机器学习(实现决策树的创建和分类)
一:关于决策树:
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。决策树是基于树的结构进行决策,从根节点开始,沿着划分属性进行分支,直到叶节点。
1:结构:
1.1:决策点
是对几种可能方案的选择,即最后选择的最佳方案。如果决策属于多级决策,则决策树的中间可以有多个决策点,以决策树根部的决策点为最终决策方案。
1.2:状态节点
代表备选方案的经济效果(期望值),通过各状态节点的经济效果的对比,按照一定的决策标准就可以选出最佳方案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出现的自然状态数目每个分枝上要注明该状态出现的概率。
1.3:结果节点
将每个方案在各种自然状态下取得的损益值标注于结果节点的右端。
2:决策树构成要素(图像理解):决策结点、方案枝、状态结点、概率枝

3:决策树的一般流程
3.1收集数据:
任何方式收集。
3.2准备数据:
树构造算法只适用于标称型数据,因此数值型数据必须离散化
3.3分析数据:
可以使用任何方法,构造树之后,检查图形是否符合预期。
3.4训练算法:
构造树的数据结构。
3.5测试算法:
使用经验树计算错误率
3.6使用算法:
适用于任何监督学习算法,使用决策树可以更好理解数据的内在含义。
4:特征选择:
特征选择
特征选择是建立决策树之前十分重要步骤。随机地选择特征,建立决策树的学习效率将会大幅降低。而选择不同的特征,后续生成的决策树就会不一致,这种不一致最终会影响到决策树的分类效率。通常我们在选择特征时,会考虑到两种不同的指标,分别为:信息增益和信息增益比。要想弄清楚这两个概念,我们就不得不提到信息论中的另一个十分常见的名词:熵。熵(Entropy)是表示随机变量不确定性的度量。简单来讲,熵越大,随机变量的不确定性就越大。而特征 A 对于某一训练集 D 的信息增益g(D,A) 定义为集合 D 的熵H(D) 与特征 A 在给定条件下 D 的熵H(D/A) 之差。
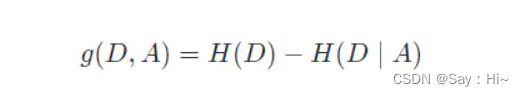
5:生成算法
经典算法就是John Ross Quinlan 提出的 ID3 算法,ID3 算法通过递归的方式建立决策树。建立时,从根节点开始,对节点计算每个独立特征的信息增益,选择信息增益最大的特征作为节点特征。接下来,对该特征施加判断条件,建立子节点。然后针对子节点再此使用信息增益进行判断,直到所有特征的信息增益很小或者没有特征时结束,这样就逐步建立一颗完整的决策树。其次一种算法叫 C4.5。C4.5 算法同样由 John Ross Quinlan 发明,但它使用了信息增益比来选择特征,这被看成是 ID3 算法的一种改进。
二:决策树的实现,创建与分类(以之前KNN使用数据集鸢尾花为例)
通过UCI 机器学习数据集网站下载该数据集:
from sklearn import datasets # 导入方法类
from sklearn.model_selection import train_test_split #使用scikit-learn 提供的训练集和数据集
from sklearn.tree import DecisionTreeClassifier #从 scikit-learn 中导入决策树分类器
from sklearn.metrics import accuracy_score#通过 scikit-learn 中提供的评估计算方法查看预测结果的准确度
iris = datasets.load_iris() # 加载 iris 数据集
iris_feature = iris.data # 特征数据
iris_target = iris.target # 分类数据查看分类数据:
iris_target 
feature_train(训练集特征), feature_test(测试集特征),target_train(训练集目标值), target_test(测试集目标值)test_size 参数代表划分到测试集数据占全部数据的百分比,random_state 参数表示乱序程度。整个训练集的 70% 为乱序数据。

用实验 fit 方法和 predict 方法对模型进行训练和预测
dt_model = DecisionTreeClassifier() # 所以参数均置为默认状态
dt_model.fit(feature_train,target_train) # 使用训练集训练模型
predict_results = dt_model.predict(feature_test) # 使用模型对测试集进行预测print('predict_results:', predict_results)
print('target_test:', target_test)
查看预测结果的准确度
print(accuracy_score(predict_results, target_test))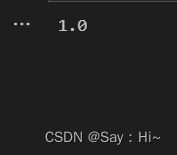
三:决策树优缺点:
优点:1、决策树算法易理解,机理解释起来简单。2、决策树算法可以用于小数据集。3、决策树算法的时间复杂度较小,为用于训练决策树的数据点的对数。4、相比于其他算法智能分析一种类型变量,决策树算法可处理数字和数据的类别。5、能够处理多输出的问题。6、对缺失值不敏感7、可以处理不相关特征数据。8、效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。缺点:1、对连续性的字段比较难预测。2、容易出现过拟合。3、当类别太多时,错误可能就会增加的比较快。4、在处理特征关联性比较强的数据时表现得不是太好。5、对于各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
转载自
四:总结
可知代码实现时两种准确度方法输入参数的区别,一般情况下,模型预测的准确度会和多方面因素相关,第一是数据集质量,本实验中,我们使用的数据集规范,几乎不包含噪声,所以预测准确度非常高。其次,模型的参数也会对预测结果的准确度造成影响。