如何自定义代码生成器(上)
1 概述
1.1 介绍
在项目开发过程中,有很多业务模块的代码是具有一定规律性的,例如controller控制器、service接口、service实现类、mapper接口、model实体类等等,这部分代码可以使用代码生成器生成,我们就可以将更多的时间放在业务逻辑上。
传统的开发步骤:
创建数据库和表
根据表设计实体类
编写mapper接口
编写service接口和实现类
编写controller控制器
编写前端页面
前后端联调
基于代码生成器开发步骤:
创建数据库和表
使用代码生成器生成实体类、mapper、service、controller、前端页面
将生成好的代码拷贝到项目中并做调整
前后端联调
我们只需要知道数据库和表相关信息,就可以结合模版生成各个模块的代码,减少了很多重复工作,也减少出错概率,提高效率。
1.2 实现思路
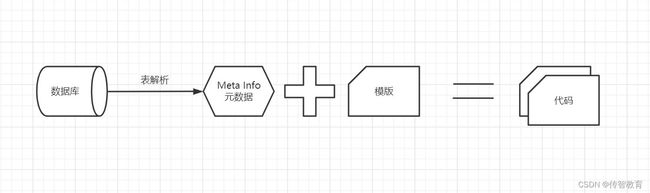
(1)需要对数据库表解析获取到元数据,包含表字段名称、字段类型等等
(2)将通用的代码编写成模版文件,部分数据需使用占位符替换
(3)将元数据和模版文件结合,使用一些模版引擎工具(例如freemarker)即可生成源代码文件
2 Freemarker
2.1 介绍
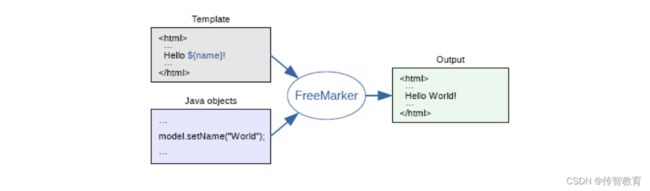
FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 它不是面向最终用户的,而是一个Java类库,是一款程序员可以嵌入他们所开发产品的组件。
模板编写为FreeMarker Template Language (FTL)。它是简单的,专用的语言, 在模板中,你可以专注于如何展现数据, 而在模板之外可以专注于要展示什么数据。
2.2 应用场景
(1)动态页面
freemarker可以作为springmvc一种视图格式,像jsp一样被浏览器访问。
(2)页面静态化
对于一些内容比较多,更新频率很小,访问又很频繁的页面,可以使用freemarker静态化,减少DB的压力,提高页面打开速度。
(3)代码生成器
根据配置生成页面和代码,减少重复工作,提高开发效率。
2.3 快速入门
(1)创建freemarker-demo模块,并导入相关依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.itheimagroupId>
<artifactId>freemarker-demoartifactId>
<version>1.0-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.1.RELEASEversion>
parent>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-freemarkerartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
project>
(2)application.yml相关配置
server:
port: 8881 #服务端口
spring:
application:
name: freemarker-demo #指定服务名
freemarker:
cache: false #关闭模板缓存,方便测试
settings:
template_update_delay: 0 #检查模板更新延迟时间,设置为0表示立即检查,如果时间大于0会有缓存不方便进行模板测试
suffix: .ftl #指定Freemarker模板文件的后缀名
(3)创建启动类
package com.heima.freemarker;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class FreemarkerDemotApplication {
public static void main(String[] args) {
SpringApplication.run(FreemarkerDemotApplication.class,args);
}
}
(4)创建Student模型类
package com.itheima.freemarker.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private Integer id;
private String name;//姓名
private Integer age;//年龄
private Date birthday;//生日
private Float money;//钱包
}
(5)创建StudentController
package com.itheima.freemarker.controller;
import com.itheima.freemarker.entity.Student;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import java.util.Date;
@Controller
@RequestMapping("student")
public class StudentController {
@GetMapping("index")
public String index(Model model){
//1.纯文本形式的参数
model.addAttribute("name", "Freemarker");
//2.实体类相关的参数
Student student = new Student();
student.setName("黑马");
student.setAge(18);
model.addAttribute("stu", student);
return "01-index";
}
}
(6)在resources/templates下创建01-index.ftl模版文件
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>首页title>
head>
<body>
<b>普通文本 String 展示:b><br/>
Hello ${name} <br>
<hr>
<b>对象Student中的数据展示:b><br/>
姓名:${stu.name}<br/>
年龄:${stu.age}
<hr>
body>
html>
(7)测试
浏览器访问 http://localhost:8881/student/index
效果如下

2.4 模版
2.4.1 基础语法种类
(1)注释,即<#-- -->,介于其之间的内容会被freemarker忽略
<#--我是一个freemarker注释-->
(2)插值(Interpolation):即 ${..} 部分,freemarker会用真实的值代替**${..}**
Hello ${name}
(3)FTL指令:和HTML标记类似,名字前加#予以区分,Freemarker会解析标签中的表达式或逻辑。
<# >FTL指令#>
(4)文本,仅文本信息,这些不是freemarker的注释、插值、FTL指令的内容会被freemarker忽略解析,直接输出内容。
<#--freemarker中的普通文本-->
我是一个普通的文本
2.4.2 if指令
if 指令即判断指令,是常用的FTL指令,freemarker在解析时遇到if会进行判断,条件为真则输出if中间的内容,否则跳过内容不再输出。
格式如下
<#if condition>
....
<#elseif condition2>
...
<#elseif condition3>
...
<#else>
...
#if>
需求:根据年龄输出所处的年龄段
童年:0岁—6岁(周岁,下同)
少年:7岁—17岁
青年:18岁—40岁
中年:41—65岁
老年:66岁以后
实例代码:
(1)在01-index.ftl添加如下代码
<#if stu.age <= 6>
童年
<#elseif stu.age <= 17>
少年
<#elseif stu.age <= 40>
青年
<#elseif stu.age <= 65>
中年
<#else>
老年
#if>
(2)测试
浏览器访问http://localhost:8881/student/index
效果如下

2.4.3 list指令
list指令时一个迭代输出指令,用于迭代输出数据模型中的集合
格式如下
<#list items as item>
${item_index + 1}------${item}-----<#if item_has_next>,#if>
#list>
迭代集合对象时,包括两个特殊的循环变量:
(1)item_index:当前变量的索引值。
(2)item_has_next:是否存在下一个对象
item_index 和 item_has_nex 中的item为<#list items as item> 中as后面的临时变量
需求:遍历学生集合,输出序号,学生id,姓名,所处的年龄段,是否最后一条数据
(1)在StudentController中增加方法
@GetMapping("list")
public String list(Model model) throws ParseException {
List<Student> list = new ArrayList<>();
list.add(new Student(1001,"张飞",15, null, 1000.11F));
list.add(new Student(1002,"刘备",28, null, 5000.3F));
list.add(new Student(1003,"关羽",45, null, 9000.63F));
list.add(new Student(1004,"诸葛亮",62, null, 10000.99F));
list.add(new Student(1005,"成吉思汗",75, null, 16000.66F));
model.addAttribute("stus",list);
return "02-list";
}
(2)在resources/templates目录下创建02-list.ftl模版
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>列表页面title>
<style>
table{
border-spacing: 0;/*把单元格间隙设置为0*/
border-collapse: collapse;/*设置单元格的边框合并为1*/
}
td{
border:1px solid #ACBED1;
text-align: center;
}
style>
head>
<body>
<table>
<tr>
<td>序号td>
<td>idtd>
<td>姓名td>
<td>所处的年龄段td>
<td>生日td>
<td>钱包td>
<td>是否最后一条数据td>
tr>
<#list stus as stu >
<tr>
<td>${stu_index + 1}td>
<td>${stu.id}td>
<td>${stu.name}td>
<td>
<#if stu.age <= 6>
童年
<#elseif stu.age <= 17>
少年
<#elseif stu.age <= 40>
青年
<#elseif stu.age <= 65>
中年
<#else>
老年
#if>
td>
<td>td>
<td>${stu.money}td>
<td>
<#if stu_has_next>
否
<#else>
是
#if>
td>
tr>
#list>
table>
<hr>
body>
html>
(2)测试
浏览器访问http://localhost:8881/student/list
效果如下

2.4.4 include指令
include指令的作用类似于JSP的包含指令,用于包含指定页,include指令的语法格式如下
<#include filename [options]>#include>
(1)filename:该参数指定被包含的模板文件
(2)options:该参数可以省略,指定包含时的选项,包含encoding和parse两个选项,encoding
指定包含页面时所使用的解码集,而parse指定被包含是否作为FTL文件来解析。如果省略了parse选项值,则该选项值默认是true
需求:“早上好,尊敬的 某某 用户!” 这句话在很多页面都有用到,请合理设计!
(1)在resources/templates目录下创建00-head.ftl模版,内容如下
早上好,尊敬的 ${name} 用户!
(2)在resources/templates目录下创建03-include.ftl模版,使用include引入00-head.ftl模版,内容如下
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>详情页title>
head>
<body>
<#include "00-head.ftl" />
<br>
欢迎来到黑马程序员。
body>
html>
(3)在StudentController中增加方法
@GetMapping("include")
public String include(Model model) throws ParseException {
model.addAttribute("name", "黑马");
return "03-include";
}
(4)测试
浏览器访问http://localhost:8881/student/include
效果如下
![]()
2.4.5 assign指令
它用于为该模板页面创建或替换一个顶层变量
<#assign name = "zhangsan" />
2.4.6 运算符
(1)算数运算符
FreeMarker表达式中完全支持算术运算,FreeMarker支持的算术运算符包括:
- 加法:
+ - 减法:
- - 乘法:
* - 除法:
/ - 求模 (求余):
%
(2)比较运算符
=或者==:判断两个值是否相等.!=:判断两个值是否不等.>或者gt:判断左边值是否大于右边值>=或者gte:判断左边值是否大于等于右边值<或者lt:判断左边值是否小于右边值<=或者lte:判断左边值是否小于等于右边值
比较运算符注意
- **
=和!=**可以用于字符串、数值和日期来比较是否相等 - **
=和!=**两边必须是相同类型的值,否则会产生错误 - 字符串
"x"、"x "、**"X"**比较是不等的.因为FreeMarker是精确比较 - 其它的运行符可以作用于数字和日期,但不能作用于字符串
- 使用**
gt等字母运算符代替>会有更好的效果,因为 FreeMarker会把>**解释成FTL标签的结束字符 - 可以使用括号来避免这种情况,如:
<#if (x>y)>
(3)逻辑运算符
- 逻辑与:&&
- 逻辑或:||
- 逻辑非:!
逻辑运算符只能作用于布尔值,否则将产生错误 。
2.4.7 空值处理
(1)缺失变量默认值使用 “!”
-
使用!要以指定一个默认值,当变量为空时显示默认值
例: ${name!‘’}表示如果name为空显示空字符串。
-
如果是嵌套对象则建议使用()括起来
例: ${(stu.bestFriend.name)!‘’}表示,如果stu或bestFriend或name为空默认显示空字符串。
(2)判断某变量是否存在使用 “??”
用法为:variable??,如果该变量存在,返回true,否则返回false
例:为防止stus为空报错可以加上判断如下:
<#if stus??>
<#list stus as stu>
......
#list>
#if>
2.4.8 内建函数
内建函数语法格式: 变量+?+函数名称
(1)求集合的大小
${集合名?size}
(2)日期格式化
显示年月日: ${today?date}
显示时分秒:${today?time}
显示日期+时间:${today?datetime}
自定义格式化: ${today?string("yyyy年MM月")}
(3)内建函数c
model.addAttribute(“point”, 102920122);
point是数字型,使用${point}会显示这个数字的值,每三位使用逗号分隔。
如果不想显示为每三位分隔的数字,可以使用c函数将数字型转成字符串输出
${point?c}
(4)将json字符串转成对象
一个例子:
其中用到了 assign标签,assign的作用是定义一个变量。
<#assign text="{'bank':'工商银行','account':'10101920201920212'}" />
<#assign data=text?eval />
开户行:${data.bank} 账号:${data.account}
(5)常见内建函数汇总
?html:html字符转义
?cap_first: 字符串的第一个字母变为大写形式
?lower_case :字符串的小写形式
?upper_case :字符串的大写形式
?trim:去掉字符串首尾的空格
?substring(from,to):截字符串 from是第一个字符的开始索引,to最后一个字符之后的位置索引,当to为空时,默认的是字符串的长度
?lenth: 取长度
?size: 序列中元素的个数
?int: 数字的整数部分(比如 -1.9?int 就是 -1)
?replace(param1,param2):字符串替换 param1是匹配的字符串 param2是将匹配的字符替换成指定字符
内建函数测试demo1
(1)在StudentController新增方法:
@GetMapping("innerFunc")
public String testInnerFunc(Model model) {
//1.1 小强对象模型数据
Student stu1 = new Student();
stu1.setName("小强");
stu1.setAge(18);
stu1.setMoney(1000.86f);
stu1.setBirthday(new Date());
//1.2 小红对象模型数据
Student stu2 = new Student();
stu2.setName("小红");
stu2.setMoney(200.1f);
stu2.setAge(19);
//1.3 将两个对象模型数据存放到List集合中
List<Student> stus = new ArrayList<>();
stus.add(stu1);
stus.add(stu2);
model.addAttribute("stus", stus);
// 2.1 添加日期
Date date = new Date();
model.addAttribute("today", date);
// 3.1 添加数值
model.addAttribute("point", 102920122);
return "04-innerFunc";
}
(2)在resources/templates目录下创建04-innerFunc.ftl模版页面:
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>inner Functiontitle>
head>
<body>
<b>获得集合大小b><br>
集合大小:${stus?size}
<hr>
<b>获得日期b><br>
显示年月日: ${today?date} <br>
显示时分秒:${today?time}<br>
显示日期+时间:${today?datetime}<br>
自定义格式化: ${today?string("yyyy年MM月")}<br>
<hr>
<b>内建函数Cb><br>
没有C函数显示的数值:${point} <br>
有C函数显示的数值:${point?c}
<hr>
<b>声明变量assignb><br>
<#assign text="{'bank':'工商银行','account':'10101920201920212'}" />
<#assign data=text?eval />
开户行:${data.bank} 账号:${data.account}
<hr>
body>
html>
(3)测试
浏览器访问http://localhost:8881/student/innerFunc
效果如下

内建函数测试demo2
需求:遍历学生集合,显示集合总条数,id不要逗号隔开,显示学生的生日(只显示年月日),钱包显示整数并显示单位元,用户姓名做脱敏处理(如果是两个字第二个字显示为星号,例如张三显示为张*,如果大于两个字,中间字显示为星号,例如成吉思汗显示为成*汗,诸葛亮显示为诸*亮)
(1)修改StudentController中的list方法,
@GetMapping("list")
public String list(Model model) throws ParseException {
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
List<Student> list = new ArrayList<>();
list.add(new Student(1001,"张三",15, dateFormat.parse("2007-10-01 10:00:00"), 1000.11F));
list.add(new Student(1002,"李四",28, dateFormat.parse("1994-10-01 10:00:00"), 5000.3F));
list.add(new Student(1003,"王五",45, dateFormat.parse("1977-10-01 10:00:00"), 9000.63F));
list.add(new Student(1004,"赵六",62, dateFormat.parse("1960-10-01 10:00:00"), 10000.99F));
list.add(new Student(1005,"孙七",75, dateFormat.parse("1947-10-01 10:00:00"), 16000.66F));
model.addAttribute("stus",list);
return "02-list";
}
(2)修改02-list.ftl模版
共${stus?size}条数据:输出总条数
stu.id后面加?c :id不需要逗号分割
stu.birthday后面加?date:生日只输出年月日
stu.money后面加?int:金额取整
姓名需要使用replace和substring函数处理
完整内容如下
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>列表页面title>
<style>
table{
border-spacing: 0;/*把单元格间隙设置为0*/
border-collapse: collapse;/*设置单元格的边框合并为1*/
}
td{
border:1px solid #ACBED1;
text-align: center;
}
style>
head>
<body>
共${stus?size}条数据
<table>
<tr>
<td>序号td>
<td>idtd>
<td>姓名td>
<td>所处的年龄段td>
<td>生日td>
<td>钱包td>
<td>是否最后一条数据td>
tr>
<#list stus as stu >
<tr>
<td>${stu_index + 1}td>
<td>${stu.id?c}td>
<td>
<#if stu.name?length=2>
${stu.name?replace(stu.name?substring(1), "*")}
<#else>
${stu.name?replace(stu.name?substring(1, stu.name?length-1), "*")}
#if>
td>
<td>
<#if stu.age <= 6>
童年
<#elseif stu.age <= 17>
少年
<#elseif stu.age <= 40>
青年
<#elseif stu.age <= 65>
中年
<#else>
老年
#if>
td>
<td>${stu.birthday?date}td>
<td>${stu.money?int}元td>
<td>
<#if stu_has_next>
否
<#else>
是
#if>
td>
tr>
#list>
table>
<hr>
body>
html>
(3)测试
浏览器访问http://localhost:8881/student/list
效果如下

2.4.9 静态化
(1)springboot整合freemarker静态化文件用法
编写springboot测试用例
package com.itheima.test;
import com.itheima.freemarker.FreemarkerDemoApplication;
import com.itheima.freemarker.entity.Student;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.FileWriter;
import java.io.IOException;
import java.util.*;
@SpringBootTest(classes = FreemarkerDemoApplication.class)
@RunWith(SpringRunner.class)
public class FreemarkerTest {
//注入freemarker配置类
@Autowired
private Configuration configuration;
@Test
public void test() throws IOException, TemplateException {
Template template = configuration.getTemplate("04-innerFunc.ftl");
/**
* 静态化并输出到文件中 参数1:数据模型 参数2:文件输出流
*/
template.process(getData(), new FileWriter("d:/list.html"));
/**
* 静态化并输出到字节输出流中
*/
//StringWriter out = new StringWriter();
//template.process(getData(), out);
//System.out.println(out.toString());
}
private Map getData(){
Map<String,Object> map = new HashMap<>();
Student stu1 = new Student();
stu1.setName("小强");
stu1.setAge(18);
stu1.setMoney(1000.86f);
stu1.setBirthday(new Date());
//小红对象模型数据
Student stu2 = new Student();
stu2.setName("小红");
stu2.setMoney(200.1f);
stu2.setAge(19);
//将两个对象模型数据存放到List集合中
List<Student> stus = new ArrayList<>();
stus.add(stu1);
stus.add(stu2);
//向model中存放List集合数据
map.put("stus",stus);
//map数据
Map<String,Student> stuMap = new HashMap<>();
stuMap.put("stu1",stu1);
stuMap.put("stu2",stu2);
map.put("stuMap",stuMap);
//日期
map.put("today",new Date());
//长数值
map.put("point",38473897438743L);
return map;
}
}
(2)freemarker原生静态化用法
package com.itheima.freemarker.test;
import com.itheima.freemarker.entity.Student;
import freemarker.cache.FileTemplateLoader;
import freemarker.cache.NullCacheStorage;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import freemarker.template.TemplateExceptionHandler;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.*;
public class FreemarkerTest {
public static void main(String[] args) throws IOException, TemplateException {
//创建配置类
Configuration CONFIGURATION = new Configuration(Configuration.VERSION_2_3_22);
//设置模版加载路径
//ClassTemplateLoader方式:需要将模版放在FreemarkerTest类所在的包,加载模版时会从该包下加载
//CONFIGURATION.setTemplateLoader(new ClassTemplateLoader(FreemarkerTest.class,""));
String path = java.net.URLDecoder.decode(FreemarkerTest.class.getClassLoader().getResource("").getPath(),"utf-8");
//FileTemplateLoader方式:需要将模版放置在classpath目录下 目录有中文也可以
CONFIGURATION.setTemplateLoader(new FileTemplateLoader(new File(path)));
//设置编码
CONFIGURATION.setDefaultEncoding("UTF-8");
//设置异常处理器
CONFIGURATION.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);
//设置缓存方式
CONFIGURATION.setCacheStorage(NullCacheStorage.INSTANCE);
//加载模版
Template template = CONFIGURATION.getTemplate("templates/04-innerFunc.ftl");
/**
* 静态化并输出到文件中 参数1:数据模型 参数2:文件输出流
*/
template.process(getModel(), new FileWriter("d:/list.html"));
/**
* 静态化并输出到字节输出流中
*/
//StringWriter out = new StringWriter();
//template.process(getData(), out);
//System.out.println(out.toString());
}
public static Map getModel(){
Map map = new HashMap();
//1.1 小强对象模型数据
Student stu1 = new Student();
stu1.setName("小强");
stu1.setAge(18);
stu1.setMoney(1000.86f);
stu1.setBirthday(new Date());
//1.2 小红对象模型数据
Student stu2 = new Student();
stu2.setName("小红");
stu2.setMoney(200.1f);
stu2.setAge(19);
//1.3 将两个对象模型数据存放到List集合中
List<Student> stus = new ArrayList<>();
stus.add(stu1);
stus.add(stu2);
map.put("stus", stus);
// 2.1 添加日期
Date date = new Date();
map.put("today", date);
// 3.1 添加数值
map.put("point", 102920122);
return map;
}
}
3 数据库元数据
3.1 介绍
元数据(Metadata)是描述数据的数据。
数据库元数据(DatabaseMetaData)就是指定义数据库各类对象结构的数据。
在mysql中可以通过show关键字获取相关的元数据
show status; 获取数据库的状态
show databases; 列出所有数据库
show tables; 列出所有表
show create database [数据库名]; 获取数据库的定义
show create table [数据表名]; 获取数据表的定义
show columns from <table_name>; 显示表的结构
show index from <table_name>; 显示表中有关索引和索引列的信息
show character set; 显示可用的字符集以及其默认整理
show collation; 显示每个字符集的整理
show variables; 列出数据库中的参数定义值
也可以从 information_schema库中获取元数据,information_schema数据库是MySQL自带的信息数据库,它提供了访问数据库元数据的方式。存着其他数据库的信息。
select schema_name from information_schema.schemata; 列出所有的库
select table_name FROM information_schema.tables; 列出所有的表
在代码中可以由JDBC的Connection对象通过getMetaData方法获取而来,主要封装了是对数据库本身的一些整体综合信息,例如数据库的产品名称,数据库的版本号,数据库的URL,是否支持事务等等。
DatabaseMetaData的常用方法:
getDatabaseProductName:获取数据库的产品名称
getDatabaseProductName:获取数据库的版本号
getUserName:获取数据库的用户名
getURL:获取数据库连接的URL
getDriverName:获取数据库的驱动名称
driverVersion:获取数据库的驱动版本号
isReadOnly:查看数据库是否只允许读操作
supportsTransactions:查看数据库是否支持事务
3.2 搭建环境
(1)导入mysql依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
(2)创建测试用例
package com.itheima.test;
import org.junit.Before;
import org.junit.Test;
import java.sql.*;
import java.util.Properties;
public class DataBaseMetaDataTest {
private Connection conn;
@Before
public void init() throws Exception {
Properties pro = new Properties();
pro.setProperty("user", "root");
pro.setProperty("password", "123456");
pro.put("useInformationSchema", "true");//获取mysql表注释
//pro.setProperty("remarksReporting","true");//获取oracle表注释
conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/?useUnicode=true&characterEncoding=UTF8", pro);
}
}
3.3 综合信息元数据
(1)获取数据库元信息综合信息
@Test
public void testDatabaseMetaData() throws SQLException {
//获取数据库元数据
DatabaseMetaData dbMetaData = conn.getMetaData();
//获取数据库产品名称
String productName = dbMetaData.getDatabaseProductName();
System.out.println(productName);
//获取数据库版本号
String productVersion = dbMetaData.getDatabaseProductVersion();
System.out.println(productVersion);
//获取数据库用户名
String userName = dbMetaData.getUserName();
System.out.println(userName);
//获取数据库连接URL
String userUrl = dbMetaData.getURL();
System.out.println(userUrl);
//获取数据库驱动
String driverName = dbMetaData.getDriverName();
System.out.println(driverName);
//获取数据库驱动版本号
String driverVersion = dbMetaData.getDriverVersion();
System.out.println(driverVersion);
//查看数据库是否允许读操作
boolean isReadOnly = dbMetaData.isReadOnly();
System.out.println(isReadOnly);
//查看数据库是否支持事务操作
boolean supportsTransactions = dbMetaData.supportsTransactions();
System.out.println(supportsTransactions);
}
(2)获取数据库列表
@Test
public void testFindAllCatalogs() throws Exception {
//获取元数据
DatabaseMetaData metaData = conn.getMetaData();
//获取数据库列表
ResultSet rs = metaData.getCatalogs();
//遍历获取所有数据库表
while (rs.next()) {
//打印数据库名称
System.out.println(rs.getString(1));
}
//释放资源
rs.close();
conn.close();
}
(3)获取某数据库中的所有表信息
@Test
public void testFindAllTable() throws Exception {
//获取元数据
DatabaseMetaData metaData = conn.getMetaData();
//获取所有的数据库表信息
ResultSet rs = metaData.getTables("库名", "%", "%", new String[]{"TABLE"});
//拼装table
while (rs.next()) {
//所属数据库
System.out.println(rs.getString(1));
//所属schema
System.out.println(rs.getString(2));
//表名
System.out.println(rs.getString(3));
//数据库表类型
System.out.println(rs.getString(4));
//数据库表备注
System.out.println(rs.getString(5));
System.out.println("--------------");
}
}
(4)获取某张表所有的列信息
@Test
public void testFindAllColumns() throws Exception {
//获取元数据
DatabaseMetaData metaData = conn.getMetaData();
//获取所有的数据库某张表所有列信息
ResultSet rs = metaData.getColumns("库名", "%", "表名","%");
while(rs.next()) {
//表名
System.out.println(rs.getString("TABLE_NAME"));
//列名
System.out.println(rs.getString("COLUMN_NAME"));
//类型码值
System.out.println(rs.getString("DATA_TYPE"));
//类型名称
System.out.println(rs.getString("TYPE_NAME"));
//列的大小
System.out.println(rs.getString("COLUMN_SIZE"));
//小数部分位数,不适用的类型会返回null
System.out.println(rs.getString("DECIMAL_DIGITS"));
//是否允许使用null
System.out.println(rs.getString("NULLABLE"));
//列的注释信息
System.out.println(rs.getString("REMARKS"));
//默认值
System.out.println(rs.getString("COLUMN_DEF"));
//是否自增
System.out.println(rs.getString("IS_AUTOINCREMENT"));
//表中的列的索引(从 1 开始
System.out.println(rs.getString("ORDINAL_POSITION"));
System.out.println("--------------");
}
}
3.4 参数元数据
参数元数据(ParameterMetaData):是由PreparedStatement对象通过getParameterMetaData方法获取而
来,主要是针对PreparedStatement对象和其预编译的SQL命令语句提供一些信息,ParameterMetaData能提供占位符参数的个数,获取指定位置占位符的SQL类型等等
以下有一些关于ParameterMetaData的常用方法:
getParameterCount:获取预编译SQL语句中占位符参数的个数
@Test
public void testParameterMetaData() throws Exception {
String sql = "select * from health.t_checkgroup where id=? and code=?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, "7");
pstmt.setString(2, "0003");
//获取ParameterMetaData对象
ParameterMetaData paramMetaData = pstmt.getParameterMetaData();
//获取参数个数
int paramCount = paramMetaData.getParameterCount();
System.out.println(paramCount);
}
3.5 结果集元数据
结果集元数据(ResultSetMetaData):是由ResultSet对象通过getMetaData方法获取而来,主要是针对由数据库执行的SQL脚本命令获取的结果集对象ResultSet中提供的一些信息,比如结果集中的列数、指定列的名称、指
定列的SQL类型等等,可以说这个是对于框架来说非常重要的一个对象。
以下有一些关于ResultSetMetaData的常用方法:
getColumnCount:获取结果集中列项目的个数
getColumnType:获取指定列的SQL类型对应于Java中Types类的字段
getColumnTypeName:获取指定列的SQL类型
getClassName:获取指定列SQL类型对应于Java中的类型(包名加类名
@Test
public void testResultSetMetaData() throws Exception {
String sql = "select * from health.t_checkgroup where id=?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, "7");
//执行sql语句
ResultSet rs = pstmt.executeQuery();
//获取ResultSetMetaData对象
ResultSetMetaData metaData = rs.getMetaData();
//获取查询字段数量
int columnCount = metaData.getColumnCount();
System.out.println("字段总数量:"+ columnCount);
for (int i = 1; i <= columnCount; i++) {
//获取表名称
System.out.println(metaData.getColumnName(i));
//获取java类型
System.out.println(metaData.getColumnClassName(i));
//获取sql类型
System.out.println(metaData.getColumnTypeName(i));
System.out.println("----------");
}
}
4 代码生成器环境搭建
4.1 创建maven工程
创建maven工程并导入以下依赖
<properties>
<java.version>11java.version>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<maven.compiler.source>11maven.compiler.source>
<maven.compiler.target>11maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.freemarkergroupId>
<artifactId>freemarkerartifactId>
<version>2.3.23version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.8version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.10version>
dependency>
dependencies>
目录结构如下