Transformer框架时间序列模型Informer内容与代码解读
Transformer框架时间序列模型Informer内容与代码解读
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
论文:https://arxiv.org/abs/2012.07436
代码:https://github.com/zhouhaoyi/Informer2020
#博学谷IT学习技术支持#
文章目录
- Transformer框架时间序列模型Informer内容与代码解读
- 前言
- 一、数据集
- 二、数据集的特种工程操作
-
- 1.标准化操作
- 2.时间信息转化
- 3.模型的输入
- 三、Encoder
-
- 1.Embedding
- 2.Encoder
- 四、Decoder
- 总结
前言
Transformer模型是当下最火的模型之一,被广泛使用在nlp,cv等各个领域之中。但是,用Transformer模型去解决时间序列问题却非常少见。本文是少有的用Transformer模型去解决长序列的时间预测问题。是AAAI 2021 Best Paper。内容比较新颖,尤其是提出了一种新的注意力层——ProbSparse Self-Attention和Distilling操作,在减少模型参数的同时大大提升模型的效果,值得在许多场合中借鉴。
一、数据集
论文提供了几种数据,我这以wth.csv为案例,其他的数据集也都差不多。

数据一共有35064条13列,其中第一列为时间,以每小时为单位。后12列为普通的column,进行多变量预测任务,也就是后12列既是作为特征X,也是需要预测的标签Y。
二、数据集的特种工程操作
论文主要对数据进行切割,分为训练集,验证集和测试集,其中训练集24544条(0 ~24544),验证集3508条(24448 ~28052),测试集7012条(27956 ~35064)。对数据进行了标准化操作,和提取第一列的时间数据,为了提取更多时间轴纬度的信息对其进行转换,1列转化成4列。
1.标准化操作
代码如下(示例):
class StandardScaler():
def __init__(self):
self.mean = 0.
self.std = 1.
def fit(self, data):
self.mean = data.mean(0)
self.std = data.std(0)
def transform(self, data):
mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.mean
std = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.std
return (data - mean) / std
def inverse_transform(self, data):
mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.mean
std = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.std
if data.shape[-1] != mean.shape[-1]:
mean = mean[-1:]
std = std[-1:]
return (data * std) + mean
2.时间信息转化
代码如下(示例):
class HourOfDay(TimeFeature):
"""Hour of day encoded as value between [-0.5, 0.5]"""
def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
return index.hour / 23.0 - 0.5
class DayOfWeek(TimeFeature):
"""Hour of day encoded as value between [-0.5, 0.5]"""
def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
return index.dayofweek / 6.0 - 0.5
class DayOfMonth(TimeFeature):
"""Day of month encoded as value between [-0.5, 0.5]"""
def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
return (index.day - 1) / 30.0 - 0.5
class DayOfYear(TimeFeature):
"""Day of year encoded as value between [-0.5, 0.5]"""
def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
return (index.dayofyear - 1) / 365.0 - 0.5
最后将其封装起来
dates = pd.to_datetime(dates.date.values)
return np.vstack([feat(dates) for feat in time_features_from_frequency_str(freq)]).transpose(1,0)
ps:这里的思路值得学习,特征工程非常重要,可以根据不同的业务场景,进行细分,比如加入季节,假期,促销季节等,进一步补充时间维度的信息,这些特征工程往往决定模型表现的上线,而模型本身只能逼近上线而已。
3.模型的输入
通过Dataloader getitem 函数对数据进行处理,模型输入分别为seq_x, seq_y, seq_x_mark, seq_y_mark。
seq_x的维度是96 12,代表12个特征和时间序列96(默认小时)。
seq_y的维度是72 12,代表12个特征和时间序列72(默认小时)。72个小时中,48个与seq_x重叠部分,另外24个是真正需要预测的标签Y。也就是说在模型decoder预测阶段,需要用时间系列前面的48个值也作为特征来带一带,提升模型的效果。
seq_x_mark的维度是96 4,代表4个前面通过时间信息转化的时间特征。
seq_y_mark的维度是72 4,同样代表y的时间特征。
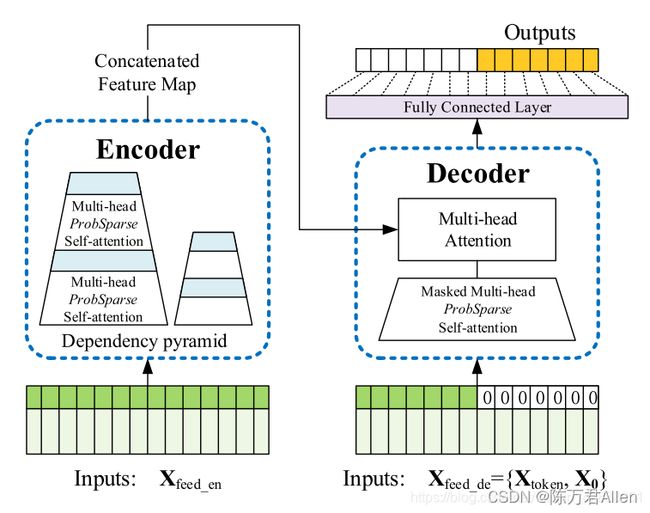
三、Encoder
1.Embedding
一般Transformer框架的第一层都是embedding,把各种特征信息融合在一起,本文作者从3个角度进行特征融合,分别是
- value_embedding
- position_embedding
- temporal_embedding
如图所示,数据的embedding由三个部分组成

代码如下(示例):
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular')
for m in self.modules():
if isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(m.weight,mode='fan_in',nonlinearity='leaky_relu')
def forward(self, x):
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1,2)
return x
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEmbedding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class TimeFeatureEmbedding(nn.Module):
def __init__(self, d_model, embed_type='timeF', freq='h'):
super(TimeFeatureEmbedding, self).__init__()
freq_map = {'h':4, 't':5, 's':6, 'm':1, 'a':1, 'w':2, 'd':3, 'b':3}
d_inp = freq_map[freq]
self.embed = nn.Linear(d_inp, d_model)
def forward(self, x):
return self.embed(x)
最后将其对应位置相加,得到最终的embedding,做法较为常规,通过1维的卷积层将embedding的输出映射成512
def forward(self, x, x_mark):
x = self.value_embedding(x) + self.position_embedding(x) + self.temporal_embedding(x_mark)
通过embedding之后模型的输出为32 96 512,其中32位batch size(默认32),96为时间序列长度,512为转换后的特征的维度。
2.Encoder
Encoder为本文核心内容,ProbSparse Self-Attention和Distilling两大核心内容。

def forward(self, queries, keys, values, attn_mask):
B, L, _ = queries.shape
_, S, _ = keys.shape
H = self.n_heads
queries = self.query_projection(queries).view(B, L, H, -1)
keys = self.key_projection(keys).view(B, S, H, -1)
values = self.value_projection(values).view(B, S, H, -1)
out, attn = self.inner_attention(
queries,
keys,
values,
attn_mask
)
这里第一步和正常的self-attention一样,对embedding的输出分别做3个线性转换,获得queries,keys,values,这里也是做多头的注意力机制,默认为8。这里的重点是如何利用queries,keys,values去做ProbSparse Self-Attention。
class ProbAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):
super(ProbAttention, self).__init__()
self.factor = factor
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)
# Q [B, H, L, D]
B, H, L_K, E = K.shape
_, _, L_Q, _ = Q.shape
# calculate the sampled Q_K
K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)
index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q
K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]
Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)
# find the Top_k query with sparisty measurement
M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)
M_top = M.topk(n_top, sorted=False)[1]
# use the reduced Q to calculate Q_K
Q_reduce = Q[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
M_top, :] # factor*ln(L_q)
Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k
return Q_K, M_top
def _get_initial_context(self, V, L_Q):
B, H, L_V, D = V.shape
if not self.mask_flag:
# V_sum = V.sum(dim=-2)
V_sum = V.mean(dim=-2)
contex = V_sum.unsqueeze(-2).expand(B, H, L_Q, V_sum.shape[-1]).clone()
else: # use mask
assert(L_Q == L_V) # requires that L_Q == L_V, i.e. for self-attention only
contex = V.cumsum(dim=-2)
return contex
def _update_context(self, context_in, V, scores, index, L_Q, attn_mask):
B, H, L_V, D = V.shape
if self.mask_flag:
attn_mask = ProbMask(B, H, L_Q, index, scores, device=V.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
attn = torch.softmax(scores, dim=-1) # nn.Softmax(dim=-1)(scores)
context_in[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
index, :] = torch.matmul(attn, V).type_as(context_in)
if self.output_attention:
attns = (torch.ones([B, H, L_V, L_V])/L_V).type_as(attn).to(attn.device)
attns[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], index, :] = attn
return (context_in, attns)
else:
return (context_in, None)
def forward(self, queries, keys, values, attn_mask):
B, L_Q, H, D = queries.shape
_, L_K, _, _ = keys.shape
queries = queries.transpose(2,1)
keys = keys.transpose(2,1)
values = values.transpose(2,1)
U_part = self.factor * np.ceil(np.log(L_K)).astype('int').item() # c*ln(L_k)
u = self.factor * np.ceil(np.log(L_Q)).astype('int').item() # c*ln(L_q)
U_part = U_part if U_part<L_K else L_K
u = u if u<L_Q else L_Q
scores_top, index = self._prob_QK(queries, keys, sample_k=U_part, n_top=u)
# add scale factor
scale = self.scale or 1./sqrt(D)
if scale is not None:
scores_top = scores_top * scale
# get the context
context = self._get_initial_context(values, L_Q)
# update the context with selected top_k queries
context, attn = self._update_context(context, values, scores_top, index, L_Q, attn_mask)
return context.transpose(2,1).contiguous(), attn
大家可以看一下ProbAttention里的forward函数
-
首先作者定义了一个变量U_part,这里默认为25,这个变量的意义在于,通过ProbAttention层,从96个长序列中,最终得到25个有价值的queries。
-
self._prob_QK 这个函数首先先从96个keys中随机抽样得到25个keys来代表所有keys的K_sample,然后用这些K_sample对所有的96个queries做内积,得到96个queries分别对应的25个keys值。每一个query这时候都对应25个key值,然后在25个key值中取最大值,再减去平均值,来作为每一个query的重要性。这样就可以得到96个queries的重要性。在更新values的时候,只更新25个重要的query,对应不重要的query则做平均。

-
self._get_initial_context 这个函数对其他非25个重要queries以外的values做平均值,这样可以减少参数的同时,剔除噪声。
-
self._update_context 这个函数完成attention 计算操作。最终得到输出。
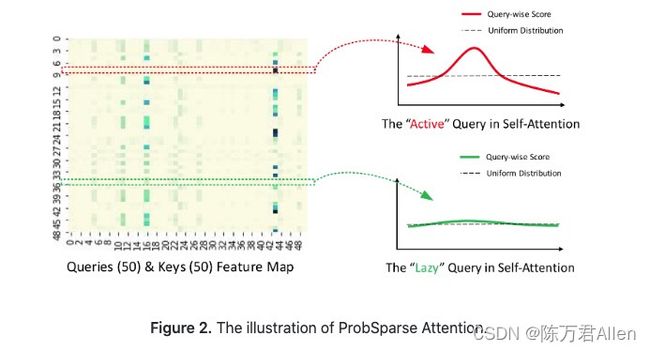
通过ProbSparse Self-Attention快速找到最有用的"Active" Query,剔除"Lazy" Query,用平均值来代替。
除了ProbAttention之外Distilling也是文章的另外一个创新。作者通过实验表明,经过下采样操作将96个输入长度,转换成48个之后,效果更好,所以模型类似梯队结构。
def forward(self, x):
x = self.downConv(x.permute(0, 2, 1))
x = self.norm(x)
x = self.activation(x)
x = self.maxPool(x)
x = x.transpose(1,2)
return x

其他的结构与一般的Transformer模型基本一样,也用到了残差连接,归一化,dropout等,来确保每一轮至少不比上一轮效果差。
四、Decoder
Decoder模块并无更多创新之处。和普通的Transformer模型一样,唯一的区别是在Decoder的输入中也用到了Encoder的42个值,用0作为真正需要预测的初始值。这样可以更好的提高模型的效果。
Mask机制用在Decoder的第一个attention层中,目的是为了保证t时刻解码的输出只依赖于t时刻之前的输出。
class TriangularCausalMask():
def __init__(self, B, L, device="cpu"):
mask_shape = [B, 1, L, L]
with torch.no_grad():
self._mask = torch.triu(torch.ones(mask_shape, dtype=torch.bool), diagonal=1).to(device)
@property
def mask(self):
return self._mask
class ProbMask():
def __init__(self, B, H, L, index, scores, device="cpu"):
_mask = torch.ones(L, scores.shape[-1], dtype=torch.bool).to(device).triu(1)
_mask_ex = _mask[None, None, :].expand(B, H, L, scores.shape[-1])
indicator = _mask_ex[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
index, :].to(device)
self._mask = indicator.view(scores.shape).to(device)
@property
def mask(self):
return self._mask
总结
文章通过ProbSparse Self-Attention和Distilling,对普通Self-Attention进行改进,不仅减少了参数,同时运用在时间序列的案例中,提高了模型的效果。
ProbSparse Self-Attention和Distilling能否运用在其他场景之中?比如cv nlp模型中,把Self-Attention都替代成ProbSparse Self-Attention和Distilling,因为都是Transformer机制,或者其他使用Transformer机制的架构中,效果也会有所提高吗?