工业用电量ARIMA模型分析及预测
摘要
2005年到2017年每年的月度数据进行分析,建立ARIMA模型进行预测,预测假设下来5期的情况,。本文开始进行数据的预处理和对模型的建立情况进行判断,使用了R软件进行实际操作,对时间序列的自相关性和偏自相关性进行分析,残差的自相关检验,数据的平稳性检验等等方法,最终选定了ARIMA模型。
关键字:ARIMA模型、、时间序列、R
| 数据: |
|||||
| 时间 |
产量 |
时间 |
产量 |
时间 |
产量 |
| 2005-11 |
2041.9 |
2010-06 |
3466.6 |
2014-04 |
4250.22 |
| 2005-12 |
2246.6 |
2010-07 |
3776.4 |
2014-05 |
4415.94 |
| 2006-12 |
2573.4 |
2010-08 |
3903.3 |
2014-06 |
4580.71 |
| 2007-02 |
1967.3 |
2010-09 |
3486.5 |
2014-07 |
5047.94 |
| 2007-03 |
2472 |
2010-10 |
3328.8 |
2014-08 |
4959.31 |
| 2007-04 |
2474.5 |
2010-11 |
3453.4 |
2014-09 |
4541.72 |
| 2007-05 |
2568.7 |
2010-12 |
3677.8 |
2014-10 |
4446.41 |
| 2007-06 |
2715.6 |
2011-02 |
3100.8 |
2014-11 |
4487.21 |
| 2007-07 |
2915.7 |
2011-03 |
3830.1 |
2014-12 |
4902.18 |
| 2007-08 |
2989.8 |
2011-04 |
3663.8 |
2015-02 |
3653.85 |
| 2007-09 |
2760.1 |
2011-05 |
3775.4 |
2015-03 |
4510.61 |
| 2007-10 |
2727.9 |
2011-06 |
3968.2 |
2015-04 |
4450.26 |
| 2007-11 |
2754.7 |
2011-07 |
4251.5 |
2015-05 |
4562.1834 |
| 2007-12 |
2946.9 |
2011-08 |
4260.4 |
2015-06 |
4745.269 |
| 2008-02 |
2337.8 |
2011-09 |
3860.6 |
2015-07 |
5089.6199 |
| 2008-03 |
2897.8 |
2011-10 |
3640.4 |
2015-08 |
5155.3144 |
| 2008-04 |
2814.3 |
2011-11 |
3713 |
2015-09 |
4547.7566 |
| 2008-05 |
2933.8 |
2011-12 |
4038.1 |
2015-10 |
4453.546 |
| 2008-06 |
2934.5 |
2012-03 |
4109.2 |
2015-11 |
4660.4077 |
| 2008-07 |
3195.4 |
2012-04 |
3718.2 |
2015-12 |
4910.3326 |
| 2008-08 |
3160.6 |
2012-05 |
3898.1 |
2016-03 |
4778.8429 |
| 2008-09 |
2892.5 |
2012-06 |
3933.5 |
2016-04 |
4444.5 |
| 2008-10 |
2645 |
2012-07 |
4351.2 |
2016-05 |
4635.9 |
| 2008-11 |
2540.2 |
2012-08 |
4372.8 |
2016-06 |
4907.9 |
| 2008-12 |
2739.6 |
2012-09 |
3907.3 |
2016-07 |
5506.1 |
| 2009-02 |
2449.4 |
2012-10 |
3897.7 |
2016-08 |
5617.2 |
| 2009-03 |
2833.6 |
2012-11 |
4010.5 |
2016-09 |
4912.8 |
| 2009-04 |
2712.9 |
2012-12 |
4327.2 |
2016-10 |
4875.8 |
| 2009-05 |
2838.9 |
2013-03 |
4194.29 |
2016-11 |
5034.1 |
| 2009-06 |
3100.1 |
2013-04 |
4194.29 |
2016-12 |
5328.9 |
| 2009-07 |
3345 |
2013-05 |
4104.1 |
2017-03 |
5168.9 |
| 2009-08 |
3443.2 |
2013-06 |
4252.61 |
2017-04 |
4767.2 |
| 2009-09 |
3203.3 |
2013-07 |
4794.52 |
2017-05 |
4947 |
| 2009-10 |
3121 |
2013-08 |
4987.02 |
2017-06 |
5203 |
| 2009-11 |
3234.1 |
2013-09 |
4310.36 |
2017-07 |
6047.4 |
| 2009-12 |
3497.8 |
2013-10 |
4305.15 |
2017-08 |
5945.5 |
| 2010-02 |
2695.9 |
2013-11 |
4391.82 |
2017-09 |
5219.6 |
| 2010-03 |
3369.5 |
2013-12 |
4779.63 |
2017-10 |
5038.1 |
| 2010-04 |
3316.4 |
2014-02 |
3833.58 |
||
| 2010-05 |
3404.7 |
2014-03 |
4527.68 |
数据来源:国务院发展研究中心(DRC)行业景气监测平台
研究背景
数据是从国务院发展研究中心(DRC)行业景气监测平台选取。精度比较高,符合学术研究的实际运用。本文研究的主要是我国主要工业企业,工业发展对我国的经济发展有非常重大的作用,工业的发展离不开能源的供应,即用电,我国的其它能源暂时为发展起来,因此认为用电量的多少与工业生产的繁荣情况有相关关系高低对于预测和把我我国经济走势有重要的研究意义。在最近,世界灯光地图,来对世界人类和经济实力分布的判断成为了研究的热点,从其多少和用电量的区域特征可以对不同地区的经济实力有一个较为显著的判断,同时可以从用电量对实际情况进行验证,防止误差的产生,因此对于的判断具有重要的地位。
数据的分析
>install.packages(“RODBC”)
> library(RODBC)
> channel<-odbcConnectExcel("C:/Users/Repel/Desktop/sas.xls")
> r<-sqlFetch(channel,"Sheet1")
> rt<-ts(r,c(2005,11),c(2017,10),12)

平稳性检验
时序图检验
横轴表示时间,纵轴表示序列取值。中国主要企业的有明显的递增的趋势,所以该数据不是平稳序列。同时,数据在变动过程中具有明显的异常值,需要进一步分析异常值的原因。
> plot.ts(rt,xlab="time",ylab="index")
> acf(rt,lag.max=20,plot=TRUE)

图:2.1
一阶差分时序图检验
> difrt=diff(rt)
> plot.ts(difrt,xlab="time",ylab="index")
> acf(difrt,lag.max=20,plot=TRUE)
> pacf(difrt,lag.max=20,plot=TRUE)

图:2. 2
一阶差分的时序图显示主要企业的量始终围绕在0值附近随机波动,没有明显的趋势,可能具有小范围的周期。为了稳妥起见,使用自相关图进一步的辅助识别。同时,异常值对序列有了一定的影响,导致数据的波动范围变大,平稳序列需要波动范围有界。
单位根检验:

模型单位根P值显著性的小于0.05,模型是平稳的。因此我们认为其符合平稳性要求。
自相关图检验
序列的自相关性
数据在延迟一阶之后,落入2倍标准差范围以内,数据的平稳性非常显著,认为序列式平稳的。
自相关系数具有明显的拖尾性。

图: 2.2
偏自相关性图检验
可以看出在延迟三3阶之后,偏自相关系数都落入了2倍的标准差范围以内,而且偏自相关系数向灵衰减的速度非常快,延迟几阶之后偏自相关系数即在零值的附近波动,这是一个非常典型的短期相关的样本偏自相关图,认为序列是平稳的。
偏自相关图中从另一方面显示了偏自相关系数的拖尾性:在ρk始终有非零取值,不会再k大于某个参数之后就恒等于零。
从自相关性和偏自相关性初步的判断序列应该建立ARIMA模型。

图: 2.3
白噪声检验
对序列进行白噪声检验,以验证序列是否满足对于建模的要求,假设序列式为白噪声序列H0,从图得出,序列在延迟6阶的情况下,其P值小于0.001,拒绝原假设,认为序列不是白噪声的,当数据为平稳非白噪声时,初步认为数据符合建模要求。
> Box.test(difrt,lag=2)
图: 2.4
其P值显著性的小于0.05,因此我们认为数据是非白噪声,数据内容中有一定的信息量需要提取,建立ARIMA模型。
3模型的建立
3.1.2残差的Durbin-Watson检验
为了验证是否存在异方差,进行DW检验,从DW的值2.09。其值与2接近,输出该路显示残差序列不相关。不用考虑对残差序列拟合自相关模型,只需要考虑ARIMA模型。
DW检验统计量:
DW=t=2n(∈t-∈t-1)2t=1n∈2

根据此公式的出DW统计量的值。表中:大于DW的概率为0.63,小于DW的概率为0.36。
图: 3.1.2
预测参数其P值小于0.0001,概率非常小,不相关。

图
模型的BIC图:
我们从模型的BIC图中可以看出,模型应该定为ARIMA(1,1,1)。


模型的定阶
> arima=arima(rt,c(1,1,1))

图: 3.5
从前面的分析可以看出,应该建立ARIMA模型。ARIMA过程的第一步要使该序列的平稳性和纯随机性进行识别,并对平稳非白噪声序列估计拟合模型的阶数。
阶数的定阶为p=1、q=1。模型的定阶为ARIMA(1,1,1)。
拟合模型的参数显示
具体形式如图:
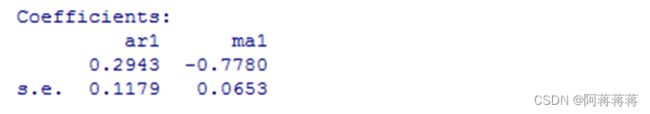
预测均值为2356.387,自回归系数多项式,和移动平滑系数多项式如下所示:
AR:
ΦB=1+0.2943B
MA:
ΘB=1-0.7780B
因此我们根据结果可以建立ARIMA。
ARIMA模型的结构:
ΦB1-Bdχt=Θ(B)ϵt
其中ΦB=1+0.2943B 、 ΘB=1-0.7780B 、 d=1
最终建立模型
1+0.2943B1-BX=(1-0.7780)ϵt
我们对差分平稳序列使用ARIMA模型的拟合情况较好。
模型的预测
模型的预测结果如图所示,预测了5个值。标准误较大,数据的预测效果具有一定的参考性。
> install.packages("forecast")
> library(forecast)
>forcast=forecast(arima,h=5,level=95)
>plot(forcast)

图: 4.0.1
数据的预测效果
我们从数据的预测情况可以看出:数据在后期的预测情况的置信区间没有较大范围的变动,因此标准误的变化的相对量不大,可以接受数据的预测情况,对比数据本身的标准差分析可以发现,预测的标准差可以接受,因此数据的预测情况具有一定的参考价值。
数据本身的标准差为731.8097,预测标准误为330附近,模型拟合程度较好。
结论
我国主要工业产品产量,具有逐年递增的趋势。同时有微弱的季节性,可以发现,从2005年以来,我国的产量有了显著性的增加,从2005年12月的2041.9变成了2017年10月的5038.1,量的方面有了一个倍数的变化,可以看出我国的经济发展走势非常强劲,对人们的生活有着一个较大的改变,于此同时国民经济的发展离不开用电量的增加,国民经济的发展走势也因此较为强劲。电力工业发展迅速,基本满足了社会生产及人民的生活需求。我国从2013年以来,总量居世界第一位,标志着我国工业进入一个新的发展阶段。
通过对数据进行时序图的分析,模型的建立与预测,发现未来的量情况有一定幅度的增加,不会有较大幅度的变化,因此判断,我国主要工业企业近期较为平稳,不会有显著性的增加, 进而对我国的经济情况做出一个判断,我国的经济情况近期不会有大幅度的波动,不会出现经济崩溃的情况。
参考文献
- 张 兵;陈文林。发电量与经济增长的相关性研究,黑龙江对外经贸期刊,2010 年第 12 期。
- 罗建国、何百磊 ,邢翼腾我国电力工业发展预测,中国能源期刊。2014年6月第6期。