深度学习理论学习过程中的一些常见问题
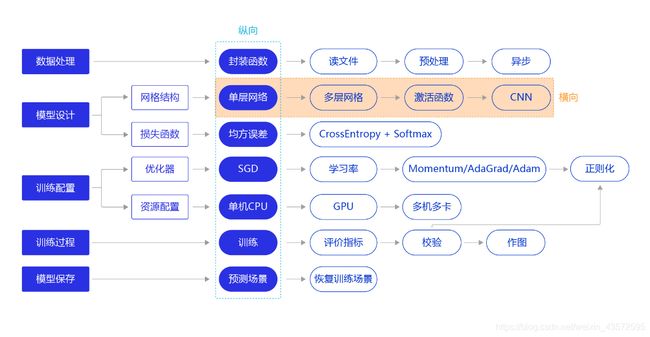
0. 需要去学习哪些基本内容
1. 样本归一化:预测时的样本数据同样也需要归一化,但使用训练样本的均值和极值计算,这是为什么?
答:可以从三个角度理解:众所周知,我们的数据集分为训练集和测试集,对于测试集的均值方差归一化,不能用测试集的均值和方差,而要用训练集的均值和方差,因为真实数据中很难得到其均值和方差。另外,网络参数是从训练集学习到的,也就是说,网络的参数尺度是与训练集的特征尺度一致性相关的,所以应该认为测试数据和训练数据的特征分布一致。最后,训练集数据相比测试集数据更多,用于近似表征全体数据的分布情况。
总结就是认为测试数据的分布应该与训练数据的分布一致。
例如样本A、样本B作为一批样本计算均值和方差,与样本A、样本C和样本D作为一批样本计算均值和方差,得到的结果一般来说是不同的。那么样本A的预测结果就会变得不确定,这对预测过程来说是不合理的。解决方法是在训练过程中将大量样本的均值和方差保存下来,预测时直接使用保存好的值而不再重新计算。
2. 当部分参数的梯度计算为0(接近0)时,可能是什么情况?是否意味着完成训练?
答:可能是到了局部最优。否。可以想象,下山路途中在半山腰碰到了一个又一个平台,平台处是平缓的,这里的梯度接近0,但是我们还没下到山的最底部。
3.随机梯度下降的batchsize设置成多少合适?过小有什么问题?过大有什么问题?提示:过大以整个样本集合为例,过小以单个样本为例来思考
答:batch过大,会增大内存消耗和计算时间,且训练效果并不会明显提升(因为每次参数只向梯度反方向移动一小步,所以方向没必要特别精确);batch过小,每个batch的样本数据将没有统计意义,计算的梯度方向可能偏差较大。
深度学习中的batch的大小对学习效果有何影响? - 程引的回答 - 知乎
https://www.zhihu.com/question/32673260/answer/71137399
4.模型选择应用原则
答:那么当我们需要将学术界研发的模型复用于工业项目时,应该如何选择呢?一个小建议:当几个模型的准确率在测试集上差距不大时,尽量选择网络结构相对简单的模型。往往越精巧设计的模型和方法,越不容易在不同的数据集之间迁移。
5. 数据加载器为什么要做成生成器?
答:同时,在返回数据时将Python生成器设置为yield模式,以减少内存占用。
6. 同步和异步数据读取
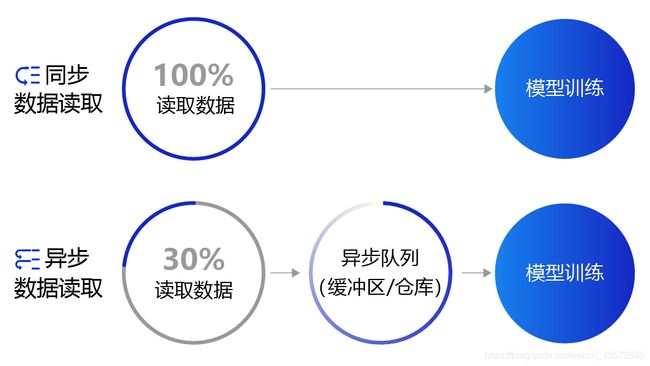
- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
深度学习框架中,通常需要定义datasets继承框架提供的数据集类,以及调用DataLoderAPI实现单线程/多线程加载。
7.为什么需要非线性激活函数
答:隐含层引入非线性激活函数Sigmoid是为了增加神经网络的非线性能力。因为如果没有非线性激活函数,整个网络展开后依旧是一个巨大的线性函数。
8.对于分类问题,为什么输出分类概率而不是具体的分类标签数值?
答:如果用不同的数值代表不同的类别,比如1到9表示不同的类别,输出预测结果也是0-9。计算loss的时候是不合理的:因为对于不同的类别应该是没有偏好的,上面说的这种方式会使得不同的分类错误对于loss的贡献不一致。比如label是1,但是分成了9,直接计算loss的结果很大。但是如果分成了2,loss却很小。但实际上2和9应该是同样的level。 当然,可以采用one-hot编码,使得类间距离一致。与此对应,真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。所以目前采用softmax算出不同概率,最后取最大概率对应的那个位置上编码为1。
9. 交叉熵损失的原理
答:基于极大似然的思想。交叉熵的公式如下:
L = − [ ∑ k = 1 n t k log y k + ( 1 − t k ) log ( 1 − y k ) ] L = -[\sum_{k=1}^{n} t_k\log y_k +(1- t_k)\log(1-y_k)] L=−[k=1∑ntklogyk+(1−tk)log(1−yk)]
其中, log \log log表示以 e e e为底数的自然对数。 y k y_k yk代表模型输出, t k t_k tk代表各个标签。 t k t_k tk中只有正确解的标签为1,其余均为0(one-hot表示)。
因此,交叉熵只计算对应着“正确解”标签的输出的自然对数。比如,假设正确标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是 − log 0.6 = 0.51 −\log 0.6 = 0.51 −log0.6=0.51;若“2”对应的输出是0.1,则交叉熵误差为 − log 0.1 = 2.30 −\log 0.1 = 2.30 −log0.1=2.30。由此可见,交叉熵误差的值是由正确标签所对应的输出结果决定的。
10.学习率与优化算法
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图2 右图所示。

图2: 不同学习率(步长过大/过小)的示意图
四种成熟的优化算法:
形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam,效果如 图3 所示。

图3: 不同学习率算法效果示意图
SGD 随机梯度下降算法,每次训练少量数据,抽样偏差导致的参数收敛过程中震荡。
Momentum 引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
AdaGrad 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
Adam 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
11. 分布式训练
分布式训练有两种实现模式:模型并行和数据并行。
- 模型并行(模型架构过大、网络模型的结构设计相对独立):模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的实现模式可以节省内存。
- 数据并行:数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的。得注意的是,每个设备的模型是完全相同的,但是输入数据不同,因此每个设备的模型计算出的梯度是不同的。如果每个设备的梯度只更新当前设备的模型,就会导致下次训练时,每个模型的参数都不相同。因此我们还需要一个梯度同步机制(CPU-PRC通信方式和GPU-NCCL2通信方式(Nvidia Collective multi-GPU Communication Library)。),保证每个设备的梯度是完全相同的。
分布式训练程序步骤:
1、初始化并行环境
2、对模型做并行化预处理(model->DataParallel(model))
3、定义训练的Reader,加载数据
4、loss计算梯度
启动多GPU的训练,有两种方式:
基于launch启动;
基于spawn方式启动。
12.优化调整的一些技巧
- 根据最终的指标,衡量模型训练效果
- 通过在Forward中加入打印语句输出模型特征层的输入输出定位问题
- 通过测试集判断泛化能力和过拟合情况
- 加入正则项避免过拟合(仅在优化器中设置weight_decay参数即可实现)
- 可视化分析 (通过matplotlib等绘图库进行绘制、利用可视化工具可视化日志)
13.模型保存与恢复
两种保存:
- 只保存模型用作预测评估使用:只保存模型及参数
- 需要恢复训练状态(因为有的优化器需要记录状态,比如AdaGrad):保存模型、参数和优化器的状态参数
# 保存模型参数和优化器的参数
save(model.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id)+'.pdparams')
save(opt.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id)+'.pdopt')
14.全连接神经网络的主要问题
- 空间位置关联性丢失
- 参数过多问题
15.卷积特点
- 参数权重共享
- 卷积操作保留(局部)空间信息
- 输入大小可变
2D卷积层的参数:nn.Conv2D (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode=‘zeros’, weight_attr=None, bias_attr=None, data_format=‘NCHW’)
一般把out_channels称作卷积核个数,但实际上卷积核的实际数目应该是in_channels×out_channels
16.池化的具体意义
最大池化和平均池化:
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。
17.梯度消失
在神经网络里,将经过反向传播之后,梯度值衰减到接近于零的现象称作梯度消失现象。
当 x x x为较大的正数的时候,Sigmoid函数数值非常接近于1,函数曲线变得很平滑,在这些区域Sigmoid函数的导数接近于零。当 x x x为较小的负数时,Sigmoid函数值也非常接近于0,函数曲线也很平滑,在这些区域Sigmoid函数的导数也接近于0。只有当 x x x的取值在0附近时,Sigmoid函数的导数才比较大。对Sigmoid函数求导数,结果如下所示:
d y d x = − 1 ( 1 + e − x ) 2 ⋅ d ( e − x ) d x = 1 2 + e x + e − x \frac{dy}{dx} = -\frac{1}{(1+e^{-x})^2} \cdot \frac{d(e^{-x})}{dx} = \frac{1}{2 + e^x + e^{-x}} dxdy=−(1+e−x)21⋅dxd(e−x)=2+ex+e−x1
从上面的式子可以看出,Sigmoid函数的导数 d y d x \frac{dy}{dx} dxdy最大值为 1 4 \frac{1}{4} 41。前向传播时, y = S i g m o i d ( x ) y=Sigmoid(x) y=Sigmoid(x);而在反向传播过程中, x x x的梯度等于 y y y的梯度乘以Sigmoid函数的导数,如下所示:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x \frac{\partial{L}}{\partial{x}} = \frac{\partial{L}}{\partial{y}} \cdot \frac{\partial{y}}{\partial{x}} ∂x∂L=∂y∂L⋅∂x∂y
使得 x x x的梯度数值最大也不会超过 y y y的梯度的 1 4 \frac{1}{4} 41。
由于最开始是将神经网络的参数随机初始化的, x x x的取值很有可能在很大或者很小的区域,这些地方都可能造成Sigmoid函数的导数接近于0,导致 x x x的梯度接近于0;即使 x x x取值在接近于0的地方,按上面的分析,经过Sigmoid函数反向传播之后, x x x的梯度不超过 y y y的梯度的 1 4 \frac{1}{4} 41,如果有多层网络使用了Sigmoid激活函数,则比较靠后的那些层梯度将衰减到非常小的值。
ReLU函数则不同,虽然在 x < 0 x\lt 0 x<0的地方,ReLU函数的导数为0。但是在 x ≥ 0 x\ge 0 x≥0的地方,ReLU函数的导数为1,能够将 y y y的梯度完整的传递给 x x x,而不会引起梯度消失。
18.批量归一化
批归一化方法(Batch Normalization,BatchNorm)是由Ioffe和Szegedy于2015年提出的,已被广泛应用在深度学习中,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定。
通常我们会对神经网络的数据进行标准化处理,处理后的样本数据集满足均值为0,方差为1的统计分布,这是因为当输入数据的分布比较固定时,有利于算法的稳定和收敛。对于深度神经网络来说,由于参数是不断更新的,即使输入数据已经做过标准化处理,但是对于比较靠后的那些层,其接收到的输入仍然是剧烈变化的,通常会导致数值不稳定,模型很难收敛。BatchNorm能够使神经网络中间层的输出变得更加稳定,并有如下三个优点:
-
使学习快速进行(能够使用较大的学习率)
-
降低模型对初始值的敏感性
-
从一定程度上抑制过拟合
BatchNorm主要思路是在训练时以mini-batch为单位,对神经元的数值进行归一化,使数据的分布满足均值为0,方差为1。
19.丢弃法
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
图 是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了 × \times ×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
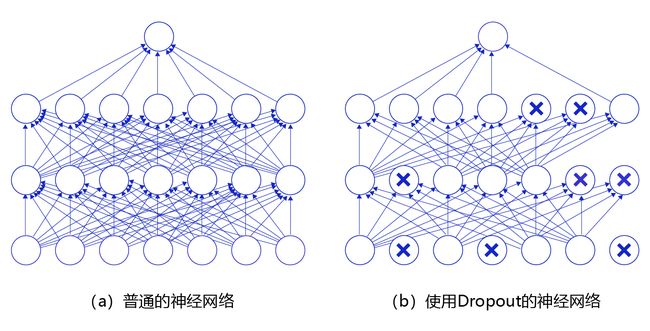
图 Dropout示意图
20.基础网络模块的发展思路?
LeNeT:卷积神经网络首次应用在图像识别数据集上,手写数字识别(5层)
AlexNet:通过网络的加深在ImageNet数据集上取得成功(8层)
VGG:简单重复3×3卷积基础块加深网络(16层)
GoogleNet:设计Inception模块扩宽网络获取不同的感受野
ResNet:残差块设计,使得网络可以更深
Transformer:从NLP发展而来的具有全局关联性的模块。