Tesseract-OCR下载和安装,Python-OCR使用
Tesseract-OCR下载和安装,Python-OCR使用Tesseract-OCR
文章目录
- Tesseract-OCR下载和安装,Python-OCR使用Tesseract-OCR
-
- Tesseract-OCR下载
- Tesseract-OCR 安装
- Tesseract-OCR设置系统环境
- Python-OCR使用Tesseract-OCR
- 安装问题,下载语言包
Tesseract-OCR下载
方法一:https://github.com/UB-Mannheim/tesseract/wiki
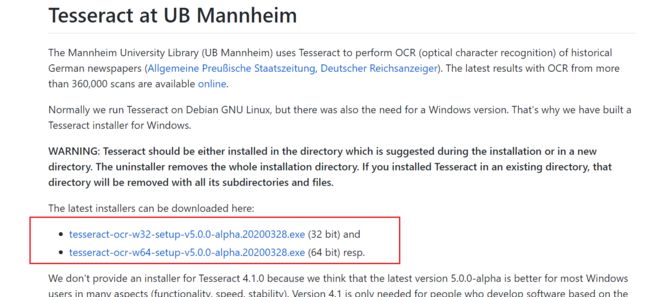
方法二https://digi.bib.uni-mannheim.de/tesseract/
下载最新版即可
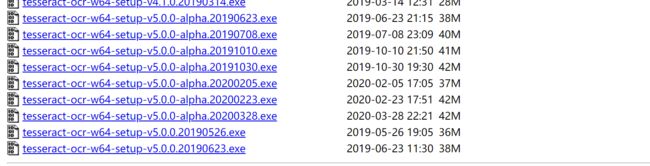
Tesseract-OCR 安装
1
2
3.将第三个选项展开,选择红框内选项才可以识别中文,当然可以根据需要下载更多的语言包。
若之后需要下载识别其他语言的字符,也可进入官网直接下载对应语言包,下载完成后放到Tesseract-OCR\tessdata下即可。
https://blog.csdn.net/input_sudo/article/details/106640807
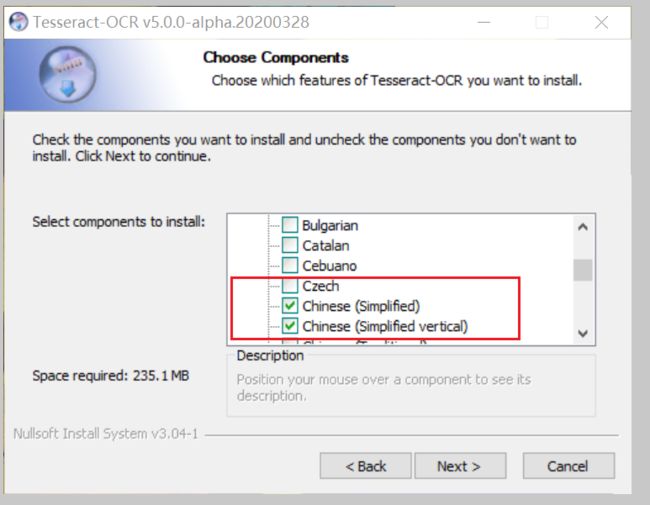
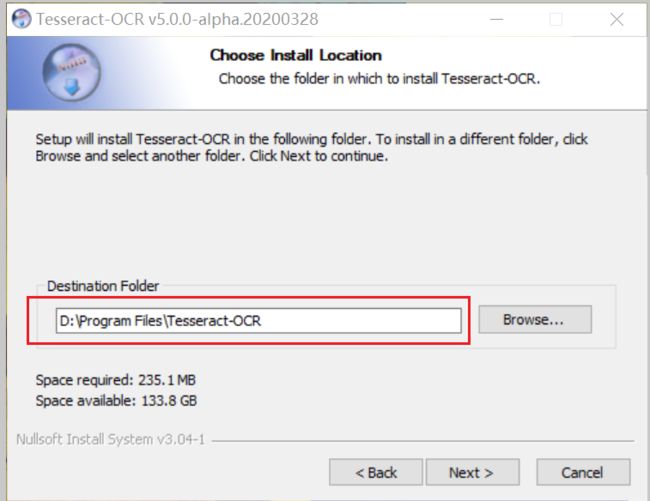
4.最好改变地址到D盘,记住地址,待会要设置系统环境
5
6
Tesseract-OCR设置系统环境
尽管我们在利用python调用Tesseract-OCR时可以设置他的诚心地址,但还是设置系统环境好一些。
step 1
Windows+R打开运行,输入sysdm.cpl回车
step 2 在系统属性框点击【高级】栏下的【环境变量】
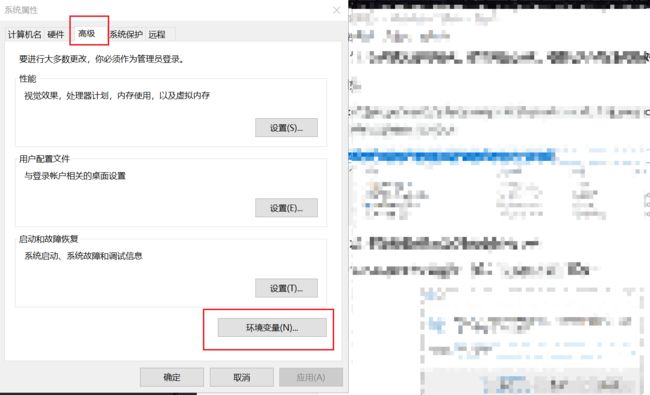
step 3 在系统变量下的Path下点击【新建】添加Tesseract-OCR的安装地址
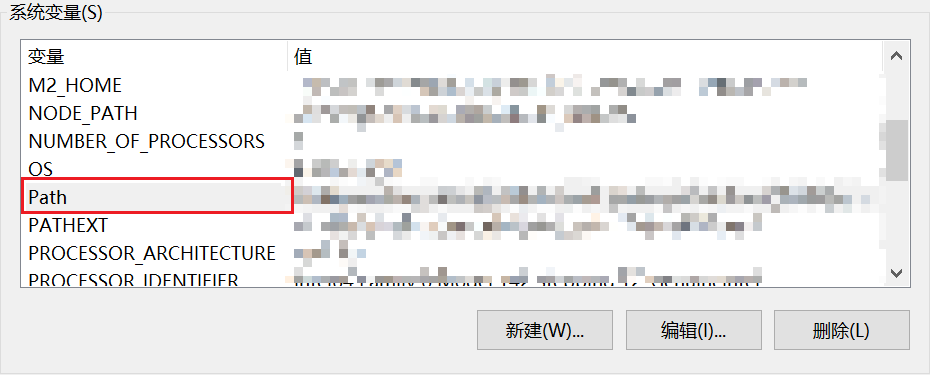
我的地址是 D:\Program Files\Tesseract-OCR
添加完地址后一路点击确定退出。
Python-OCR使用Tesseract-OCR
需要 pillow 和 pytesseract
安装库
pip install Pillow
pip install pytesseract
测试程序
import pytesseract
from PIL import Image
def OCR_demo():
# 导入OCR安装路径,如果设置了系统环境,就可以不用设置了
# pytesseract.pytesseract.tesseract_cmd = r"D:\Program Files\Tesseract-OCR\tesseract.exe"
# 打开要识别的图片
image = Image.open('Snipaste_2020-11-13_12-11-16.png')
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别,
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)
if __name__ == '__main__':
OCR_demo()
征。CBOW (continuous-bag-of-words) 和 skip-gram 是 Word2Vec 的两种模型 。
本文使用 CBOW 模型将文本数据集训练成词向量。CBOW 是 Mikolov 于 2013 年在
传统的NNLM (Natural Network Language Model ) 模型的基础上改进而来的。

总体识别结果还可以
安装问题,下载语言包
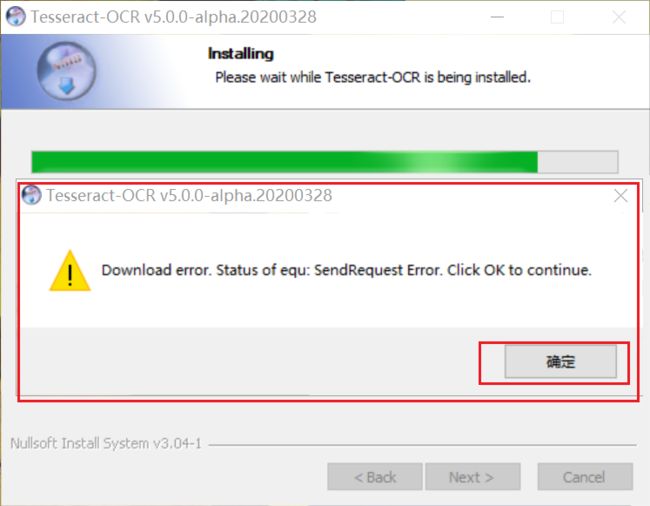
如果安装时出现下面情况
是语言包下载失败,可以点击确定,安装程序即可,后面再下载语言包
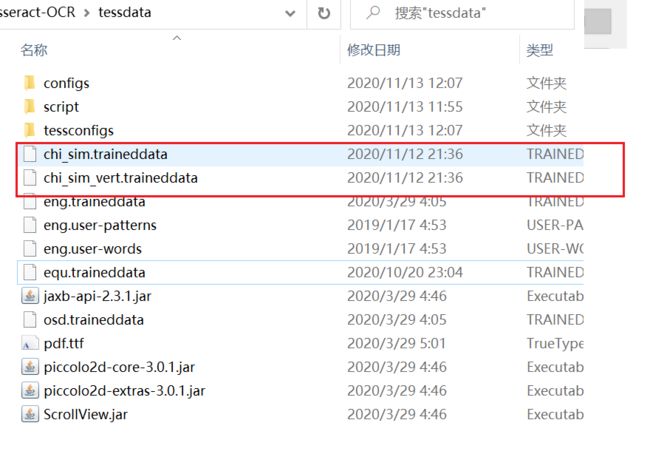
可进入官网直接下载对应语言包,下载完成后放到Tesseract-OCR\tessdata下即可
https://github.com/tesseract-ocr/tessdata
这里的语言包比较久,但暂时没有发现最新语言包在那下载,可以先用用

.\
.
.
.\
.
.
.