论文笔记32 -- Conformer: Local Features Coupling Global Representations for Visual Recognition
CNN + Transformer
论文:点这里
代码:点这里
Zhiliang Peng,Wei Huang,Shanzhi Gu,Lingxi Xie,Yaowei Wang,Jianbin Jiao,Qixiang Ye
国科大,华为,鹏城实验室
Abstract
在卷积神经网络(CNN)中,卷积操作擅长提取局部特征,但难以捕获全局表示。在Visual Transformer中,级联自注意力模块可以捕获长距离特征依赖关系,但不幸的是会破坏局部特征细节。在本文中,我们提出了一种称为 Conformer 的混合网络结构,以利用卷积运算和自注意力机制来增强表征学习。Conformer 源于特征耦合单元(FCU),它以交互方式融合不同分辨率下的局部特征和全局表示。Conformer 采用并行结构,以便最大程度地保留局部特征和全局表示。实验表明,在参数复杂度相当的情况下,Conformer 在 ImageNet 上的性能比Visual Transformer (DeiT-B) 高 2.3%。在 MSCOCO 上,它在目标检测和实例分割方面的性能分别比 ResNet-101 高 3.7% 和 3.6%,显示出作为通用骨干网络的巨大潜力。
1. Introduction
卷积神经网络(CNN) [28,36,39,18,47,21] 具有显著的先进计算机视觉任务,如图像分类、目标检测和实例分割。这主要归功于卷积操作,它以分层方式收集局部特征作为强大的图像表示。尽管在局部特征提取方面具有优势,但 CNN 难以捕获全局表示,例如视觉元素之间的长距离关系,这对于高级计算机视觉任务通常至关重要。一个直观的解决方案是扩大感受野,但这可能需要更密集但具有破坏性的池化操作。
最近,transformer 架构 [42] 已被引入视觉任务 [16、46、41、50、8、9、3、53、27]。ViT 方法 [16] 通过将每个图像拆分为具有位置 embeddings 的 patches 来构建一系列 tokens,并应用级联 transformer blocks 来提取参数化向量作为视觉表示。由于 self-attention 机制和多层感知器 (Multilayer Perceptron,MLP) 结构,visual transformer 反映了复杂的空间变换和长距离特征依赖性,它们构成了全局表示。不幸的是,观察到的 visual transformer 忽略了局部特征细节,这降低了背景和前景之间的可判别性,图 1 (c)和(g)。改进的 visual transformer [16, 50] 提出了一个标记化模块或利用 CNN 特征图作为输入 tokens 来捕获特征相邻信息。然而,关于如何精确的将局部特征和全局表示相互嵌入(embed)的问题仍然存在。
在本文中,我们提出了一种称为 Conformer 的双网络结构,旨在将基于 CNN 的局部特征与基于 transformer 的全局表示相结合,以增强表示学习。Conformer 由一个 CNN 分支和一个 Transformer 分支组成,它们分别遵循 ResNet [18] 和 ViT [16] 的设计。这两个分支构成了局部卷积块(local convolution blocks)、自注意力(self-attention)模块和 MLP 单元的综合结合体。在训练过程中,交叉熵(cross entropy)损失用于监督 CNN 和 Transformer 分支,以耦合 CNN 风格和 transformer 风格的特征。
考虑到 CNN 和 Transformer 特征之间的特征错位,设计了特征耦合单元(FCU)作为桥梁。一方面,为了融合两种风格的特征,FCU 利用 1×1 卷积来对齐通道维度(channel dimensions),利用下/上采样策略来对齐特征分辨率(feature resolutions),利用 LayerNorm [2] 和 BatchNorm [24] 来对齐特征值(feature values)。另一方面,由于 CNN 和 Transformer 分支倾向于捕获不同级别(e.g., local vs. global)的特征,因此将 FCU 插入到每个块中,以交互方式连续消除它们之间的语义分歧。这样的融合过程可以极大地增强局部特征的全局感知能力和全局表示的局部细节。
Conformer 在耦合局部特征和全局表示方面的能力如图 1 所示。 虽然传统的 CNN(例如 ResNet-101)倾向于保留有判别力的局部区域(例如,孔雀的头部或尾部),但 Conformer 的 CNN 分支可以激活完整的目标范围,图 1 (b)和(f)。当仅使用 visual transformers 时,对于较弱的局部特征(例如,模糊的目标边界),很难将目标与背景区分开来,图 1 (c)和(g)。 局部特征和全局表示的耦合显著增强了基于 transformers 的特征的可判别性,图 1(d)和(h)。
本文的贡献包括:
- 我们提出了一种双重网络结构,称为Conformer,它最大限度地保留了局部特征和全局表示。
- 我们提出了特征耦合单元(FCU),以交互方式将卷积局部特征与基于 transformers 的全局表示融合。
- 在可比的参数复杂性下,Conformer 的性能明显优于 CNN 和 visual transformers。Conformer 继承了 CNN 和 visual transformers 的结构和泛化优势,展示了成为通用骨干网络的巨大潜力。

2. Related Work
CNNs with Global Cues. 在深度学习时代,CNNs 可以看作是具有不同感受野的局部特征的层次集合。不幸的是,大多数 CNN [28,36,18,38,47,22,43] 擅长提取局部特征,但难以捕捉全局线索。
为了缓解这种限制,一种解决方案是通过引入更深的架构和/或更多的池化操作来定义更大的感受野 [21,20]。扩张卷积方法 [48,49] 增加了采样步长,而可变形卷积 [13] 学习了采样位置。SENet [21] 和 GENet [20] 提出使用全局 Avgpooling 来聚合全局上下文,然后用它来重新加权特征通道,而 CBAM [45] 分别使用全局 Maxpooling 和全局 Avgpooling 在空间和通道(spatial and channel)维度上独立细化特征。
另一种解决方案是全局注意力机制 [44,7,4,19,37],它在捕获自然语言处理中的长距离依赖关系方面表现出了巨大的优势 [42,15,5]。受非局部均值(non-local means)方法 [6] 的启发,非局部(non-local)操作 [44] 以自注意(self-attention)方式引入 CNN,因此每个位置的响应是所有(全局)位置特征的加权和。注意增强卷积( augmented convolutional)网络 [4] 将卷积特征图与自注意特征图连接起来,以增强卷积操作,从而捕获远程交互。Relation Networks [19] 提出了一个目标注意模块,它通过一组目标的外观特征和几何形状之间的交互,同时处理一组目标。
尽管取得了进展,但现有的将全局线索引入 CNN 的解决方案存在明显的缺点。对于第一种解决方案,更大的感受野需要更密集的池化操作,这意味着更低的空间分辨率。对于第二种解决方案,如果卷积操作没有与注意力机制正确融合,局部特征细节可能会恶化。
Visual Transformers. 作为一项开创性工作,ViT [16] 验证了纯 transformer 架构在计算机视觉任务中的可行性。为了利用长距离依赖,transformer blocks 充当独立架构,或被引入 CNN 以进行图像分类 [46,41,50]、目标检测 [8,56,3]、语义分割 [53]、图像增强 [9] ] 和图像生成 [11,27]。然而,visual transformers 中的自注意力机制经常忽略局部特征细节。为了解决这个问题,DeiT [41] 提出使用蒸馏 token 将基于 CNN 的特征转移到 visual transformers,而 T2TViT [50] 提出使用 tokenization 模块递归地将图像重新组织为考虑相邻像素的 tokens。DETR 方法 [8, 56] 将 CNN 提取的局部特征提供给 transformer encoder-decoder,以串行方式对特征之间的全局关系进行建模。
与现有作品不同,Conformer 定义了第一个以交互方式融合特征的并发网络结构。这种结构不仅自然地继承了 CNN 和 transformers 两者的结构优势,而且最大程度地保留了局部特征和全局表示的表示能力。
3. Conformer
3.1. Overview
局部特征和全局表示是视觉描述符的重要对应物,在视觉描述符(visual descriptors)的漫长历史中,人们对其进行了广泛的研究。局部特征及其描述符 [33,26,34] 是局部图像邻域的紧凑矢量表示,已成为许多计算机视觉算法的组成部分。全局表示包括但不限于轮廓表示、形状描述符和远距离的目标类型(object typologies at longdistance) [31]。在深度学习时代,CNN 通过卷积运算以分层的方式收集局部特征,并保留局部线索作为特征图。Visual Transformer被认为通过级联的自注意力模块以软方式在压缩的 patch embeddings 中聚合全局表示。
为了利用局部特征和全局表示,我们设计了一个并发网络结构,如图 2(c) 所示,称为 Conformer。考虑到两种风格特征的互补性,在 Conformer 中,我们连续地将来自 transformer 分支的全局上下文提供给特征图,以加强 CNN 分支的全局感知能力。类似地,来自 CNN 分支的局部特征逐步反馈到 patch embeddings,以丰富 transformer 分支的局部细节。这样的过程构成了相互作用。
具体来说,Conformer 由一个主干模块、双分支、桥接双分支的 FCU 和用于双分支的两个分类器(一个 fc 层)组成。主干模块是一个 7×7 卷积,步长为 2,然后是一个 3×3 max pooling,步长为 2,用于提取初始局部特征(例如,边缘和纹理信息),然后将初始局部特征送到双分支。CNN 分支和 transformer 分支分别由 N 个(e.g., 12)个重复的卷积和 transformer blocks 组成,如表 1 中所述。这样的并发结构意味着 CNN 和 transformer 分支可以分别最大程度地保留局部特征和全局表示。FCU 作为桥接模块,将 CNN 分支中的局部特征与 transformer 分支中的全局表示融合,图 2(b)。FCU 从第二个 block 开始应用,因为两个分支的初始化特征是相同的。沿着分支,FCU 以交互方式逐步融合特征图和 patch embeddings。
最后,对于 CNN 分支,所有特征都被汇集并送到一个分类器。对于 transformer 分支,类 token 被取出并送到另一个分类器。在训练过程中,我们使用两个交叉熵损失来分别监督两个分类器。根据经验这里两将两个损失的权重设置为相同。在推理过程中,两个分类器的输出被简单地概括为预测结果。

3.2. Network Structure
CNN Branch. 如图 2(b)所示,CNN 分支采用特征金字塔结构,特征图的分辨率随着网络深度的增加而降低,而通道数增加。我们将整个分支分为 4 个阶段,如 Tab. 1(CNN Branch)。每个阶段由多个卷积块(convolution block)组成,每个卷积块包含 n c \ n_c nc bottlenecks。按照 ResNet [18] 中的定义,bottleneck 包含一个 1×1 下投影卷积(down-projection convolution)、一个 3×3 空间卷积(spatial convolution)、一个 1×1 上投影卷积(up-projection convolution),以及 bottleneck 的输入和输出之间的残差连接。在实验中, n c \ n_c nc 在第一个卷积块中设置为 1,在随后的 N-1 个卷积块中满足 ≥2。
Visual transformers [16, 41] 通过一个步骤将图像 patch 投影到一个向量中,导致局部细节丢失。而在 CNN 中,卷积核在重叠的特征图上滑动,这提供了保留精细局部特征的可能性。因此,CNN 分支能够为 transformer 分支连续提供局部特征细节。
Transformer Branch. 在 ViT [16] 之后,这个分支包含 N 个重复的 Transformer blocks。如图 2(b)所示,每个 transformer block 由一个多头自注意力模块(multi-head self-attention module)和一个 MLP block(包含一个上投影 fc 层和一个下投影 fc 层)组成。LayerNorms [2] 应用于自注意力层和 MLP block 中的每一层和残差连接之前。对于 tokenization,我们通过线性投影层( linear projection layer)将主干模块生成的特征图压缩为没有重叠的 14×14 patch embeddings,该线性投影层是一个 4×4 卷积,步长为 4。然后将类 token 假装成 patch embeddings 进行分类。考虑到 CNN 分支(3×3 卷积)对局部特征和空间位置信息进行编码 [25],不再需要位置 embeddings。这有助于提高下游视觉任务的图像分辨率。
Feature Coupling Unit. 对于 CNN 分支中的特征图和 transformer 分支中的 patch embeddings,如何消除它们之间的偏差(misalignment)是一个重要的问题。为了解决这个问题,我们提出 FCU 以交互方式将局部特征与全局表示连续耦合。
一方面,我们必须意识到 CNN 和 transformer 的特征维度是不一致的。 CNN 特征图的维度为 C × H × W(C、H、W 分别为通道、高度和宽度),而 patch embeddings 为 (K + 1) × E,其中 K、1 和 E分别表示图像块 patches 的数量、类 token 和 embedding 维度。当输入到 Transformer 分支时,特征图首先需要通过 1×1 卷积来对齐 patch embeddings 的通道数。然后使用下采样模块(图 2(a))来完成空间维度对齐。最后,特征图添加了 patch embeddings,如图 2(b)所示。当从 transformer 分支反馈到 CNN 分支时,patch embeddings 需要上采样(图 2(a))以对齐空间尺度。然后通过 1×1 卷积将通道维度与 CNN 特征图的维度对齐,并添加到特征图中。同时,使用 LayerNorm 和 BatchNorm 模块对特征进行正则化。
3.3. Analysis and Discussion
Structure Analysis. 通过将 FCU 视为短连接,我们可以将提出的对偶结构抽象为特殊的串行残差结构,如图 3(a)所示。在不同的残差连接单元下,Conformer 可以实现 bottlenecks(如 ResNet,图 3(b))和 transformer blocks(如 ViT,图 3(d))的不同深度组合,这意味着 Conformer 继承了 CNN 和 visual transformers 的结构优势。此外,它还实现了不同深度的 bottleneck 和 transformer block 的不同排列,包括但不限于图 3(c)和(e)。这极大增强了网络的表示能力。
Feature Analysis. 我们可视化了图 1 中的特征图、图 4 中的类激活图和注意图。与 ResNet[18] 相比,通过耦合的全局表示,Conformer 的 CNN 分支倾向于激活更大的区域,而不是局部区域,这表明增强了长距离特征依赖性,这在图 1(f)和 4(a)中得到了显著证明。由于 CNN 分支逐步提供了精细的局部特征,Conformer 中 transformer 分支的 patch embeddings 保留了重要的局部细节特征(图 1(d)和(h)),这些特征被视觉转换器恶化 [16,41](图 1(c)和(g))。此外,在图 4(b)中的注意力区域更完整,而背景被显著抑制,这意味着 Conformer 学习到的特征表示具有较高的判别能力。


4. Experiments
4.1. Model Variants
通过调整 CNN 和 Transformer 分支的参数,得到了模型的一些变体,分别为 Conformer-Ti、-S 和 -B。 Conformer-S 的详细信息在表 1 中有描述。Conformer-Ti/B 见附录。Conformer-S/32 将特征图拆分为 7×7 个 patches,即,transformer 分支中的 patch 大小为 32×32。
4.2. Image Classification
Experimental Setting. Conformer 在 ImageNet-1k [14] (有 1.3M images)训练集上训练,并在验证集上进行测试。表 2 中报告了 Top-1 的准确率。为了使 transformer 收敛到合理的性能,我们遵循 DeiT [41] 中的数据增强和正则化方法。这些方法包括 Mixup [52]、CutMix [51]、Erasing [54]、Rand Augment [12] 和 Stochastic Depth [23]。模型使用 AdamW 优化器 [32] 训练了 300 个 epoch,batchsize 为 1024,weight decay 为 0.05。初始学习率设置为 0.001,并按 cosine schedule 衰减。
Performance. 在类似的参数量和计算资源下,表 2,Conformers 优于 CNN 和 visual transformers。例如,Conformer-S(有 37.7M 参数和 10.6G MACs)分别优于 ResNet-152(60.2M 参数和 11.6G MACs)4.1%(83.4% vs. 78.3%)和 DeiT-B(86.6 M 参数和 17.6G MACs) 1.6%(83.4% vs. 81.8%)。Conformer-B 具有类似的参数量和适中的 MACs 成本,比 DeiT-B 好 2.3%(84.1% vs. 81.8%)。性能方面,Conformer 比 visual transformers 收敛得更快。
4.3. Object Detection and Instance Segmentation
为了验证 Conformer 的多功能性,我们在 MSCOCO 数据集 [30] 上的 instance-level 任务(如,目标检测)和 pixel-level 任务(如,实例分割)上对其进行了测试。Conformer 作为主干,在没有额外设计的情况下进行迁移,相对准确率和参数比较见表 2。通过 CNN 分支,我们可以使用 [c2,c3,c4,c5] 的输出特征图作为 side-output 来构建特征金字塔 [29]。
Experimental Setting.
Performance.


4.4. Ablation Studies
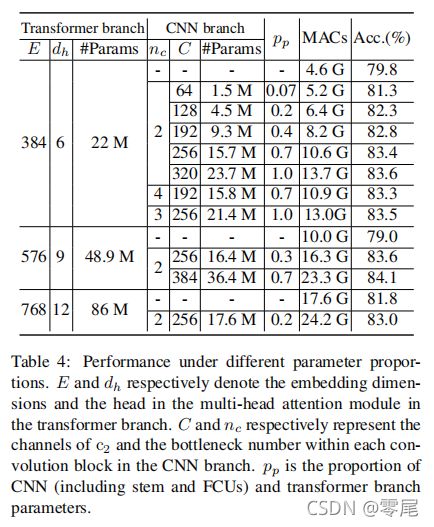
Number of Parameters.
Dual Structure.
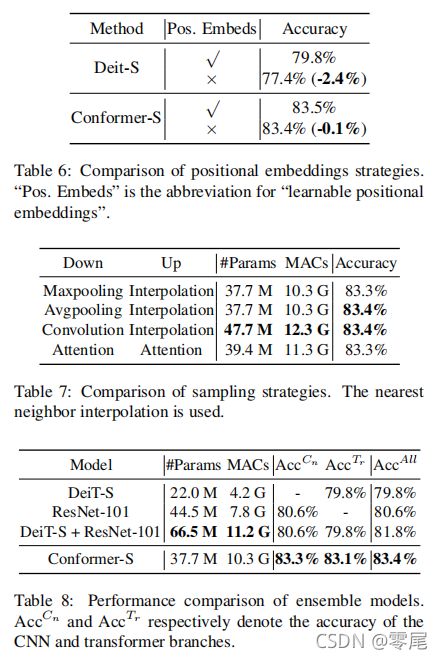
Positional Embeddings.
Sampling Strategies.
Comparison with Ensemble Models. Conformer 与结合了 CNN 和 Transformer 输出的集成模型进行了比较。 为了公平比较,我们使用相同的数据增强和正则化策略以及相同的训练epochs (300) 来训练 ResNet-101 [18],并将其与 DeiT-S [41] 模型结合形成一个集成模型,并在表8中报告了准确率。CNN 分支、transformer 分支和 Conformer-S 的准确率分别达到83.3%、83.1%、83.4%。相比之下,集成模型 (DeiT-S+ResNet-101) 为 81.8%,比 Conformer-S (83.4%) 低 1.6%,尽管它使用了更多的参数和 MACs。

4.5. Generalization Capability
Rotation Invariance. 为了验证模型在旋转方面的泛化能力,我们将测试图像旋转 0°、60°、120°、180°、240° 和 300°,并评估在相同数据增强设置下训练的模型的性能。如图 5(a) 所示,所有模型都报告了无旋转 (0°) 图像的可比性能。对于旋转的测试图像,ResNet-101 的性能显著下降。 相比之下,Conformer-S 报告了更高的性能,这意味着更强的旋转不变性。
Scale Invariance. 在图 5(b) 中,我们比较了 Conformer 与 visual transformers (DeiT-S) 和 CNN (ResNet) 的尺度适应能力。我们对 DeiT-S 的位置 embeddings 进行插值,使其在推理过程中适应不同分辨率的输入图像。当输入图像的大小从 224 减少到 112 时,DeiT-S 的性能下降了 25%,而 ResNet-50/152 的性能下降了 15%。 相比之下,Conformer 的性能仅下降了 10%,表明学习到的特征表示具有更高的尺度不变性。

5. Conclusion
我们提出了 Conformer,这是第一个将 CNN 与 Visual Transformer 相结合的双主干。在 Conformer 中,我们利用卷积算子来提取局部特征,并利用 self-attention 机制来捕获全局表示。我们设计了特征耦合单元(Feature Coupling Unit,FCU)来融合局部特征和全局表示,以交互方式增强视觉表示能力。