一文搞懂Pandas Dataframe中的apply方法
告诉你如何在Pandas数据框架中使用apply()的方法。
扫码关注《Python学研大本营》,加入读者群,分享更多精彩
热点
在这篇文章中,我们将探索如何在DataFrame中使用apply()方法做不同的活动。
在本教程中,我们将介绍以下内容。
-
了解Python中的apply()方法以及何时使用该方法
-
在Pandas系列中实现apply()方法
-
在Pandas数据框架上实现apply()方法
-
在Pandas数据框架上实现apply()方法以解决四个用例
了解Python中的apply()方法以及何时使用该方法?
apply()方法主要用于数据清理,它侧重于对pandas系列中的每一个元素和pandas数据框中的每一行/一列应用该方法。
让我们开始吧。
在Pandas系列上实现apply()方法
系列是一维数组,它的轴标签被命名为索引,由不同类型的数据组成,如字符串、整数和其他 Python 对象。
让我们来实现一个系列对象,它有两个列表,其中包含作为索引的行星和作为数据的直径(公里)。
代码:
import pandas as pd
import numpy as np
planetinfo = pd.Series(data=[12750, 6800, 142800, 120660],
index=["Earth", "Mars", "Jupiter", "Saturn"])
planetinfo
输出: 上面的代码返回一个planetinfo对象和它相应的数据类型。由于对象的数据类型是系列,让我们看看如何使用apply()方法将每个行星的直径(公里)转换为英里
代码:
def km_to_miles(data):
return 0.621371 * data
print(planetinfo.apply(km_to_miles))
输出:

上面的代码返回了每个行星的直径从公里到英里的转换。为了做到这一点,我们首先定义了一个名为km_to_miles()的函数,然后我们将这个函数不带任何括号地传递给apply()方法。然后,apply()方法将系列中的每一个数据点都应用到km_to_miles()函数上。
在Pandas数据框架上实现apply()方法
我们现在将创建一个假的数据框,以了解我们如何在数据框中使用apply()方法进行行和列操作。我们要创建的假数据框包含了学生的详细信息,使用的代码如下。
代码:
studentinfo=pd.DataFrame({'STUDENT_NAME':["MarkDavis","PriyaSingh","KimNaamjoon","TomKozoyed","TommyWalker"],
"ACADEMIC_STANDING":["Good","Warning","Probabtion","Suspension","Warning"],
"ATTENDANCE_PERCENTAGE":[0.8,0.75,0.25,0.12,0.30],
"MID_TERM_GRADE": ["A+","B-","D+","D-","F"]})
studentinfo
输出:
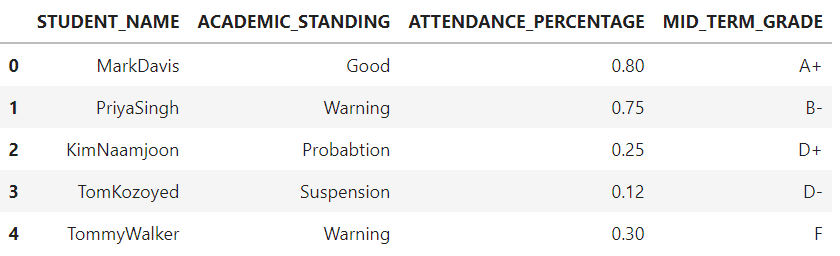
我们现在已经创建了一个名为studentinfo的虚拟数据框,并将通过探索4个不同的用例来学习如何实现apply()方法。每个用例都是新的,将通过使用apply()方法来解决。
用例1
作为数据清理检查的一部分,我们将检查列STUDENT_NAME中的所有值是否只有字母。为了做到这一点,我们将定义一个名为datacheck()的函数,通过使用isalpha()方法获取STUDENT_NAME列并返回True或False。结果的真或假将被返回到studentinfo数据框中一个名为IS_ALPHABET的新列中。
代码:
def datacheck(data):
if data.isalpha():
return True
else:
return False
现在我们将通过实现apply()方法在studentinfo数据框架的STUDENT_NAME列上应用datacheck()函数。
代码:
studentinfo["IS_ALPHABET"] = studentinfo["STUDENT_NAME"].apply(datacheck)
studentinfo
输出:
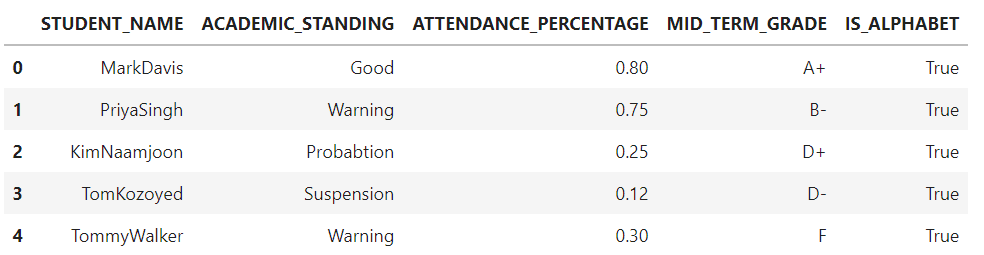
我们可以看到datacheck()函数是如何应用于STUDENT_NAME列的每一行,并且返回的结果被存储在一个名为IS_ALPHABET的新列中。
用例2
作为另一个数据清理检查的一部分,我们将减少列ACADEMIC_STANDING的cardinality,我们将把好的类别标记为ACADEMIC_STANDING_GOOD,其余类别标记为ACADEMIC_STANDING_BAD。
为了实现这个用例,我们将定义一个名为reduce_cardinality()的函数,获得ACADEMIC_STANDING列。在这个函数中,ifstatement将被用于比较检查,因此将ACADEMIC_STANDING_GOOD和ACADEMIC_STANDING_BAD的结果返回给ACADEMIC_STANDING列。
代码:
def reduce_cardinality(data):
if data != "Good":
return "ACADEMIC_STANDING_BAD"
else:
return "ACADEMIC_STANDING_GOOD"
现在我们将通过实现apply()方法在studentinfo数据框架的ACADEMIC_STANDING列上应用reduce_cardinality()函数。
代码:
studentinfo["ACADEMIC_STANDING"]=studentinfo["ACADEMIC_STANDING"].apply(reduce_cardinality)
studentinfo
输出:
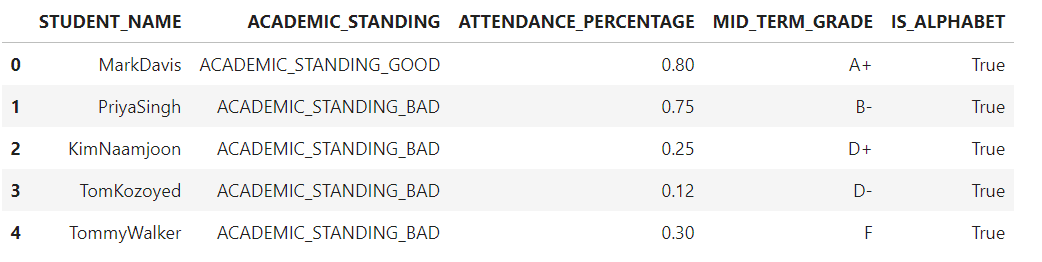
我们可以看到reduce_cardinality()函数是如何应用于ACADEMIC_STANDING列的每一行的,ACADEMIC_STANDING列中的原始值现在已经被修改为两个不同的类别,即ACADEMIC_STANDING_BAD和ACADEMIC_STANDING_GOOD,从而降低了数据的基数。
用例3
在这个用例中,我们将再次减少MID_TERM列的cardinality,我们将把A,B,C开头的成绩标记为Corhigher,D,F,W开头的成绩标记为Dorlower。
为了实现这个用例,我们将定义一个名为reduce_cardinality_grade()的函数,获得MID_TERM_GRADE列。在这个函数中,ifstatement和()startswith方法将被用于比较检查,从而将结果Corhigher和Dorlower返回给MID_TERM_GRADE列。
代码:
def reduce_cardinality_grade(data):
if data.startswith('A'):
return "Corhigher"
elif data.startswith('B'):
return "Corhigher"
elif data.startswith('C'):
return "Corhigher"
else:
return "Dorlower"
现在我们将通过实现apply()方法将reduce_cardinality_grade()函数应用于studentinfo数据框的MID_TERM_GRADE列。
代码:
studentinfo["MID_TERM_GRADE"]=studentinfo["MID_TERM_GRADE"].apply(reduce_cardinality_grade)
studentinfo
输出:
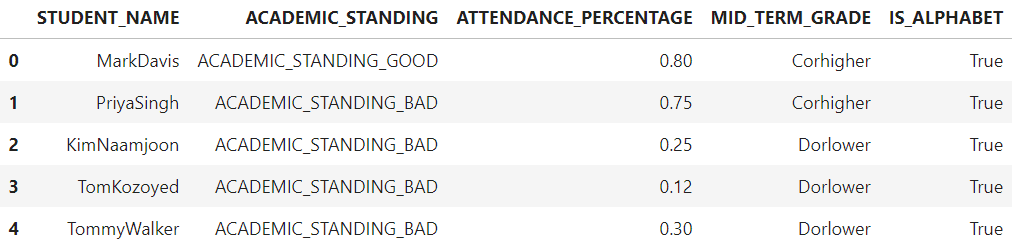
我们可以看到reduce_cardinality_grade()函数是如何应用于MID_TERM_GRADE列的每一行的,MID_TERM_GRADE列内的原始值现在已经被修改为两个不同的类别,即Corhigher和Dorlower,因此减少了基数。
用例_4
在这个案例中,我们将在函数check()中创建一个名为FINAL_GRADE_STATUS的新列,FINAL_GRADE_STATUS中的值将根据以下两个条件决定。
-
如果学生的ATTENDANCE_PERCENTAGE>=0.6,MID_TERM_GRADE为Corhigher,FINAL_GRADE_STATUS将被标记为High_Chance_Of_Passing。
-
如果学生的ATTENDANCE_PERCENTAGE<0.6,并且MID_TERM_GRADE比FINAL_GRADE_STATUS低,将被标记为Low_Chance_Of_Passing。
在这个函数中,比较检查将通过使用Python中的ifstatement和操作符来完成。
代码:
def check(data):
if (data["ATTENDANCE_PERCENTAGE"] >= 0.6) and (data["MID_TERM_GRADE"] == "Corhigher"):
return "High_Chance_Of_Passing"
elif (data["ATTENDANCE_PERCENTAGE"] < 0.6) and (data["MID_TERM_GRADE"] == "Dorlower"):
return "Low_Chance_Of_Passing"
现在我们将通过实现apply()方法,在studentinfo数据框的ATTENDANCE_PERCENTAGE、MID_TERM_GRADE列上应用检查函数。axis=1参数意味着要在数据框中的行上进行迭代。
代码:
studentinfo["FINAL_GRADE_STATUS"]=studentinfo[["ATTENDANCE_PERCENTAGE","MID_TERM_GRADE"]].apply(check,axis = 1)
studentinfo
输出:
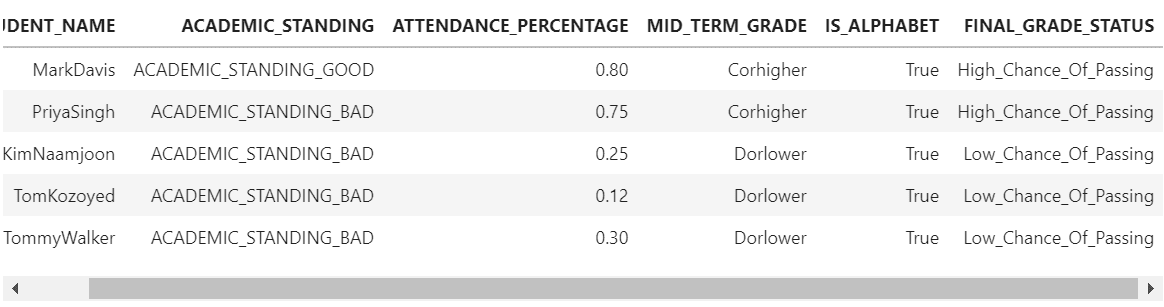
我们可以看到check()函数是如何应用于MID_TERM_GRADE和ATTENDANCE_PERCENTAGE列的每一行,从而返回一个名为FINAL_GRADE_STATUS的新列,其值为Corhigher和Dorlower。
总结
在本教程中,我们通过探索不同的用例了解了如何使用apply()方法。apply()方法使用户能够对系列或pandas数据框的每个值进行不同类型的数据操作。
参考:https://www.kdnuggets.com/2022/07/apply-method-pandas-dataframes.html
新书快讯
《Pandas1.x实例精解》
购买链接:https://item.jd.com/13255935.html
内容系统全面,紧跟时代步伐
本书详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
深入浅出,清晰而透彻
本书以操作秘笈的形式编写,包含近100个秘笈,从非常简单的应用到高级操作技巧都有涵盖。所有秘笈力求以清晰、简洁、现代的惯用Pandas代码编写。“实战操作”部分详细介绍各个秘笈的操作步骤,“原理解释”部分对秘笈的每一步都进行非常详细的阐释。绝大多数秘笈还提供“扩展知识”部分。
读者将收获什么?
读者能够举一反三,发展出自己的操作技巧。本书包含大量的Pandas代码,并提供了配套的源数据文件,以便读者跟随操作和对照学习。
适用读者
阅读本书需要掌握一定的Python基础知识。我们假定读者熟悉Python中所有常见的内置数据容器,如列表、集合、字典和元组。

精彩回顾
想用Python赚钱?——安排!
Kindle退出中国怎么办?快用Python下载你的电子书
可视化案例研究——以智利总统选举为例
扫码关注《Python学研大本营》,加入读者群,分享更多精彩