强化学习经典model-free方法总结
强化学习经典model-free方法总结
- 1. 基于值函数(value-based)的方法
-
- 1.1 sarsa
- 1.2 Q-learning
- 1.3 DQN
- 1.4 Double DQN
- 1.5 Dueling DQN
- 1.6 QR-DQN
- 1.7 Rainbow
- 2. 基于价值和策略(Actor-Critic)的方法
-
- 2.1 A2C和A3C
- 2.2 TRPO
- 2.3 PPO
- 2.4 SAC
- 2.5 DPG
- 2.6 DDPG
- 2.7 TD3
本文对强化学习的model-free经典方法做一个总结归纳,以便在使用方法或阅读文献时进行对比查找。本文的框架如图所示:

1. 基于值函数(value-based)的方法
1.1 sarsa
sarsa是on-policy、离散状态、离散动作的方法。这是很原始的方法,通常用一个Q表来存储state-action value.(有的翻译成状态动作价值,有的翻译成动作价值)。
核心公式为:
![]()
因为用于更新Q表的动作 a t + 1 a_{t+1} at+1是由 ϵ \epsilon ϵ-greedy策略(此时的策略又叫Target Policy)得到,而当前从Q表中采样的动作 a t a_t at也是由 ϵ \epsilon ϵ-greedy策略(此时的策略又叫Behavior Policy)得到,所以为on-policy方法。
关于如何判断on-policy和off-policy的讨论可以参考:强化学习之图解PPO算法和TD3算法
1.2 Q-learning
Q-learning是off-policy、离散状态、离散动作的方法。这也是很原始的方法,通常用一个Q表来存储state-action value。
核心公式为:

因为用于更新Q表的动作 a t + 1 a_{t+1} at+1是由greedy策略(完全贪婪策略)得到,而当前从Q表中采样的动作 a t a_t at也是由 ϵ \epsilon ϵ-greedy策略得到,所以为off-policy方法。
1.3 DQN
DQN是off-policy、连续状态、离散动作的方法。其思想源于Q-learning,进步之处在于使用了神经网络替代原来的Q表,来进行Q值的估计,且使用了experience replay的技术来打乱观测序列样本的强相关性,平滑了数据分布,从而使得神经网络能够收敛。
论文传送门:Human-level Control Through Deep Reinforcement Learning
网络更新思想为下图所示,详解请见强化学习番外(1)——图解DQN,DDQN,DDPG网络:
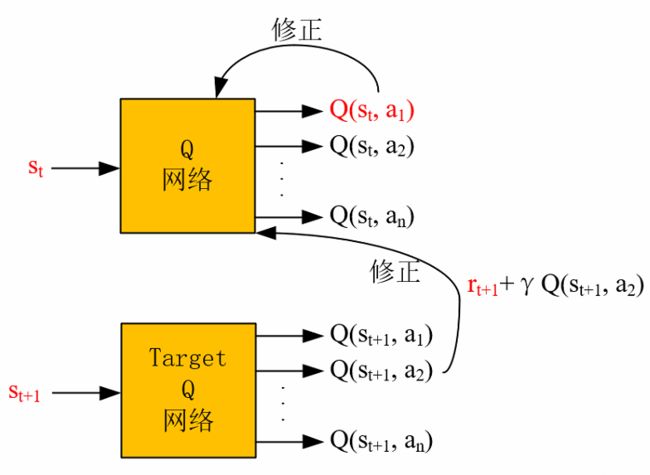
因为用于更新Q网络的价值 Q ( s t , a t ) Q(s_{t}, a_{t}) Q(st,at)中的 a t a_{t} at是由 ϵ \epsilon ϵ-greedy策略(此时的策略又叫Behavior Policy)得到,而从Target Q网络中得到的下一时刻的采样的价值 Q ( s t + 1 , a t + 1 ) Q(s_{t+1}, a_{t+1}) Q(st+1,at+1)是由greedy策略(此时的策略又叫Target Policy)得到,所以为off-policy方法。
1.4 Double DQN
Double DQN是off-policy、连续状态、离散动作的方法。相比于DQN,进步之处在于解决了DNQ中Q值过高估计的问题。
论文传送门:Deep reinforcement learning with double q-learning
网络更新思想为下图所示,详解请见强化学习番外(1)——图解DQN,DDQN,DDPG网络:

1.5 Dueling DQN
Dueling DQN是off-policy、连续状态、离散动作的方法。相比于DQN,进步之处能够使Q网络更好地收敛。因为针对动作价值 Q ( s t , a t ) Q(s_t,a_t) Q(st,at),传统的DQN算法直接进行Q值估计,而Dueling DQN则是将其拆分为两项: Q ( s t , a t ) = V ( s t ) + A ( s t , a t ) Q(s_t,a_t)=V(s_t)+A(s_t,a_t) Q(st,at)=V(st)+A(st,at),即状态价值函数 V ( s t ) V(s_t) V(st)和优势函数 A ( s t , a t ) A(s_t,a_t) A(st,at),这样的好处就是能够在 Q Q Q值相近的时候,通过拆解出来的 A ( s t , a t ) A(s_t,a_t) A(st,at)找到那个最优的动作。
论文传送门:Dueling network architectures for deep reinforcement learning
Dueling DQN网络架构思想为(摘自论文):
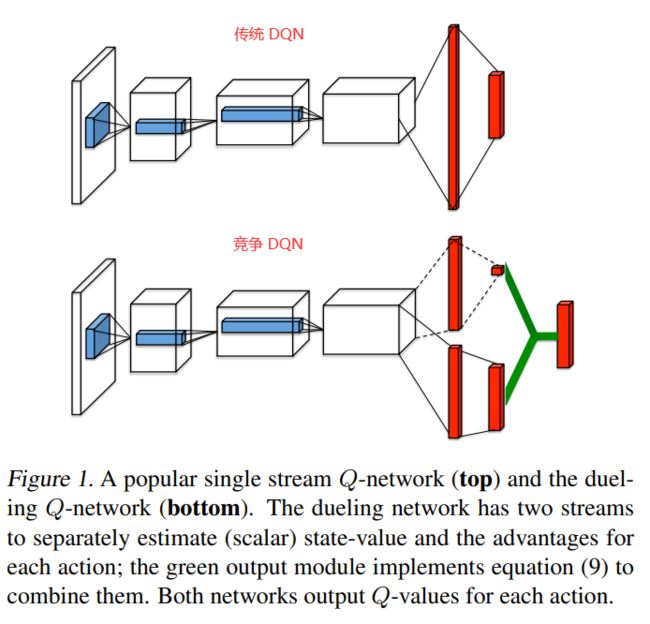
注意:Dueling DQN只是把DQN中的Q网络架构改得更加完善了,所以对DQN的其它改进完全可以用于Dueling DQN,比如Double DQN+Dueling DQN就是完全可行的,构成Dueling Double DQN算法,它是用于离散动作空间的较优算法。
1.6 QR-DQN
QR-DQN是对DQN的扩展,是off-policy、连续状态、离散动作的方法。
QR-DQN对DQN做了三个方面的修改:一是和DQN采用相似的网络结构,只是网络输出的size为 ∣ A ∣ × N | \mathcal{A} |\times N ∣A∣×N,其中 ∣ A ∣ | \mathcal{A} | ∣A∣是离散动作空间的动作数量, N N N是给定的分位数数量(这是超参);二是将Huber损失函数替换为Quantile Huber损失函数;三是将优化器RMSProp替换为 Adam 。
QR-DQN算法使用N个分位数去描述Q值分布,从而使用值分布而不是值函数。由于两者loss函数和bellman算子的相似性,QR-DQN可能遭遇到DQN相同的问题,比如过高的Q值估计等,因此对DQN的改进也可以用于QR-DQN。
论文传送门:Distributional Reinforcement Learning with Quantile Regression
详细介绍可以参考知乎文章:【DRL-7】Distributional DQN: Quantile Regression-DQN
Quantile Regression DQN算法的主要思路:

1.7 Rainbow
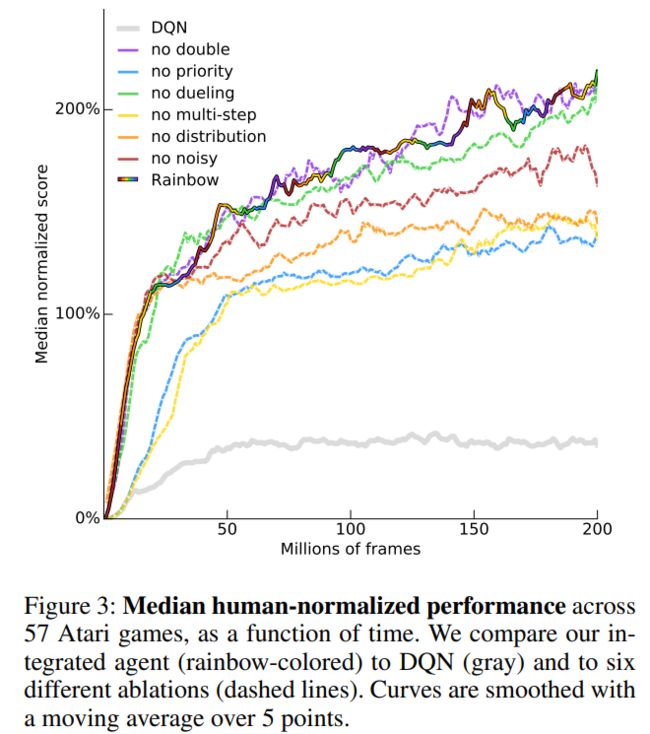
DeepMind团队针对六种DQN的改进方法进行消融实验,旨在探究哪些DQN改进技巧可以有效地融合,从而提升算法性能。
这六种分别是:
-
Double-DQN:将动作选择和价值估计分开,避免价值过高估计
-
Dueling-DQN:将Q值分解为状态价值和优势函数,得到更多动作的信息
-
Prioritized Replay Buffer:将经验池中的经验按照优先级进行采样
-
Multi-Step Learning:即TD(n)的思想,使得目标价值估计更为准确
-
Distributional DQN(Categorical DQN):得到价值分布
-
NoisyNet:增强模型的探索能力
论文传送门:Rainbow: Combining Improvements in Deep Reinforcement Learning
论文中的消融实验如下所示:
2. 基于价值和策略(Actor-Critic)的方法
单纯地基于策略(Policy-based)的方法,如VPG(Vanilla Policy Gradient)已经是很原始的策略梯度思想了,现在使用基于策略的方法都会带有价值估计网络,也就是构成Actor-Critic的结构。
策略梯度(Policy Gradient)算法中分为两大类,一类是随机性策略梯度(Stochastic Policy Gradient),一类是确定性策略梯度(Deterministic Policy Gradient)。两者的区别是,前者的策略网络输出的是动作概率,然后通过采样选择动作,而后者的策略网络则是直接输出一个确定的动作。
2.1 A2C和A3C
Advantage Actor-Critic 是连续状态、连续/离散动作的方法。其在Actor-Critic的基础上进行改进的地方为Critic网络不再是估计动作的Q值,而是估计动作的优势A值
Asynchronous Advantage Actor-Critic 是A2C的异步更新版本,即在多个环境实例中并行地执行多个智能体,来产生多样化的数据,异步更新的好处是避免了强化学习的数据之间的相关性,使得强化学习序列满足独立同分布,从而神经网络更好收敛,且异步的方法因不需要存储样本,其所需内存比不异步的方法少得多。不过在实际使用中A3C的效果并不理想。
A3C论文传送门:Asynchronous Methods for Deep Reinforcement Learning
2.2 TRPO
Trust Region Policy Optimization是随机性策略梯度方法,是on-policy、连续状态、连续动作的方法。它要解决的问题是确定一个合适的策略梯度更新的步长,使得回报函数的值单调不减。其总体思路为:首先证明最大化某个替代回报函数可以保证策略的单调不减改进,然后对这个理论上正确的替代算法进行一系列的近似,最后得到一个实用的算法。
论文传送门:Trust Region Policy Optimization
2.3 PPO
Proximal Policy Optimization 是随机性策略梯度方法,是on-policy、连续状态、连续动作的方法。它是TRPO算法的改进版本,其训练稳定,有更好的样本复杂性。
论文传送门:Proximal Policy Optimization Algorithms
网络更新思想请见强化学习之图解PPO算法和TD3算法。
2.4 SAC
Soft Actor-Critic 是随机性策略梯度方法,是off-policy、连续状态、连续动作的方法。相比于PPO算法,actor在最大化期望回报的时候还会最大化熵,也就是尽可能地随机地完成任务,保证动作的多样性。
此方法的作者发布了两篇文章,2018年1月的方法可以参考文章:强化学习之图解SAC算法,而2018年12月的方法
则是添加了一个自动调节温度超参数(automatically
tunes the temperature hyperparameter)的约束公式,以加速训练并提高超参数的稳定性。
两篇论文传送门:
2018年1月挂arXiv,8月被ICML收录,Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
2018年12月挂arXiv,Soft Actor-Critic Algorithms and Applications
2.5 DPG
Deterministic Policy Gradient 是确定性策略梯度方法,是off-policy、连续状态、连续动作的方法。DPG的策略网络只输出一个确定的action,通过加上人为指定的噪声来完成探索,在DPG中使用的是Actor-Critic方法。David Silver在论文中说道确定性策略梯度算法在高维动作空间中会优于随机性策略梯度算法。
论文传送门:Deterministic Policy Gradient Algorithms
2.6 DDPG
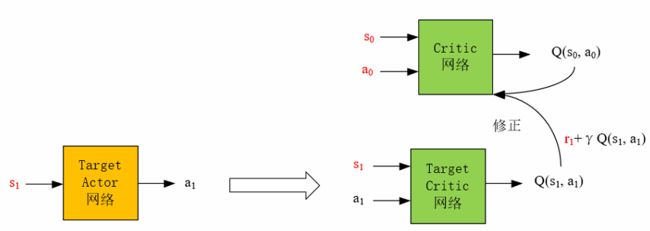
Deep Deterministic Policy Gradient 是确定性策略梯度方法,是off-policy、连续状态、连续动作的方法。它是DPG算法的深度学习版本,除了使用Actor-Critic方法外,还采用了soft update的方法来更新两个网络,使神经网络的训练稳定。
论文传送门:Continuous control with deep reinforcement learning
网络更新思想为下图所示,详解请见强化学习番外(1)——图解DQN,DDQN,DDPG网络:

2.7 TD3
Twin Delayed DDPG 是确定性策略梯度方法,是off-policy、连续状态、连续动作的方法。它是基于Double DQN的思想来改进DDPG,从而缓解Q值过高估计的问题。
TD3相比于DDPG有三个改进的地方:
一是 将一个Target Critic网络变为两个Target Critic网络,取两者较小的作为下一状态的Q值,从而避免Q值过高地被估计。
二是 对Target Actor 网络的输出进行了加噪声处理,从而使得Target Critic网络的预测输出Q值尽可能精确。
三是 采用了延迟软更新的方式去更新一个Target Actor 网络、两个Target Critic网络,以及采用延迟更新的方式更新Actor网络。
论文传送门:Addressing Function Approximation Error in Actor-Critic Methods
网络更新思想请见强化学习之图解PPO算法和TD3算法。