pytorch的dataset用法详解
torch.utils.data 里面的dataset使用方法
当我们继承了一个 Dataset类之后,我们需要重写 len 方法,该方法提供了dataset的大小; getitem 方法, 该方法支持从 0 到 len(self)的索引
from torch.utils.data import Dataset, DataLoader
import torch
class MyDataset(Dataset):
"""
下载数据、初始化数据,都可以在这里完成
"""
def __init__(self):
self.x = torch.linspace(11,20,10)
self.y = torch.linspace(1,10,10)
self.len = len(self.x)
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return self.len
# 实例化这个类,然后我们就得到了Dataset类型的数据,记下来就将这个类传给DataLoader,就可以了。
mydataset = MyDataset()#[return:
# # (tensor(x1),tensor(y1));
# # (tensor(x2),tensor(y2));
# # ......
train_loader2 = DataLoader(dataset=mydataset,
batch_size=5,
shuffle=False)
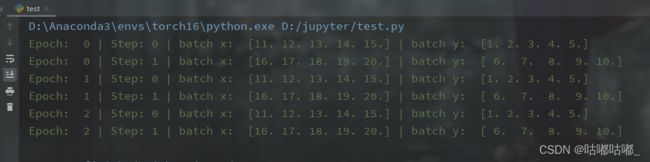
for epoch in range(3): # 训练所有!整套!数据 3 次
for step,(batch_x,batch_y) in enumerate(train_loader2): # 每一步 loader 释放一小批数据用来学习
#return:
#(tensor(x1,x2,x3,x4,x5),tensor(y1,y2,y3,y4,y5))
#(tensor(x6,x7,x8,x9,x10),tensor(y6,y7,y8,y9,y10))
# 假设这里就是你训练的地方...
# 打出来一些数据
print('Epoch: ', epoch, '| Step:', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
torchvision.datasets的使用方法
torchvision中datasets中所有封装的数据集都是torch.utils.data.Dataset的子类,它们都实现了__getitem__和__len__方法。因此,它们都可以用torch.utils.data.DataLoader进行数据加载。
用法1:使用官方数据集
可选数据集参考:https://www.pianshen.com/article/9695297328/
代码:torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
root (string): 表示数据集的根目录,其中根目录存在CIFAR10/processed/training.pt和CIFAR10/processed/test.pt的子目录
train (bool, optional): 如果为True,则从training.pt创建数据集,否则从test.pt创建数据集
download (bool, optional): 如果为True,则从internet下载数据集并将其放入根目录。如果数据集已下载,则不会再次下载
transform (callable, optional): 接收PIL图片并返回转换后版本图片的转换函数
target_transform (callable, optional): 接收PIL接收目标并对其进行变换的转换函数
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
用法2:ImageFolder通用的自己数据集加载器
一个通用的数据加载器,数据集中的数据以以下方式组织
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
torchvision.datasets.ImageFolder(root="root folder path", [transform, target_transform])
ImageFolder有以下成员变量:
- self.classes - 用一个list保存 类名
- self.class_to_idx - 类名对应的 索引
- self.imgs - 保存(img-path, class) tuple的list
该方法可以结合 torch.utils.data.Subset使用 ,以根据示例索引将您的ImageFolder数据集分为训练和测试。
orig_set = torchvision.datasets.Imagefolder('dataset/') # your dataset
n = len(orig_set) # total number of examples
n_test = int(0.1 * n) # take ~10% for test
test_set = torch.utils.data.Subset(orig_set, range(n_test)) # take first 10%
train_set = torch.utils.data.Subset(orig_set, range(n_test, n)) # take the rest