深度学习(5)——多层感知机
多层感知机
前言
感知机是一个古老的深度学习模型,由于它的不完美造成了一次AI寒冬。现在多层感知机就变得稍许完美一些了,不废话了…
之前学习了2个经典的回归算法,线性回归和softmax回归,他们都是用来预测结果的,但他们要求样本一定要有线性关系,就像房价与房屋属性必须有线性关系,这个就使得这两个算法的应用场景有点局限了,那么本文所谈的MLP(多层感知机)就可以解决一些非线性问题了。
原理
多层感知机的学习其实能让我们对神经网络有了更进一步的理解。
先来回顾一下之前softmax回归用到的神经网络图:
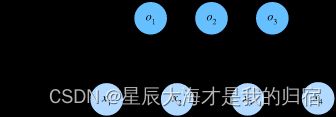
这题的背景就是n张图,一张图784个像素;n张图最终分成10类,这10类的每一类对于784的像素点都有各自的权重值。
当时输入层就是Rn*784,权重值就是W784*10,偏移量就是B1*10,那么输出层就是Rn*784点乘W784*10+B1*10=On*10回忆一下,这不就是单层神经网络嘛,输入层相当于就是784个神经节点,输出层就是10个神经节点,再看这个点乘公式,线性的吧,那么我们的MLP可以解决非线性问题,这个公式就要做一些改变了,接下来介绍。
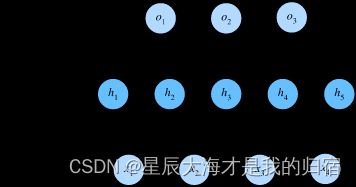
在MLP中加了个隐藏层,这里就放了一个隐藏层,搞清楚原理之后,这个深度可以自己按情况增加的。在softmax回归中等于是输入层点乘一下权值直接出结果了,那么MLP就是输入层点乘一下权重值加个偏移值输出到隐藏层,隐藏层再点乘另一组权重值再加另一组偏移值成为输出层。
还是那个784像素的例子,输入层至隐藏层:
输入层:Rn*784,权重值1:W1784*h,他们点乘的结果就是nh的形状对吧,那么这个h就是隐藏层神经元的个数了,这个隐藏层神经元个数算是个超参数,自己定义,通常是2n个神经元。偏移值1:B11*h。
Hn*h=Rn*784点乘W1784*h+B11*h
隐藏层至输出层:上面输出的H就是这里的输入层了,输入层:Hn*h,权重值2:W2h*10,这里点乘后的形状就是n10了,相当于输出层10个神经元,那么我们这个问题想要的结果也就是n幅图属于10个类别的概率,偏移值2:B21*10。
On*10=Hn*h点乘W2h*10+B21*10
这时发现好像和softmax那些回归相比不过就是加个中间层,这不还是线性嘛,接下来开始对公式优化让他非线性。
Hn*h=(Rn*784点乘W1784*h+B11*h)
On*10=Hn*h点乘W2h*10+B21*10
这个函数是啥,这个函数称之为激活函数,有3种常见形态可以实现非线性:
激活函数1:Relu
修正线性单元(Rectified linear unit,ReLU),公式非常简单,名字非常有逼格。
Relu(X)=max(0,X)
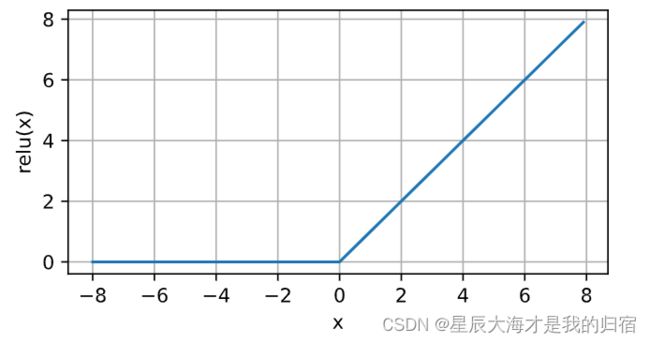
输入的x为正,导数为1,输入的x<=0,导数为0。
激活函数2:sigmoid函数
这个函数将使得最后的值在0到1之间波动,公式如下:
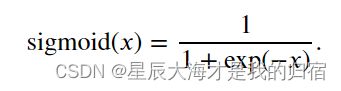
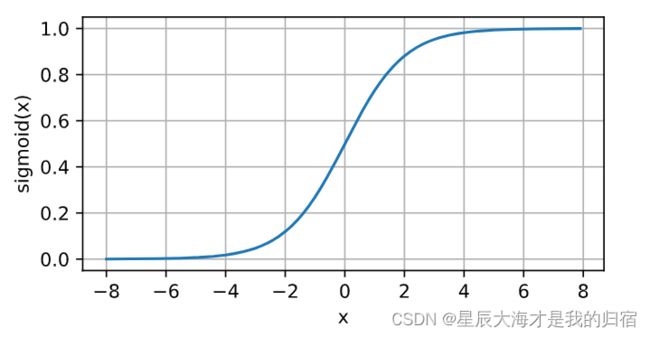
x值达到0时,导数为0.25,x值越偏离0,导数值越趋近0。
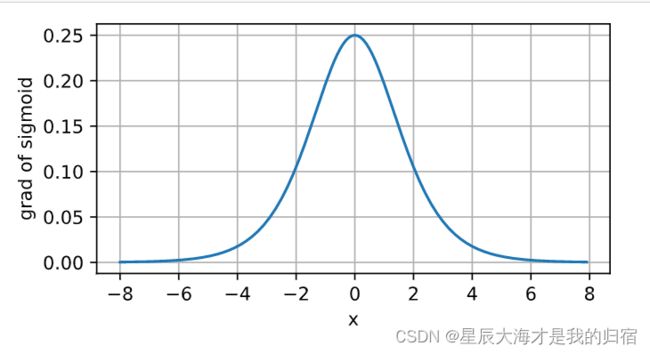
激活函数3:tanh函数
这个函数使得最后的值在-1至1之间,公式如下:

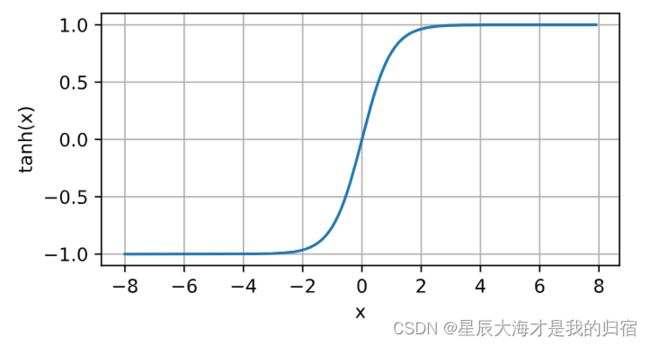
x值趋近0时,导数趋近1,x值越偏离0,导数值越趋近0。
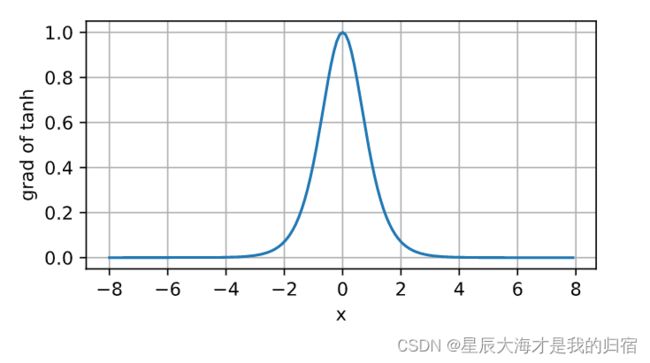
这三个激活函数套在Xw+b的外面,就使得原有公式不再具有线性的特点,最普遍使用的激活函数是Relu。
我们再回顾一下套用激活函数后的非线性神经网络公式:
Hn*h=(Rn*784点乘W1784*h+B11*h)
On*10=Hn*h点乘W2h*10+B21*10
接下来的步骤就和之前softmax回归的方式一样了,多次迭代,每一次迭代中都用随机梯度下降的方式对损失函数作优化,以获得最优的权重值和偏离值。
实现方法
导包
import torch
from torch import nn
from d2l import torch as d2l
数据集获取
还是使用softmax用到过的数据集,对几千张图分成10个类。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
这里我们用到的方法和原理中所举的例子一致,只建立一个隐藏层,那么就有2组权重和偏移。
再回顾一下原理中的2个公式,这里的参数就好理解了。
Hn*h=(Rn*784点乘W1784*h+B11*h)
On*10=Hn*h点乘W2h*10+B21*10
这里的w1w2b1b2都是对应的。
#输入层、输出层、隐藏层神经元个数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
#这里的随机函数使得数据符合正态分布,乘0.01使得权重更小一点那么方差也小一点
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
激活函数
这里使用Relu
def relu(X):
a = torch.zeros_like(X)#让a这个全0的矩阵和输入x的形状保持一致
return torch.max(X, a)
模型建立
def net(X):
#这里的原始数据实际上是3维的,就是n个二维数据,n个28*28的矩阵
#这句话就是将28*28的矩阵平铺成一维长度784的数据,变成n*784的形状
X = X.reshape((-1, num_inputs))
#输入层至隐藏层,加上激活函数使得它非线性
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
#隐藏层至输出层,这里不用relu函数了
return (H@W2 + b2)
这里可以看到如果要多个隐藏层,那么这里的函数可能要写很多行了,下个blog介绍的框架实现就方便很多了。
损失函数
这里的损失函数与softmax作了结合,上一个blog有介绍,这里直接使用
loss = nn.CrossEntropyLoss(reduction='none')
训练与预测
这两步实际上和softmax回归的方法一样,直接使用上篇的框架了。
#训练
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
#预测
d2l.predict_ch3(net, test_iter)
结果如下:
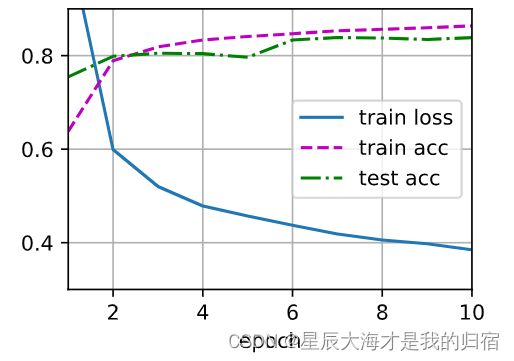
预测结果:
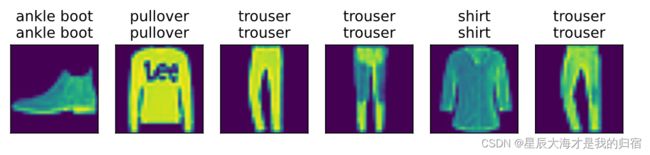
小结
通过MLP的学习,相信对神经网络有了一个很深入的理解,实际上我们不用每次都去搭建这个复杂的模型,下篇blog介绍框架实现MLP。