YOLO系列模型笔记
滑动窗口和CNN
滑动窗口的目标检测,将检测问题转化为了图像分类问题。其基本原理是采用不同大小和比例的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口的对应区域进行分类。
缺点:不知道图像的物体是多大的规模,需要选择合适的步长,而且会产生很多子区域,都要经过分类器去预测,后来采用了SS网络去找到最有可能包含目标的子区域,这个思路被R-CNN借鉴,从而诞生了Fast R-CNN。
YOLOv1
首先将网络resize成448448的大小,送入CNN网络,将图像分割成ss个网格,然后每个网格去负责物体的中心点落到该网格的目标,每个网格会预测B的bbox以及置信度,边框的准确度用IOU来表示。
不管一个单元格预测多少个边界框,其只预测一组类别的概率。每个单元格需要预测(5B+C)个值,如果将图像划分为SS的大小,那么最终的预测值为SS(B5+c)大小的张量。
YOLOv1采用卷积网络提取特征,使用全连接层得到预测值,网络结构参考的GoogLeNet模型,包含24个卷积层和2个全连接层,得到7730(77*(25+20)2个预测框和20个分类)的张量,采用Leaky ReLu激活函数。
YOLOv1在backbone预训练采用的是224224,做检测任务时输入的图像是448*448。
缺点:
1、yolov1每个网络只能预测2个BBox,限制了预测相邻的物体的数量和小物体的情况。
1.1 每个网格处最终只会有一个输出,而不是B个输出(置信度最高的那一个),倘若一个网格包含了两个以上的物体,那必然会出现漏检问题。
2、yolov1直接从数据中学习预测BBox,很难推广到不同比例大小的物体。
YOLOv2
YOLOv2又叫YOLO9000,基于anchor box的单尺度目标检测网络,相比较与YOLOv1做了大量的改进和优化,不仅仅是对模型本身的优化,引入了Faster R-CNN的anchor box机制,使用kmeas聚类的方法获得更好的anchor box。
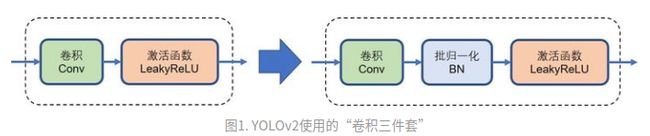
在YOLOv1中每一层卷积都是线形卷积和激活函数,没有使用归一化层,网络不能很好的表示非线形关系。于是YOLOv2的作者为YOLOv1添加了BN层,由原来的线形卷积与激活函数改进为线形卷积、BN层以及LeakyReLu激活函数。
网络结构的输入图像由448448改为了416416,去掉了YOLOv1中的最后一个池化层和所有的全链接层,修改了最大采样倍数为32,最终得到了13*13的网格,每个网格有k的anchor box,网络只需要学习先将先验框映射到真实框的尺寸偏移量即可。
作者设计了新的网络取代了原先的GoogLeNet网络风格,新的网络被命名为Darknet19,其中的卷积层为所提到的卷积三件套:线形卷积、BN层以及LeakyReLu激活函数,命名为Darknet19是因为其中有19个卷积层。在精度上Darknet19达到了VGG网络的水平,但是Darknet网络结构更小。尽管引入了anchor box但是网络的精度没有很大的提升,但是召回率有所提高,意味着YOLO可以找到更多的目标了。
引入了多尺度训练
缺点:
1、先验框严重依赖于数据,数据规模小、样本不够丰富会得到不足够的框,采用聚类出来的先验框不够好。
2、只使用了32倍采样的特征图,对于小目标的检测性能较差,降采样对小目标的损害显著大于大目标,直观的理解便是小目标的像素少于大目标,也就越难以经得住降采样操作的取舍,而大目标具有更多的像素,也就更容易引起网络的“关注”。
YOLOv3
YOLOv3第一处改进是更改了上对于YOLOv2的的backbone网络使用了更多的卷积层达到了53层,同时添加了残差网络中的残差结构,在DarkNet53中没有采用MaxPooling层,采用了stride为2的卷积层实现,卷积层仍然是三件套组件:线性卷积、BN层以及LeakyReLu激活函数。在ImageNet数据集上,DarkNet53与ResNet101和ResNet152的精度持平,但是速度更快。
引入FPN层(Feature Pyramid Networks ,特征金字塔),FPN层融合多个不同尺度的特征图进行目标检测,FPN工作认为网络浅层的特征图包含更多的细节信息,但语义信息较少,而深层的特征图则恰恰相反。
随着网络深度增增加,降采样操作增多,细节信息被破坏,导致小物体的检测效果逐渐变差,而大目标由于像素多,由于感受野不充分仅仅靠前几层网络不足于认识到大物体,随着网络层数增加,对大物体的认识越来越充分。
所以引入了一个方案:前层网络负责检测小目标,深层网络负责检测大目标。FPN将不同的尺度特征信息进行融合,多级检测应运而生,使用不同大小的特征图检测不同尺度的目标,不同尺度的物体由不同尺度的特征图去检测。
YOLOv3使用了FPN结构和多级检测方法,在3个尺度上进行预测,分别经过8、16、32倍采样,在每个特征图上每个网格放置3个先验框,由于使用3个尺度,一共设定9个先验框,仍然是使用kmeans获得。YOLOv3会输出52523(1+C+4)、26263(1+C+4)、13133(1+C+4)三个张量,然后汇总到一起,其中5252负责预测小物体、1313负责预测大物体。
YOLOv3相对于YOLOv2、YOLOv1主要就是增加了多尺度预测,
YOLOv4
YOLOv4引入了新的backbone:CSPDarkNet-53,核心采用了Cross Stage Partial Network结构,将网络的激活函数全部换成了Mish激活函数,YOLOv4的三个组件:Conv+Bn+Mish,增加了Dropblock,增加了CutMix、Mosaic、Label Smoothing等数据增强方式。
YOLOv4引入了新的Neck:PAN(Path Aggregation Network)结构,在原来YOLOv3中FPN的基础上增加了bottom-up结构。
YOLOv4最大的trick便是使用了Mosaic Augmentation,可以显著提升检测器的性能,尤其是小目标的性能。其核心思想就是随机将4张图像拼接在一起,图像中的目标都被缩小了,那么不难想到,马赛克增强可以有效提升小目标检测的性能。
Multi Anchor策略,YOLOv4便采用了Multi Anchor策略,即只要中心点处的anchor box与目标框的IoU超过了给定阈值,那就作为正样本,其他未负样本,这里不再有忽略样本的概念。
YOLOv4中会输出7676、3838、19*19的张量大小
Dropblock和Dropout功能类似,也是一种缓解过拟合的正则化方式,Dropout是随机减少神经元的数量,Dropblock是随机减少一块神经元的数量。
YOLOv5
YOLOv5自适应anchor计算、自适应图片缩放、CIOU_Loss,在YOLOv5中有两种CSP结构,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
YOLOv5的Neck和Yolov4中的一样,都是参用FPN+PAN的旧诶沟
YOLOX
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法,而采用了这两种数据增强,直接将Yolov3 baseline,都是采用Darknet53的网络结构。在YOLOX-DarkNet53中采用了Anchor Free的方式
YOLOv4相比较YOLOv3的改进
1、增加了很多训练的小traicks,输入端采用了MoSaic数据增强
2、BackBone主干网络采用了CSPDarkNet53
3、将YOLOv3的leakyrelu激活函数换成了Mish激活函数
4、学习率的变化,采用了余弦退火衰减的方法,也就是先上升再下降
5、损失函数的不同,在YOLOV4中使用的是CIOU Loss,YOLOv3采用的是交叉熵
YOLOv5和YOLOv4的区别
1、自适应anchor、自适应图片缩放
2、backBone采用了两个CSP结构
3、多种不同大小的网络结构YOLOv5s、YOLOv5m、YOLOv5l
4、激活函数YOLOv5采用的是leakyrelu和sigmoid
5、训练速度很快远超YOLOv4的速度
参考资料:
1、https://zhuanlan.zhihu.com/p/143747206
2、https://zhuanlan.zhihu.com/p/454472695