序列模型GRU介绍与python实现
LSTM实现:https://blog.csdn.net/weixin_44402973/article/details/100554874
为了克服RNN 无法很好处理远距离依赖,研究者提出了 LSTM,而 GRU 是LSTM 的一个变体,GRU 保持了 LSTM 的效果同时又使结构更加简单。LSTM和GRU是序列型数据处理单元。在如火如荼的深度学习应用中发挥着不可或缺的作用。比如:机器人写诗,自动生成摘要,自动写作,机器翻译等。在上一篇文章【如上链接】中我已经对LSTM进行了介绍,今天是2020.05.01,我来介绍LSTM的孪生姐妹GRU【Gated Recurrent Unit】,如图1。
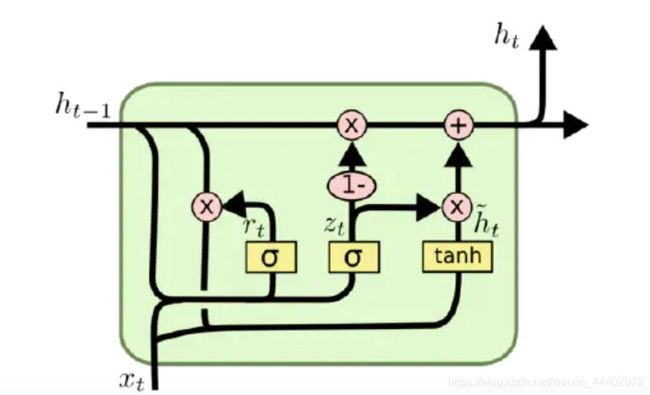
图1 GRU单元内部的实现
GRU和LSTM的比较
- 将LSTM中的遗忘门和输入门用单一的重置门(reset gate)替换,细胞状态的更新操作变为更新门(update gete);更新门用于控制前一时刻的状态信息被代入到当前状态的程,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
- gru参数少,比标准LSTM简单
如果![]() ,
,![]() ,那么gru和普通rnn的cell就是一样的。
,那么gru和普通rnn的cell就是一样的。
GRU前向传播
根据图1GRU的模型图,我们来看看网络的前向传播公式:
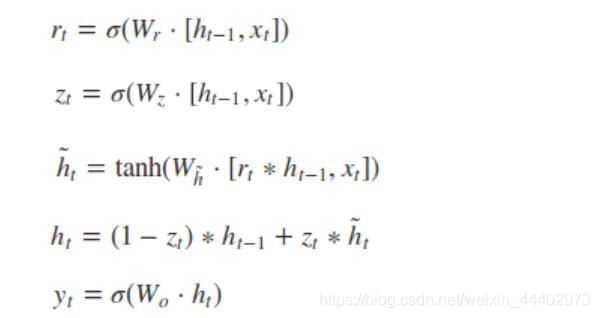
其中[]表示两个向量相连,*表示矩阵的乘积。
GRU代码实现(python)
def _generate_params_for_lstm_cell(x_size, h_size, bias_size):
"""generates parameters for pure lstm implementation."""
x_w = tf.get_variable('x_weights', x_size)
h_w = tf.get_variable('h_weights', h_size)
b = tf.get_variable('biases', bias_size,
initializer=tf.constant_initializer(0.0))
return x_w, h_w, b
with tf.variable_scope('gru_nn'):
'''LSTM实现'''
#hps.num_embedding_size:输入向量长度
#hps.num_lstm_nodes:lstm内部单元个数
with tf.variable_scope('reset'):
'''定义重置门'''
rx, rh, rb = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
with tf.variable_scope('update'):
'''定义更新门'''
zx, zh, zb = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
with tf.variable_scope('memory'):
'''中间状态'''
cx, ch, cb = _generate_params_for_lstm_cell(
x_size = [hps.num_embedding_size, hps.num_lstm_nodes[0]],
h_size = [hps.num_lstm_nodes[0], hps.num_lstm_nodes[0]],
bias_size = [1, hps.num_lstm_nodes[0]]
)
h = tf.Variable(
tf.zeros([batch_size, hps.num_lstm_nodes[0]]),
trainable = False
)
for i in range(num_timesteps):
# [batch_size, 1, embed_size]
embed_input = embed_inputs[:, i, :]
embed_input = tf.reshape(embed_input,
[batch_size, hps.num_embedding_size])
reset_gate = tf.sigmoid(
tf.matmul(embed_input, rx) + tf.matmul(h, rh) + rb)
update_gate = tf.sigmoid(
tf.matmul(embed_input, zx) + tf.matmul(h, zh) + zb)
mid_state = tf.tanh(
tf.matmul(embed_input, cx) + tf.matmul(h*reset_gate, ch) + cb)
h = (1-update_gate) * h + update_gate * mid_state
last = h总而言之,LSTM和CRU两者通过门控机制来保留之前序列的有用的信息,保证了在long-term传播的时候也不会丢失。与此同时,GRU相对于LSTM少了一个门函数,因此在参数的数量上要少于LSTM,所以整体上GRU的训练速度要快于LSTM的。