深度学习(11)——房价预测实践
前言
之前学习了各种回归模型,神经网络的先导知识,了解了回归的原理,掌握了回归的详细与简易实现方法,今天就用一个真实案例来检验一下学习成果,初次尝试独立解决问题,跑的结果不是特别好,将在往后不断的学习过程中不断优化自己的模型。
通过这次实践我发现这类数据分析或是数据预测的问题,数据清洗有着非常重要的作用,直接使用高维度的原数据不但跑的时间很长,而且跑出来的结果也相当不好,因此得选择对于数据分析有用的一些特征来建立模型。当数据准备完成后,建立模型实际上就是一个不断调参的过程,通过K交叉验证集不断的验证调参的好坏。
简单来说,就目前我的认知而言,数据分析就是数据处理+模型调参构成的,两者同等重要,甚至我认为前者更重要。
问题介绍
该问题来自于李沐老师在Kaggle上传的加利福尼亚房屋成交价预测。
传送门
有2张数据表,训练数据表和测试数据表。
训练数据表包含房屋参数与成交价;测试数据表仅有房屋数据。通过训练,预测出测试数据表的房屋成交价,提交至Kaggle完成项目。
数据展示与处理
导包
import pandas as pd
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
import seaborn as sns
import matplotlib.pyplot as plt
读取数据
train_data=pd.read_csv("../data/train.csv")
test_data=pd.read_csv("../data/test.csv")
print(train_data.shape,test_data.shape)
(47439, 41) (31626, 40)
训练数据40000+条,39个特征,1个Id,1个label
测试数据30000+条,39个特征(与训练数据一致),1个Id
查看数据
先将训练数据与测试数据合并,为了方便后面的异常值处理。
看一下有多少数值型的特征
all_features=pd.concat((train_data.iloc[:,4:],test_data.iloc[:,3:]))
all_features.reset_index(drop=True, inplace=True)
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
print(numeric_features)
Index(['Year built', 'Lot', 'Bathrooms', 'Full bathrooms',
'Total interior livable area', 'Total spaces', 'Garage spaces',
'Elementary School Score', 'Elementary School Distance',
'Middle School Score', 'Middle School Distance', 'High School Score',
'High School Distance', 'Tax assessed value', 'Annual tax amount',
'Listed Price', 'Last Sold Price', 'Zip'],
18个数值型特征,那么就有21个非数值特征
数值特征直接放入模型忠还是比较好处理的,非数值特征我们可以用独热编码来处理,我们下文再说,数值特征虽然不是很多,也就18个,但我们仍然想要尽可能的降维,筛选出一些对最终售价有关联的特征,我们可以利用皮尔逊相关系数来得到特征之间的相关性。
数值特征筛选
corrPearson = train_data.corr(method="pearson")
figure = plt.figure(figsize=(30,25))
sns.heatmap(corrPearson,annot=True,cmap='RdYlGn', vmin=-1, vmax=+1)
plt.title("PEARSON")
plt.xlabel("COLUMNS")
plt.ylabel("COLUMNS")
plt.show()
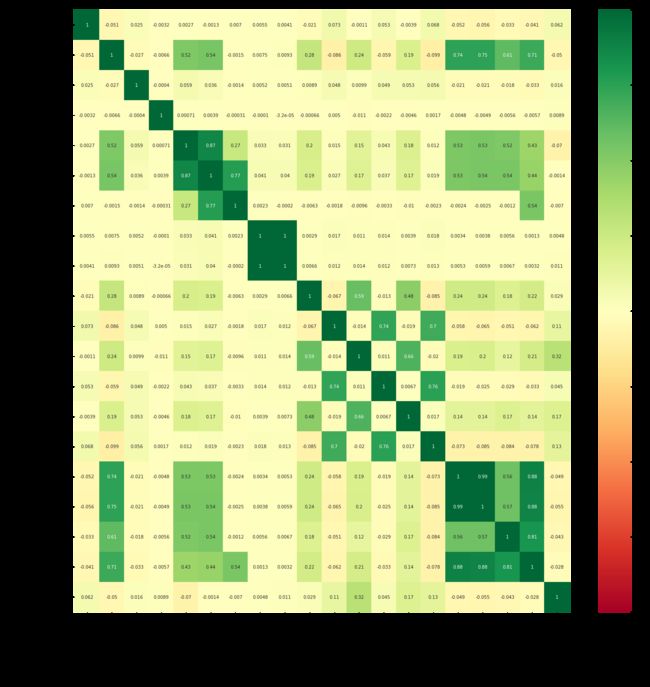
通过热力图可以发现,有6个特征和最终售价有比较紧密的关系,相关系数高于0.5,那么数值特征可以筛选出他们6个。
numeric_features_new=['Bathrooms', 'Full bathrooms', 'Tax assessed value', 'Annual tax amount',
'Listed Price', 'Last Sold Price']
数据处理
all_features就是全体训练数据+测试数据,数据处理通常会对数据标准化,为了保证数据的量纲一致,也就是将每个特征的数据都拉到一个均值0,方差1的范围中来。
将每个单元格的数值减去每个特征的均值,将这个差值除以特征的方差,就可以实现数据的标准化。
然后这里对空值做了简单的处理,就是直接赋0处理。
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)
非数值特征值筛选
先来看一下有哪些非数值型特征。
object_features=all_features.dtypes[all_features.dtypes == 'object'].index
print(object_features)
Index(['Type', 'Heating', 'Cooling', 'Parking', 'Bedrooms', 'Region',
'Elementary School', 'Middle School', 'High School', 'Flooring',
'Heating features', 'Cooling features', 'Appliances included',
'Laundry features', 'Parking features', 'Listed On', 'Last Sold On',
'City', 'State'],
接下来简单讲一下如何将非数值特征转换为数值特征,通常使用独热编码来实现,比如一个特征叫sex包含两个特征值:male&female,那么就生成两个新的特征sex_male和sex_female,如果原来sex这个特征下的特征值是male的话,那么新的sex_male特征下的特征值就是1,sex_female下的特征值就是0,举个具体例子比较好理解。那么对于这个例子来说,2个特征值的问题当然比较好解决,那么如果有很多特征值呢,比如当前这个问题,我们通过一个代码看一下这些非数值特征各自都含有多少特征值。
for f in object_features:
print(f,":",all_features[f].unique().shape[0])
Type : 174
Heating : 2660
Cooling : 911
Parking : 9913
Bedrooms : 278
Region : 1259
Elementary School : 3568
Middle School : 809
High School : 922
Flooring : 1740
Heating features : 1763
Cooling features : 596
Appliances included : 11290
Laundry features : 3031
Parking features : 9695
Listed On : 2815
Last Sold On : 6949
City : 1122
State : 2
最多的一个特征有超过10000个特征值,用独热编码就会多出来10000个特征,那么模型就会很复杂了,多一个特征就是多一个神经元,全部用独热编码,我也试过70000个神经元,那这个模型不但跑得慢,而且效果肯定特别差。那么我想到了两种解决方案,一个做一次特征筛选,把非数值特征也降维了,那么降维依据可以是只选取那些特征值少的维度,因为特征值多,实际上它对于预测本来就没有什么好处。另外一种方案是我保留这些特征,然后减少里面的特征值,这就需要获取每个特征里特征值的概率,然后把所有概率小于0.1%的特征值都命名为other,实际上那些概率很低的特征值本身对于预测就没意义,甚至还会造成过拟合,但这种方案我也试过,其实效果不佳。所以综合来看,我选择了第一种方案,最终定了4个非数值特征。
object_features_new=['Type','Bedrooms', 'City', 'State']
print(object_features_new)
非数值特征的独热编码
all_features=all_features[numeric_features_new+object_features_new]
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(79065, 1585)
这里将非数值特征里的空特征值都作为一个新特征。
最终的维度在1585,还算可以。
模型训练
获取数据
n_train = train_data.shape[0]
print(n_train)
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data['Sold Price'].values.reshape(-1, 1), dtype=torch.float32)
print(train_features)
获得训练数据与测试数据,获取训练数据的label
建立模型
模型及损失函数
用的是均方损失,均方损失就是(y-y_hat)2
模型我这边用的就是一层隐藏层的MLP,用Relu做激活函数
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,256),
nn.ReLU(),
nn.Linear(256,1))
return net
检验模型好坏的损失函数
这里的损失函数要区分一下,这个损失函数仅用作检验模型的损失,是一种相对损失,比如你1万和2万的误差是很大的,100万和101万,虽然也是误差1万,但是误差就显得很小了,因此我们要用相对误差来检验我们的模型好坏,但优化函数里面,我们还是用均方损失来做优化!
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
训练函数
与之前所讲一致,优化函数与之前的SGD不同,以后会学到。
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
K交叉验证
这里之前没有讲到,这里简单讲一下,我们将训练数据拆分成两堆,一堆训练,一堆验证,举个例子。
如果K=3,有60条数据,那么我们可以得到3组训练+验证的数据集:
第一组0-19作验证数据集,20-59作训练数据集。
第二组20-39作验证数据集,0-19,40-59作训练数据集。
第三组40-59作验证数据集,0-39作训练数据集。
最后将3组的训练损失与验证损失求均值,主要看3次的平均验证损失,如果损失值比较低,本题的话0.1-0.2就还算不错,那就可以拿这个模型去跑测试数据集了,然后把结果发到kaggle就可以获得测试损失了。
实现方法如下:
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
这个代码写的其实相当好相当的精炼,可以直接使用。
下面的代码获得K交叉验证结果。
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
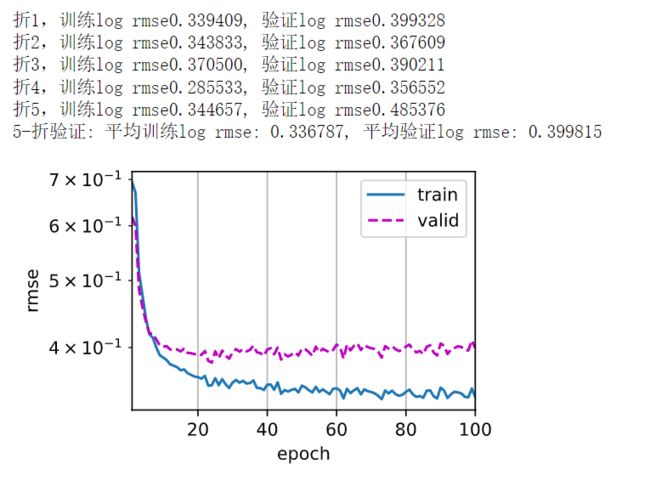
我做的结果不是很好,以后再不断优化吧。
测试并输出结果
def train_and_pred(train_features, test_feature, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
最终输出一个submission的csv提交给kaggle就会有结果了,我的结果不放了,哈哈哈。
小结
第一次尝试吧,还有很多不足的地方,重在学习的过程,以后经验丰富了,我就能更好的调参了,同时以后学到更多的模型,我也能更好的训练数据了,深度学习道路漫长,继续加油。