Python爬虫笔记
练习代码仓库地址
spider_test: python 爬chong练习
1.入门案例 ---输出某个网页的内容
#Python爬虫测试代码
# import urllib.request;
# response = urllib.request.urlopen('http://httpbin.org/get');
# print(response);
# html = response.read().decode();
# print(html);2.修改UA信息--伪装浏览器访问网页
#伪装浏览器访问代理
# url = "http://httpbin.org/get";
# headers = {
# 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0'
# }
# req = request.Request(url=url,headers=headers);
# res = request.urlopen(req);
# html = res.read().decode('utf-8')
# print(html);3.UA地址池以及第三方插件获取代理信息
UA地址池
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
' Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
' Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
4.URL编码和解码
query_string = {
'wd':'测试'
}
#对汉语进行编码操作
from urllib import parse
result = parse.urlencode(query_string)
url = 'https://www.baidu.com/s?ie=UTF-8&wd=?{}'.format(result)
print(url)
#使用quote方法进行编码操作
url = 'https://www.baidu.com/s?ie=UTF-8&wd=?{}'
word = input('请输入要搜索的内容:')
query_string = parse.quote(word);
print(url.format(query_string));

URL地址拼接方式
baseULR = 'https://www.baidu.com/s?'
params = 'wd=%E7%88%AC%E8%99%AB'
url = baseULR+params;
print(url)
req = request.urlopen(url);
html = req.read().decode("utf-8");
print(html);
#2.占位符
params="wd=%E7%88%AC%E8%99%AB"
url = 'https://www.baidu.com/s?%s'%params
print(url)
#3.format()方法
url = 'https://www.baidu.com/s?{}'
url = url.format(params);
print(url)正则相关
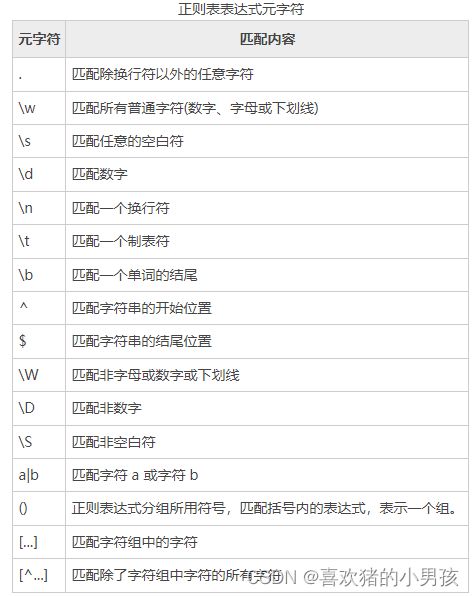

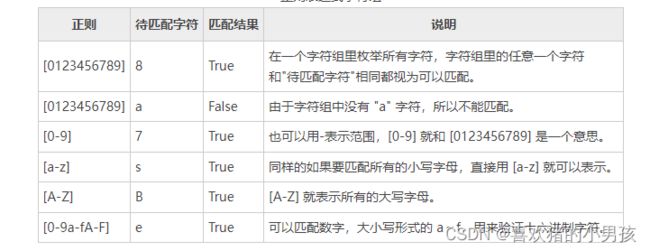


HTTP HTTPS
http就是服务器和客户端进行数据交互的一种形式。
常用的请求头信息
User-Agent:请求载体的身份标识
Connecion:请求完毕后,是断开连接还是保持连接
常用的响应头信息
Content-Type:服务器返回给客户端的数据类型
https协议
安全的超文本传输协议
加密方式
对称密钥加密
非对称密钥加密
证书密钥加密
基于request模块的爬虫
requests模块:python中原生的一款基于网络请求的模块,功能强大,简单便捷,效率极高
作用:该模块最重要的就是模拟浏览器发送请求
如何使用:
1. 指定URL
2. 发起请求
3. 获取响应数据
4. 持久化存储
环境安装
pip install requests
或者使用pycharm直接安装
数据解析
聚焦爬虫:爬取页面中指定的页面内容
1.基于正则表达式进行解析
2.基于bs4进行数据解析
3.xpath(*******)
数据解析原理:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
1.指定标签的定位
2.标签或者标签对应的属性中存储的数据值进行提取(解析)
编码流程
1.指定URL
2.发起请求
3.获取响应数据
4.数据解析
5.持久化存储
正则数据解析
case:爬取网络图片
#text字符串 content二进制 json()对象
requests.get(url=url).contentbs4进行数据解析
数据解析原理
标签定位
提取标签、标签属性中存储的数据值
bs4数据解析的原理
1.实例化一个BeautifulSoup对象,并且将页面源码加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
环境安装
pip install bs4
pip install lxml
如何实例化BeautifulSoup(l两种方式)
加载本地HTML文档
fp = open('../test/test.html', 'r', encoding='utf-8')
soup = BeautifulSoup(fp, 'lxml')加载网络上的HTML文档
page_text = response.text
soup = BeautifulSoup(page_text, 'lxml')====================提供的属性和方法====================
soup.标签类型:返回的是第一次出现的标签类型中的数据
soup.find("标签类型") : ---------------------
soup.find("标签类型",class_="song") 属性定位
soup.find_All():找到所有的符合条件的元素 而不是第一个
soup.select('.tang') 类似CSS中的选择器 参数为选择器 (同时空格代表多个层级关系 )
获取标签之间的文本数据
soup.a.text/string/get_text()
text/get_text()可以获取标签下的所有的文本内容
string只可以获取该标签下面直系的内容
获取标签中的属性值
soup.a['href']
xpath 解析 (支持与或非运算)
最常用也是最便捷最高效的一种解析方式 同时具有通用性
解析原理
1.实例化etree对象,并且需要将被解析的页面源码数据加载进去
2.调用etree对象中的xpath方法解析xpath表达式进行标签定位以及内容的捕获
环境安装
pip install lxml
实例化etree对象 from lxml import etree
1. 加载本地html
etree.parse(filePath)
2. 加载网络HTML
etree.parse(response)
xpath 表达式
/表示从根节点开始进行定位。表示的是一个层级
//表示的是多个个层级 用在开头则是从任意位置去定位div
//div[@class="song"] 属性定位写法
//div[@class="song"]/p[3] 索引定位 索引从1开始
取文本
在定位后添加/text()即可取出标签对应的文本列表 只能取直系内容
//text() 可以跨层级
取属性
/@attrname 即可取得属性值
中文乱码的两种方案
1. 直接更改页面编码
response = requests.get(url=url, headers=header)
# 解决中文乱码
response.encoding = 'utf-8'
page = response.text2.修改乱码部分
img_name = li.xpath('./a/img/@alt')[0] + '.jpg' # 通用处理中文乱码的解决方案 img_name.encode('iso-8859-1').decode('gbk')
云打码使用
识别验证码操作
1. 人工肉眼识别
2. 第三方自动识别验证码
云打码
登录操作可以使用即可爬取基于登录的页面或数据
session = requests.session
session.get(url,headers,params)
session.post(url,headers,params)代理理论讲解(破解IP封禁)
代理
代理服务器
代理的作用
突破自身IP访问的限制
隐藏自身真实IP
代理相关的网站
快代理
西祠代理
www.goubanjia.com
代理类型
http:
https:
使用方法
只需要在发起请求时,参数proxies={"http/https":'IP'}
高性能异步爬虫
1. 多线程 (不建议)
优点:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行
缺点:无法无限制的开启多线程或者多进程
2. 进程池、线程池 (适当的使用)
优点:降低系统对进程或者线程创建和销毁的频率,从而降低系统的开销
缺点:池中线程或者进程的数量具有一定的上限
主要代码实现:
from multiprocessing.dummy import Poolget_page 为封装的方法 name_list 为需要传递的迭代对象
pool.map(get_page, name_list)3. 单线程+异步协程(推荐)
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个时间循环上,当满足某些条件的时候,函数就会被循环执行。
coroutine:协程对象,我们可以将协程对象注册到事件循环中,它会被事件循环调用。我们可以使用async关键字来定义一个方法,当这个方法在调用时不会立即执行,而是返回一个协程对象
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态
future:代表将来执行或还没有执行的任务,实际上和task没有本质的区别
async 定义一个协程
await 用来挂起阻塞方法的执行
import asyncio
import time
async def request(url):
print('正在下载', url)
# time.sleep(2)
# 在异步协程中如果出现了同步模块相关的代码,那么就无法实现异步
# 当在asyncio中遇到阻塞操作 必须 进行手动挂起
await asyncio.sleep(2)
print('下载完毕', url)
start = time.time()
urls = [
'www.baidu.com',
'www.sougou.com',
'www.csdn.com'
]
# 任务列表:需要存放多个任务对象
tasks = []
for url in urls:
c = request(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
# 需要将任务列表封装到wait中 才可以加入任务循环
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)selenium模块的基本使用
1. 环境安装
pip install selenium
2. 下载浏览器的驱动程序
3. 实例化浏览器对象
4. 实现浏览器行为
其他的浏览行为
发起请求 get
标签定位 find_element/find_elements
标签交互 send_keys
执行js代码 excute_script
前进 回退 back forward
...
处理iframe
如果定位的标签存在于iframe标签中,则必须使用switch_to.frame(id)
动作链 from selenium.webdriver import ActionChains
实例化一个动作链对象 action = ActionChains(bro)
click_and_hold(div):长按且点击
move_by_offset(x,y)
perform() 动作链立即执行
action.release()释放动作链对象
selenium规避检测
from selenium.webdriver import EdgeOptions
# 实现规避检测
option = EdgeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
bro = webdriver.Edge(executable_path='./msedgedriver.exe', options=option)Scrapy框架
环境安装
pip install wheel
下载twisted
安装twidted
pip install pywin32
pip install scrapy
创建一个工程 scrapy startproject xxxPro
cd xxxPro
在splders目录中创建一个爬虫文件
scrapy genspider spiderName www.xxx.com
执行工程
scrapy crawl spiderName
注意: 在scrapy中使用xpath表达式获取页面元素时返回的是一个 selector
需要调用extract方法获取内容里列表
持久化存储
基于终端指令
只可以将parse方法的返回值存储到本地的文本文件中
scrapy crawl spliderName -o ./fileName
持久化存储保存的文件类型 只有 'json', 'jsonlines', 'jsonl', 'jl', 'csv', 'xml', 'marshal', 'pickle'
基于管道
编码流程
数据解析
在item类中定义相关的属性
将解析的数据封装存储到item类型的对象中
将item类型的对象提交给管道进行持久化存储操作
在管道类的process_item中要将其接收到的item对象存储的数据进行持久化存储
在配置文件中开启管道通信
解析到数据库中
管道文件中的一个管道类对应的是将数据存储到一个平台
怕中文件提交的item只会给管道文件中第一个被执行的管道类接收
第一个管道类通过return item 可以将内容返回给下一个管道类
对多个URL进行爬取
将所有的URL放入start_urls (不推荐)
手动的发起其他的请求
yield scrapy.Request(url=new_url, callback=self.parse)请求传参
使用场景:如果解析的数据不在用一张页面中。(深度爬取)
需求:爬取BOSS的岗位名称以及岗位描述
使用 scrapy.Request(,,meta{}) 传参
在自定义的解析函数中使用response.meta[‘attr’]即可获取响应的数据
图片数据爬取值ImagesPipeline
数据解析(图片的地址)
将存储图片地址的item提交到指定的基于ImagesPipeLine的管道类
重写下列方法
get_media_request()
file_path
item_completed
在配置文件中需要进行指定文件存储的目录
# 图片的存储路径
IMAGES_STORE = './imgs_baike'指定开启的管道 更改优先级
遇到的坑
如果没有执行自定义的图片管道类 , 一定要将LOG_LEVEL 调整为 WARNING级别
如果提示
WARNING: Disabled imgsPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
执行以下两条了命令
pip install pillow
pip install image
再次报错
Missing scheme in request url:
注意 在 spider中给item封装URL的时候一定要 将 url属性封装为list类型
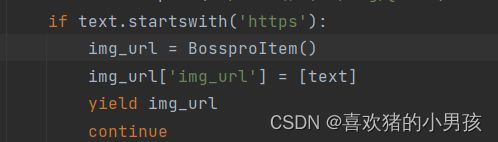
之后执行正常
中间件
下载中间件:处于引擎和下载器之间,可以拦截所有的请求和请求对象

作用:
拦截请求
UA伪装
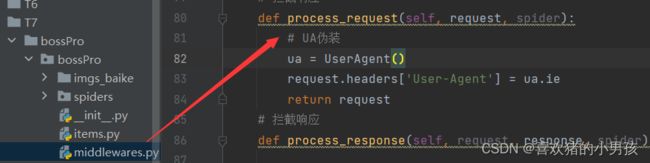
代理IP

拦截响应
篡改响应数据/响应对象
获取动态加载的数据
scrapy 配合 selenium 进行动态数据的获取
首先需要对响应的对象在中间件中进行拦截
同时获取URL地址栏,使用selenium进行浏览器响应对象的获取
最后将获取到的带有动态数据的response返回
下文代码的spider对象中的属性都是公共变量
# 通过该方法对五大板块的响应对象拦截,进行对应的篡改
def process_response(self, request, response, spider):
# 挑选出指定的响应对象进行响应的篡改
# 通过URL指定request
# 通过request对应response
# spider 表示的是爬虫对象 可以获取爬虫对象的属性和方法
print(spider.title_urls)
print(request.url)
if request.url in spider.title_urls:
# 五大板块的响应对象
# 实例化一个新地响应对象 (包含对应动态数据的响应对象)
# 获取动态加载的动态数据
# 基于seleium 可以便捷地获取动态数据
# 获取爬虫类中的bro浏览器对象
bro = spider.bro
bro.get(request.url)
sleep(5)
page_text = bro.page_source # 已经包含了动态加载的数据
new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return new_response
else:
return response # 其他URL的响应对象CrawlSpider Spider的一个子类
全站数据爬取的方式
基于Spider 手动请求
基于CrawlSpider
CrawlSpider 的使用流程
创建工程
cd xxx
创建爬虫文件
- scrapy genspider -t crawl xxx www.xxx.com
规则解析器:将链接提取器的链接进行指定的解析
分布式概述
我们需要搭建一个分布式的机群,让其对一组资源进行分布联合爬取
作用:提升爬取数据的效率
实现方法:
1. 安装scrapy-redis
原生的scrapy是不可以实现分布式爬虫,必须让scrapy结合scrapy-redis组件一起实现
无法共享调度器和管道
2. scrapy-redis 可以给原生的scrapy框架提供可以被共享的管道和调度器
创建工程
创建基于Crawlspider爬虫文件
修改当前的爬虫文件
1.导如from scrapy_redis.spiders import RedisCrawlSpider
2.将allow_domains 以及 start_urls 注释
3.添加一个redis_key = 'sun' 可以被共享的调度器队列的名称
4.编写数据解析的相关操作
5.将当前爬虫类的父类修改为RedisCrawlSpider
6.修改配置文件
指定使用可以被共享的管道:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline':400
}
执行可以被共享的调度器
# 去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 指定
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 清除redis中的队列
SCHEDULER_PERSIST = True
指定redis服务器 如果不指定 则默认是本机
REDIS_HOST = 'ip'
REDIS_PORT = port
REDIS_ENCODING = 'utf-8'
REDIS_PARAMS = {'pw':'xxxx'}
7.redis的相关操作配置
配置redis的配置文件
注释 bind 127.0.0.1 开启远程
关闭保护模式
prtected-mode yes 改为 no
8. 结合配置文件 开启redis
9. 执行工程
scrapy runspider xxx.py
10. 向调度器的队列中放入一个起始的url
打开redis-client
lpush xxx www.xxx.com