endpoint为Service rook-ceph-rgw-my-store地址
export AWS_ENDPOINT=http://$(kubectl get svc \
-n rook-ceph \
-l app=rook-ceph-rgw \
-o jsonpath='{.items[0].spec.clusterIP}')
此时就可以使用s3命令进行操作了:

aws_s3_ls
如上我们通过aws s3 cp命令上传了一个文本文件,通过aws s3 ls命令我们发现文件已经上传成功。
总结
通过Rook,我们几乎不需要直接对Ceph进行任何操作,Rook实现了Ceph对象对应的CRD,集群部署、配置、资源供给等操作都能通过Kubernetes CR进行声明,借助Kubernetes的能力实现了Ceph集群的self-managing、self-scaling以及self-healing。
总结
本文首先介绍了PV/PVC/Storageclass、Kubernetes存储发展过程以及CAS存储方案,然后分别介绍了目前比较主流的开源云原生分布式存储Longhorn、OpenEBS以及Rook,其中Longhorn比较简单,并且提供了原生的WebUI,麻雀虽小五脏俱全。OpenEBS是CAS的开源实现方案,支持Jiva、cStor以及LocalPV存储后端,Rook Ceph则实现通过Kubernetes管理和运行Ceph集群。
网上有一篇文章Storage on Kubernetes: OpenEBS vs Rook (Ceph) vs Rancher Longhorn[7]针对如上开源云原生存储方案以及部分商业产品的性能使用fio进行了测试,供参考。
如下表格中绿色表示性能表现最好,红色表示性能最差:
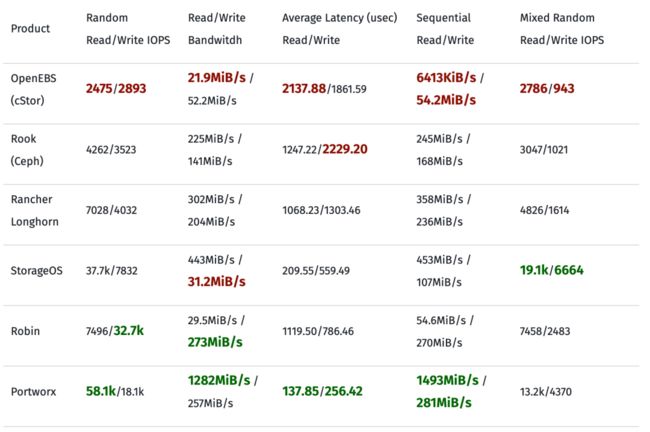
性能对比
相关链接:
https://github.com/kubernetes/examples/blob/master/staging/volumes/flexvolume/lvm
https://github.com/kubernetes-csi/csi-driver-host-path
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md
https://github.com/kubernetes-csi/csi-driver-host-path
https://rancher.com/blog/2017/announcing-longhorn-microservices-block-storage/
https://openebs.io/
https://vitobotta.com/2019/08/06/kubernetes-storage-openebs-rook-longhorn-storageos-robin-portworx/
文章来源:民生运维人,点击查看原文。
基于Kubernetes的DevOps实战培训
基于Kubernetes的DevOps实战培训将于2020年5月15日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片或者阅读原文链接查看详情。
