语音识别GMM-HMM
1.GMM
高斯混合模型(Gaussian Mixture Model),是一种业界广泛使用的聚类算法。K-means算法可以被视为高斯混合模型(GMM)的一种特殊形式。
1.1.高斯分布
高斯分布(Gaussian distribution)有时也被称为正态分布(normal distribution)。
概率密度函数公式如下:
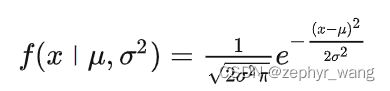
参数 μ 表示均值,参数 σ 表示标准差。
1.2.高斯混合模型
指包含多个高斯分布,每个高斯分布有属于自己的 μ 和 σ 参数,以及对应的权重参数,权重值必须为正数,所有权重的和必须等于1,以确保公式给出数值是合理的概率密度值。
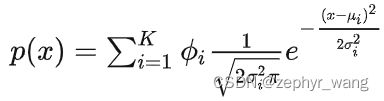
2.HMM
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。创立于20世纪70年代。自20世纪80年代以来,HMM被应用于语音识别。
2.1.隐马尔可夫模型的三要素
隐马尔可夫模型由初始状态向量π、状态转移矩阵A和观测概率矩阵(发射概率)B决定。π和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型可用三元符号表示,即
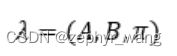
A为状态转移概率矩阵:

B为观测概率矩阵:

π为初始状态概率向量:
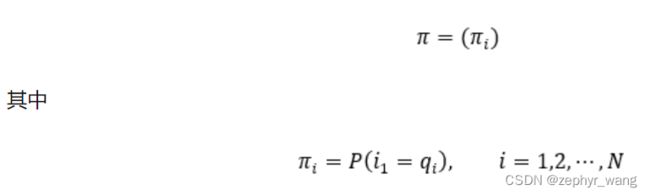
2.2.HMM的三假设
(1)齐次马尔可夫假设(一阶马尔可夫假设):任意时刻的状态只依赖前一时刻的状态;
(2)观测独立性假设:任意时刻的观测值只依赖当前时刻的状态,与其他状态及观测值无关;
(3)参数不变性假设:三要素不随时间的变化而变化,即三要素在整个训练过程中保持不变。
2.3.EM算法
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation-Maximization Algorithm)。EM算法的思想就是通过设置参数的初始值然后通过E步和M步不断迭代进行求解。
EM算法,是解决含有隐变量的参数估计问题。


2.4.Baum-Welch算法
鲍姆-韦尔奇算法Baum-Welch算法是用于寻找隐马尔可夫模型(HMM)未知参数的一种EM算法,它利用前向-后向算法来计算E-Step的统计信息。Baum-Welch算法是以其发明者Leonard E. Baum和Lloyd R. Welch的名字命名的。Baum-Welch算法和隐马尔可夫模型在20世纪60年代末和70年代初由Baum和他的同事在国防分析研究所的一系列文章中首次描述。
Baum-Welch是专门针对HMM情景下的EM算法。
3.Viterbi算法
维特比算法由安德鲁·维特比(Andrew Viterbi)于1967年提出,用于在数字通信链路中解卷积以消除噪音。维特比算法(Viterbi algorithm)是一种动态规划算法。它用于寻找最有可能产生观测事件序列的维特比路径——隐含状态序列。
语音(语音识别)中,声音信号作为观察到的事件序列,而文本字符串,被看作是隐含的产生声音信号的原因,因此可对声音信号应用维特比算法寻找最有可能的文本字符串。
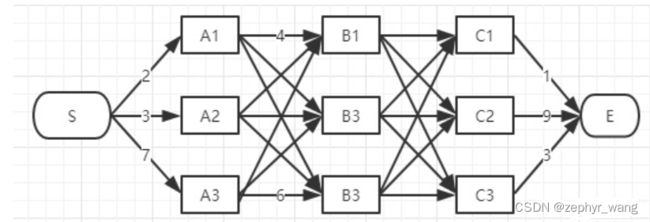
在效率方面相对于粗暴地遍历所有路径,viterbi 维特比算法到达每一列的时候都会删除不符合最短路径要求的路径。为了找出S到E之间的最短路径,我们先从S开始从左到右一列一列地来看。
4.GMM-HMM
4.1.MFCC
梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,简称MFCC)。
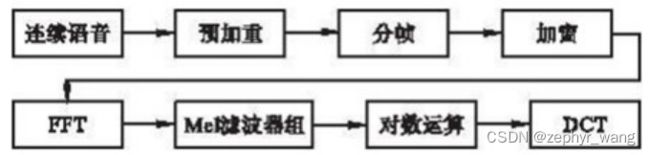
MFCC一般会经过这么几个步骤:预加重,分帧,加窗,快速傅里叶变换(FFT),梅尔滤波器组,离散余弦变换(DCT).其中最重要的就是FFT和梅尔滤波器组,这两个进行了主要的将维操作。
(1)预加重:预加重处理其实是将语音信号通过一个高通滤波器。目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱;同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
(2)分帧:为了方便对语音分析,可以将语音分成一个个小段,称之为:帧。先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
(3)加窗:将每一帧乘以汉明窗,以增加帧左端和右端的连续性。
(4)快速傅里叶变换(FFT):由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。
(5)受人耳蜗(cochlea)的启发——根据输入声音的不同,它会在不同的地方共振。而根据共振位置的不同,不同的神经元会向大脑发送不同的信号告诉大脑这个声音对应哪些频率。我们用周期图来估计功率谱就是为了达到类似的效果。
但是上面得到的功率谱仍然包含了很多对于语音识别无用的信息。比如耳蜗不会太细微的区分两个频率,尤其是对于高频的信号,耳蜗的区分度就越小。因此我们会把频率范围划分成不同的桶(bin),我们把所有落到这个桶范围内的能量都累加起来。这就是通过Mel滤波器组来实现的:第一个滤波器非常窄,它会收集频率接近0Hz的频率;而越往后,滤波器变得越宽,它会收集更大范围内的频率,具体频率范围是怎么划分的后面我们会介绍。
(6)接下来对于滤波器组的能量,我们对它取log。这也是受人类听觉的启发:人类对于声音大小(loudness)的感受不是线性的。为了使人感知的大小变成2倍,我们需要提高8倍的能量。这意味着如果声音原来足够响亮,那么再增加一些能量对于感知来说并没有明显区别。log这种压缩操作使得我们的特征更接近人类的听觉。为什么是log而不是立方根呢?因为log可以让我们使用倒谱均值减(cepstral mean subtraction)这种信道归一化技术(这可以归一化掉不同信道的差别)。
(7)最后一步是对这些能量进行DCT变换。因为不同的Mel滤波器是有交集的,因此它们是相关的,我们可以用DCT变换去掉这些相关性,从而后续的建模时可以利用这一点(比如常见的GMM声学模型我们可以使用对角的协方差矩阵,从而简化模型)。
4.2.语音识别
图1:

图2:

(1)预处理模块: 对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行相关变换处理。
(2)特征提取:提取出反映语音信号特征的关键特征参数形成特征矢量序列,常用的是由频谱衍生出来的Mel频率倒谱系数(MFCC)。
(3)声学模型建立或音素识别阶段.在该阶段我们采用高斯混合模型(Gaussian Mixture Model, GMM)来计算HMM的观测概率矩阵B。
(4)解码阶段,我们将声学模型和HMM的单词发音词典和语言模型结合来得到最优可能的文本序列.之前大部分的ASR系统都是用Viterbi算法进行解码。
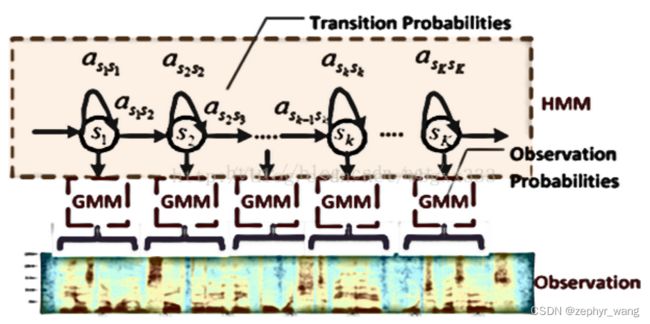
在GMM-HMM中,用高斯混合函数去拟合观测概率矩阵B的概率密度函数。如下图所示是一个GMM-HMM的模型框架示意图。
训练过程:
如下图,HMM的训练参数包括状态转移概率A和观测概率B(GMM的均值和方差)。

语音识别:

参考:
(1)GMM-HMM声学模型(深度解析)https://zhuanlan.zhihu.com/p/258826836
(2)第五讲 GMM-HMM模型学习笔记https://blog.csdn.net/weixin_44589825/article/details/126530299