基于深度卷积神经网络的ImageNet分类
基于深度卷积神经网络的ImageNet分类
文章目录
- 摘要
- 一、介绍
- 二、数据集
- 三、结构
-
- ReLU非线性
- 局部反应归一化
- 重叠集合
- 整体架构
- 数据扩张
- 总结
摘要
我们训练了一个大型的深度卷积神经网络,将ImageNet LSVRC-2010竞赛中的120万张高分辨率图像分为1000个不同的类。在测试数据上,我们实现了37.5%和17.0%的top-1和top-5错误率,这比之前的最先进的技术要好得多。该神经网络有6000万个参数和65万个神经元,由5个卷积层组成,其中一些层后面是最大池化层,还有3个全连接层,最后是1000路软最大。为了提高训练速度,我们使用了非饱和神经元和卷积运算的一个非常高效的GPU实现。为了减少全连接层中的过拟合,我们采用了一种最近开发的称为“dropout”的正则化方法,该方法被证明非常有效。我们还在ILSVRC-2012竞赛中输入了该模型的变体,并获得了15.3%的前5名测试错误率,而第二名的测试错误率为26.2%。
一、介绍
目前的目标识别方法主要使用机器学习方法。为了提高它们的性能,我们可以收集更大的数据集,学习更强大的模型,并使用更好的技术来防止过拟合。直到最近,标记图像的数据集都相对较小——大约有数万张图像(例如,NORB[16]、Caltech-101/256[8,9]和CIFAR-10/100[12])。这种规模的数据集可以很好地解决简单的识别任务,特别是如果用标签保存转换增强它们的话。例如,MNIST数字识别任务的当前最佳错误率(<0.3%)接近人类性能[4]。
但是,在现实环境中的物体表现出相当大的可变性,因此,为了学会识别它们,有必要使用更大的训练集。事实上,小图像数据集的缺点已经被广泛认识到(例如,Pinto et al[21]),但直到最近才有可能收集带有数百万张图像的标记数据集。新的更大的数据集包括LabelMe[23]和ImageNet[6],前者由数十万张完全分割的图像组成,后者由超过22000个类别的超过1500万张标记的高分辨率图像组成。
为了从数百万张图像中了解数千个物体,我们需要一个具有很大学习能力的模型。然而,对象识别任务的巨大复杂性意味着即使像ImageNet这样大的数据集也不能指定这个问题,因此我们的模型也应该有大量的先验知识来补偿我们没有的所有数据。卷积神经网络(CNNs)就是这样一类模型[16,11,13,18,15,22,26]。它们的容量可以通过改变它们的深度和宽度来控制,而且它们还对图像的本质(即统计的平稳性和像素依赖性的局部性)做出强有力的、大多数是正确的假设。
因此,与具有类似大小的层的标准前馈神经网络相比,cnn的连接和参数要少得多,因此更容易训练,而理论上最好的性能可能只是稍微差一点。
二、数据集
ImageNet是一个包含超过1500万张标记高分辨率图像的数据集,属于大约22000个类别。这些图片是从网上收集的,并由人工标记人员使用亚马逊的土耳其机械(Mechanical Turk)众包工具进行标记。从2010年开始,作为Pascal视觉对象挑战赛的一部分,一项名为ImageNet大规模视觉识别挑战赛(ILSVRC)的年度竞赛已经举行。ILSVRC使用ImageNet的一个子集,在1000个类别中每个类别大约有1000张图像。总共大约有120万张训练图像、5万张验证图像和15万张测试图像。
ILSVRC-2010是ILSVRC中唯一一个测试集标签可用的版本,因此这是我们进行大多数实验的版本。由于我们也在ILSVRC-2012竞赛中加入了我们的模型,在第6节中我们也报告了这个版本的数据集的结果,其中测试集的标签是不可用的。在ImageNet上,习惯上报告两个错误率:top-1和top-5,其中top-5错误率是测试图像中正确标签不在模型认为最可能的五个标签中的比例。
ImageNet由可变分辨率的图像组成,而我们的系统需要一个恒定的输入维度。因此,我们将图像采样到256 × 256的固定分辨率。给定一个矩形图像,我们首先缩放图像,使较短的一侧长度为256,然后从结果图像中裁剪出中心的256×256补丁。除了从每个像素中减去训练集的平均活动外,我们没有以任何其他方式预处理图像。所以我们在像素的原始RGB值(居中)上训练我们的网络。
三、结构
我们的网络体系结构如图2所示。它包含8个学习层——5个卷积层和3个完全连接层。
ReLU非线性
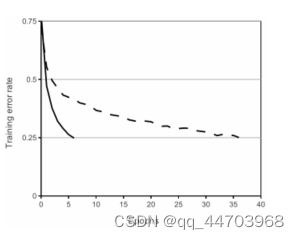
一个带有ReLU的四层卷积神经网络(实线)在CIFAR-10上达到25%的训练错误率,比带有tanh神经元的同等网络(虚线)快六倍。每个网络的学习率是独立选择的,以使训练尽可能快。没有采用任何形式的正则化。这里展示的效果的大小随网络结构而变化,但具有ReLU的网络始终比具有饱和神经元的同等网络快几倍。
局部反应归一化
ReLU有一个理想的特性,即它们不需要输入归一化来防止它们饱和。如果至少有一些训练实例对ReLU产生了积极的输入,学习就会在该神经元中发生。然而,我们仍然发现,以下的局部归一化方案有助于泛化。用aix,y表示一个神经元的活动,通过在位置(x,y)应用核i,然后应用ReLU非线性来计算,响应归一化的活动bix,y由以下表达式给出

重叠集合
CNN中的汇集层总结了同一核图中相邻的神经元组的输出。传统上,相邻的汇集单元所总结的邻域是不重叠的(例如,[17,11,4])。更准确地说,一个集合层可以被认为是由一个间隔为s像素的集合单元网格组成,每个集合单元总结的邻域大小为z×z,以集合单元的位置为中心。如果我们设定s = z,我们就得到了CNN中通常采用的传统的局部集合。如果我们设定s 现在我们准备描述我们的CNN的整体结构。如图2所示,该网络包含八个带权重的层;前五个是卷积层,其余三个是全连接层。最后一个全连接层的输出被送入一个1000路softmax,产生1000个类别标签的分布。我们的网络最大化了多叉逻辑回归的目标,这相当于最大化了预测分布下正确标签的对数概率的整个训练案例的平均值。 第二、第四和第五卷积层的内核只与前一层中位于同一GPU上的内核图相连(见图2)。第三卷积层的内核与第二层的所有内核图相连接。完全连接层的神经元与前一层的所有神经元相连。响应正常化层紧随第一和第二卷积层。第3.4节中描述的那种最大集合层,紧随反应正常化层以及第五卷积层。ReLU非线性被应用于每个卷积层和全连接层的输出。 减少图像数据过拟合的最简单和最常见的方法是使用标签保护的变换来人为地扩大数据集(例如,[25,4,5])。我们采用了两种不同形式的数据放大,这两种方法都允许以很少的计算量从原始图像中产生变换后的图像,因此变换后的图像不需要存储在磁盘上。 在我们的实施中,转换后的图像是在CPU上用Python代码生成的,而GPU正在对前一批图像进行训练。因此,这些数据增强方案实际上是无计算的。 数据增强的第一种形式包括生成图像的平移和水平反射。我们通过从256×256的图像中提取随机的224×224的斑块(和它们的水平反射),并在这些提取的斑块上训练我们的网络4。这使我们的训练集的大小增加了2048倍,当然,由此产生的训练实例是高度相互依赖的。如果没有这个方案,我们的网络就会出现严重的过拟合现象,这将迫使我们使用小得多的网络。在测试时,网络通过提取五个224×224的斑块(四个角斑块和中心斑块)以及它们的水平反射(因此总共有十个斑块)来进行预测,并对网络的softmax层对这十个斑块的预测进行平均。 数据增强的第二种形式包括改变训练图像中的RGB通道的强度。具体来说,我们对整个ImageNet训练集的RGB像素值的集合进行PCA。在每张训练图像中,我们添加所发现的主成分的倍数。 我们的结果表明,一个大型的深度卷积神经网络能够在一个极具挑战性的数据集上使用纯粹的监督学习取得破纪录的结果。值得注意的是,如果去掉一个卷积层,我们网络的性能就会下降。例如,去掉任何一个中间层,都会使网络的最高性能损失约2%。所以深度对于实现我们的结果真的很重要。 为了简化我们的实验,我们没有使用任何无监督的预训练,即使我们期望它能有所帮助,特别是如果我们获得足够的计算能力来大幅增加网络的规模而不获得相应的标记数据量的增加。到目前为止,我们的结果已经随着我们的网络规模的扩大和训练时间的延长而有所改善,但我们仍有许多数量级的工作要做,以便与人类视觉系统的近时路径相匹配。最终,我们希望在视频序列上使用非常大的深度卷积网络,因为时间结构提供了非常有用的信息,而这些信息在静态图像中是缺失的或不明显的。整体架构

数据扩张
总结