分词算法介绍——千里之行,始于足下
NLP(自然语言处理),对于它来说,如何有效地编码一段文本,是它首先要考虑的问题。而在编码文本之前,要先把它切割成小块,这些小块叫做 tokens,这个过程叫做分词(tokenization)。所谓“千里之行,始于足下”,分词算法是NLP的起点,下面这一类算法做个总结。
单词、字符与子单词
第一个想法,可以以单词为单位进行切割,每个单词都是一个 token,这个想法叫做 Word Tokenization;第二个想法,可以以字符为单位进行切割,每个字母都是一个 token,这个想法叫做 Character Tokenization。
举个例子,要对 “I love you.” 进行分词:
- Word Tokenization gives: [‘I’, ‘love’, ‘you’, ‘.’]
- Character Tokenization gives:[‘i’, ‘l’, ‘o’, ‘v’, ‘e’, ‘y’, ‘o’ ‘u’, ‘.’]
Word Tokenization 的问题在于,它无法处理 Out Of Vocabulary (OOV) words。 拿过一段新的文本,如果其中包含词库中未出现的词,只能把它标记为 Unknown (UNK),这样无疑会影响神经网络的准确度。而 Character Tokenization 虽然解决了 OOV 问题,但是它过于冗长。把一些字母组合成一个有意义的单词已经很费功夫了,更遑论把单词组成有意义的句子。
于是人们想,能不能想个中间的法子?——这就是 Subword Tokenization。它把文本切割成一些“子单词”。举个例子,unhappy 可以切割成 [un, happy];disable 可以切割成 [dis, able] 。这样有什么好处呢?在训练 word embedding (更准确地说,token embedding)的时候,可以更容易捕捉单词前缀、后缀的含义,避免了重复捕捉信息。
更重要的一点,它在压缩数据的同时,减少了 UNK 的使用。
我们要按照什么标准切割子单词呢?下面介绍NLP领域常用的 Subword Tokenization 算法。
BPE
Hugging Face: Byte-Pair Encoding tokenization
Byte-Pair Encoding (BPE) 被广泛地用于 Transformer 架构中,如GPT、GPT-2、RoBERTa 等模型。
训练阶段:
从训练文本构成的字符集出发,在训练的每一步,寻找出现频率最高的 token pair (by “pair,” here we mean two consecutive tokens in a word),将它们合并;不断进行,直到 token 的数量达到预设的值。
分词阶段:
训练过程中,那些被合并的 token pair 被记录下来,用来对新来的文本进行分词。
举个栗子:
假设训练语料库如下,单词后的数字表示出现的次数
Vocabulary:["hug", "pug", "pun", "bun", "hugs"]
Corpus: ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
把每个单词都分解成字母,形成一个Base Vocabulary:
Base Vocabulary: ["b", "g", "h", "n", "p", "s", "u"]
Corpus: ("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
寻找出现频率最高的 token pair,发现是(“u”, “g”),它出现了20次。于是进行合并:(“u”, “g”) -> “ug”
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
重复上述步骤,这次(“u”, “n”) 的频率最高:
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
两次合并后,这次(“h”, “ug”) 频率最高:
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
假设算法到这里结束了,看一下学习到的“合并规则”:
("u", "g") -> "ug"
("u", "n") -> "un"
("h", "ug") -> "hug"
当有新的文本需要进行分词时,先将它分解成单个字母的序列,然后对照着这个合并规则进行合并。
比如单词 bug,分解成 [b, u, g];比对合并规则,发现 u, g 可以合并,且 b, ug 不能合并;因此 bug 的 分词结果是 [b, ug].
再比如单词 mug,它的分词结果是 [UNK, ug],因为 m 不在 Base Vocabulary 之中。
再比如单词 thug,它的结果是 [UNK, hug]
WordPiece
WordPiece 是 BERT 网络的分词算法,它和 BPE 很像,但有些许区别。
ps:WordPiece 的算法细节并没有开源,下面的算法过程是 Hugging Face 从论文描述中推断出来的:Hugging Face: WordPiece tokenization
训练阶段:
和 BPE 一样,WordPiece 的训练过程也是一个逐渐合并 token pair 的过程。但它用的合并准则有一些不一样。
score= (freq_of_pair) / (freq_of_first_element × freq_of_second_element)
BPE 只关心 token pair 的出现频率,即 freq_of_pair;WordPiece 还考虑了每个 token 的出现频率。
For instance, it won’t necessarily merge (“un”, “##able”) even if that pair occurs very frequently in the vocabulary, because the two pairs “un” and “##able” will likely each appear in a lot of other words and have a high frequency.
这里举了一个例子,即使 unable 出现频率很高,但如果 un 和 able 单个 token 的出现频率都很高,也不会合并它们,这也符合我们的预期。
训练阶段的其他部分与 BPE 相同。
分词阶段:
与 BPE 不同,WordPiece 不会保存训练阶段学到的“合并规则”,它只会保存最终的 Vocabulary。对于一个单词,从第一个字母开始,它会寻找 Vocabulary 中最长的子单词,进行切割;直到剩下的字母组成的 token 存在于 Vocabulary 中。
假设最终的 Vocabulary 如下(以 ## 开头的 token 表示该 token 不是单词的开头):
Vocabulary: ["b", "h", "p", "##g", "##n", "##s", "##u", "##gs", "hu", "hug"]
单词 hugs 的分词结果是 [“hug”, “##s”]
单词 bugs 的分词结果是 [“b”, "##u, “##gs”]
如果在某一步无法在 Vocabulary 中找到子单词,那么整个单词会被标记为 UNK,这一点和 BPE 不同,后者只会将不在 Vocabulary 中的 token 标记为 UNK;
比如 mug 就会被标记为 UNK,因为无法找到以 m 开头的 token。
Unigram
Unigram 是一种用于 AlBERT, T5, mBART 等模型的分词算法。它的思路和 BPE、WordPiece完全不同。
Hugging Face: Unigram tokenization
细节不再展开了,建议读 Hugging Face 的Tutorial。
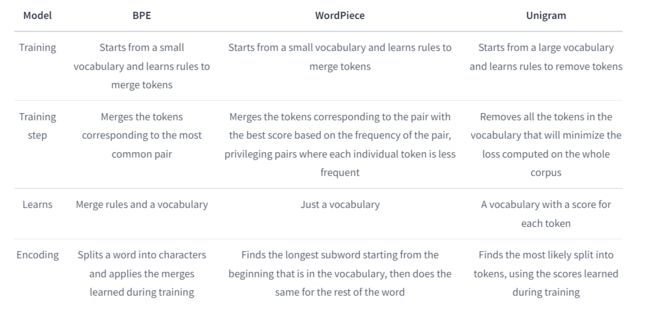
总结对比
SentencePiece
SentencePiece 是一个Python第三方库,专门用于分词,它支持BPE和Unigram算法。
SentencePiece 的编码特点是,它把空格作为一个正常的字符和文本一起编码(用_表示)。分词时,默认 _ 不会出现在 token 的中间位置,而只会出现在 token 的开头位置(即默认情况下,它不会把两个词的前后部分组合起来,组成一个 token)。
SentencePiece 没有提供预训练好的分词器。使用之前,必须先进行训练,这要求我们有一个较大的训练集。由于它的实现基于C++,训练速度倒是没什么问题。
import sentencepiece as spm
# train sentencepiece model from `botchan.txt` and makes `my_model.model` and `my_model.vocab`
# `my_model.vocab` is just a reference. not used in the segmentation.
spm.SentencePieceTrainer.train('--input=botchan.txt --model_prefix=my_model --vocab_size=2000')
# makes segmenter instance and loads the model file (my_model.model)
sp = spm.SentencePieceProcessor()
sp.load('my_model.model')
# encode: text => id
print(sp.encode_as_pieces('This is a test'))
print(sp.encode_as_ids('This is a test'))
# # decode: id => text
print(sp.decode_pieces(['▁This', '▁is', '▁a', '▁t', 'est']))
print(sp.decode_ids([209, 31, 9, 375, 586]))
输出结果为:
['▁This', '▁is', '▁a', '▁t', 'est']
[209, 31, 9, 375, 586]
This is a test
This is a test
由于 SentencePiece 在分词时保留了空格的位置信息,所以它的分词是可逆的:从编码后的 token list 可以轻松地还原原来的句子(只需要把 _ 替换为空格即可)。
注意到,训练时,我们指定了 --vocab_size,这是指目标 Vocabulary 的 token 数量。BPE 通过不断合并,会产生新的 token,而一旦 token 的数量达到我们设定的vocab_size,训练就会停止;而Unigram 通过不断去除 token,最终从另一个方向达到 vocab_size。
如果训练文件太大,可以指定 --input_sentence_size ,只选取一定数量的句子进行训练。
更多的细节,可以参考这个 colab tuto:Google colab page to run sentencepiece
值得一提的是,SentencePiece 是支持中文分词的。有人测试了在 SentencePiece 上的中文分词:SentencePiece的中文测试实践
中文分词工具
这位博主介绍了常用的中文分词工具,比如jieba,pyltp。我就借花献佛,不再费力气总结了:NLP笔记:中文分词工具简介