cGAN/cDCGAN,MNIST数据集初体验(内含原理,代码)
生成式对抗网络(Generative Adversarial Networks, GAN),简称GAN网络。有人说这是21世纪最让人激动的“发明”,虽然我忘了我是从哪看到的这句话,貌似是发明了卷积神经网络那位大佬说的。我试过以后,对于AI兴趣爱好者来说
确实挺激动的!
对于标题中的cGAN/cDCGAN,小c,全称是conditional,条件的。DC,全称是Deep Convolution,深度卷积。都是GAN网络的一个变种。对于DCGAN与GAN的关系,也很简单,因为最开始GAN网络是用神经网络设计的,而后来出现了计算能力更强的卷积(CNN),训练逻辑相同,只是计算操作不同,当然可以相互替换。
对于原理,网传:一个生成器(Generator),一个判别器(Discriminator),他两相互博弈,相爱相杀,最后产生一个好的结果。。。
What?还要动手吗?
对于此种高端解释,我等菜鸡无法领会,我只想知道网络是怎么训练的?两个部分的输入输出分别是什么?网络如何搭建?Loss如何设计?有了这些,你的程序就可以跑了
还是从代码中理解啥是相爱相杀吧。
先放一张整体原理图,来个大致印象

那个G,就是生成器,那个D,就是判别器。其余就是常规表示网络的结构了,是如何设计的。各位应该发现图中还有个小y,这就是cGAN网络中的c
较常规GAN网络,多了个条件标签
这里想啰嗦一句,这个版本的cGAN在条件标签的处理上,用的是concatenate操作,也就是在某个维度上,直接叠加相关数据,一会在代码中也有显现。其余的还可不可以用别的操作来改善效果,本人很菜,还没有试过。
如图所示,因为用的是MNIST(手写数字体)数据集,每张图片的shape是[1, 28, 28],也就是单通道,分辨率是28x28。又因为是使用神经网络提取特征,所以需要将图片打平操作,所以生成器(G)最后生成的本来应该是一张图片的shape,这里的话就是784,这个数字各位应该不陌生,不多废话。
可以看到,G的输入就是100维的一个随机数,shape是[100, 100],这里生成100张假的数字体图像,对应的label,小y,也就是[100, 10],做了One-Hot编码。然而输出就是[100, 784],经过一些类似imshow等显示图片的函数的时候,在reshape成[100, 1, 28, 28], 就可以显示啦
再看D,判别器,这个就相对简单一些,就是平常看到的分类网络的结构。输入是由G生成的假的图像数据,输出只有两个,真or假,real or fake,用1和0代替结果,shape为[batch, 1],只有一堆0或1作为label。在代码中一看便知,就理解了。
ok,少废话,上代码(下面是完整的,来源也是GitHub的那位老哥的仓库,稍做了些修改,要不在我的环境下直接跑不了)
import os, time
import matplotlib.pyplot as plt
import itertools
import pickle
import imageio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# G(z)
class generator(nn.Module):
# initializers
def __init__(self):
super(generator, self).__init__()
self.fc1_1 = nn.Linear(100, 256)
self.fc1_1_bn = nn.BatchNorm1d(256)
self.fc1_2 = nn.Linear(10, 256)
self.fc1_2_bn = nn.BatchNorm1d(256)
self.fc2 = nn.Linear(512, 512)
self.fc2_bn = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, 1024)
self.fc3_bn = nn.BatchNorm1d(1024)
self.fc4 = nn.Linear(1024, 784)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = F.relu(self.fc1_1_bn(self.fc1_1(input)))
y = F.relu(self.fc1_2_bn(self.fc1_2(label)))
x = torch.cat([x, y], 1)
x = F.relu(self.fc2_bn(self.fc2(x)))
x = F.relu(self.fc3_bn(self.fc3(x)))
x = F.tanh(self.fc4(x))
return x
class discriminator(nn.Module):
# initializers
def __init__(self):
super(discriminator, self).__init__()
self.fc1_1 = nn.Linear(784, 1024)
self.fc1_2 = nn.Linear(10, 1024)
self.fc2 = nn.Linear(2048, 512)
self.fc2_bn = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, 256)
self.fc3_bn = nn.BatchNorm1d(256)
self.fc4 = nn.Linear(256, 1)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = F.leaky_relu(self.fc1_1(input), 0.2)
y = F.leaky_relu(self.fc1_2(label), 0.2)
x = torch.cat([x, y], 1)
x = F.leaky_relu(self.fc2_bn(self.fc2(x)), 0.2)
x = F.leaky_relu(self.fc3_bn(self.fc3(x)), 0.2)
x = F.sigmoid(self.fc4(x))
return x
def normal_init(m, mean, std):
if isinstance(m, nn.Linear):
m.weight.data.normal_(mean, std)
m.bias.data.zero_()
# 制作输入数据
temp_z_ = torch.rand(10, 100)
fixed_z_ = temp_z_
fixed_y_ = torch.zeros(10, 1)
for i in range(9):
fixed_z_ = torch.cat([fixed_z_, temp_z_], 0)
temp = torch.ones(10,1) + i
fixed_y_ = torch.cat([fixed_y_, temp], 0)
# print(fixed_z_)
# print(fixed_y_)
# print(fixed_z_.shape, fixed_y_.shape) # torch.Size([100, 100]) torch.Size([100, 1])
# One-Hot编码
fixed_z_ = Variable(fixed_z_.cuda(), volatile=True)
fixed_y_label_ = torch.zeros(100, 10)
fixed_y_label_.scatter_(1, fixed_y_.type(torch.LongTensor), 1)
# print(fixed_y_label_, fixed_y_label_.shape) # torch.Size([100, 10])
fixed_y_label_ = Variable(fixed_y_label_.cuda(), volatile=True)
# 定义显示图片的函数
def show_result(num_epoch, show = False, save = False, path = 'result.png'):
G.eval()
test_images = G(fixed_z_, fixed_y_label_)
G.train()
size_figure_grid = 10
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(5, 5))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
for k in range(10*10):
i = k // 10
j = k % 10
ax[i, j].cla()
ax[i, j].imshow(test_images[k].cpu().data.view(28, 28).numpy(), cmap='gray')
label = 'Epoch {0}'.format(num_epoch)
fig.text(0.5, 0.04, label, ha='center')
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
# 定义一个记录loss值的函数,便于绘制loss变化曲线
def show_train_hist(hist, show = False, save = False, path = 'Train_hist.png'):
x = range(len(hist['D_losses']))
y1 = hist['D_losses']
y2 = hist['G_losses']
plt.plot(x, y1, label='D_loss')
plt.plot(x, y2, label='G_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc=4)
plt.grid(True)
plt.tight_layout()
if save:
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
# training parameters
batch_size = 128
lr = 0.0002
train_epoch = 50
# data_loader
# transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True, transform=transform),
batch_size=batch_size, shuffle=True)
# network
G = generator()
D = discriminator()
G.weight_init(mean=0, std=0.02)
D.weight_init(mean=0, std=0.02)
G.cuda()
D.cuda()
# Binary Cross Entropy loss
BCE_loss = nn.BCELoss()
# Adam optimizer
G_optimizer = optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
D_optimizer = optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))
# results save folder
if not os.path.isdir('MNIST_cGAN_results'):
os.mkdir('MNIST_cGAN_results')
if not os.path.isdir('MNIST_cGAN_results/Fixed_results'):
os.mkdir('MNIST_cGAN_results/Fixed_results')
train_hist = {}
train_hist['D_losses'] = []
train_hist['G_losses'] = []
train_hist['per_epoch_ptimes'] = []
train_hist['total_ptime'] = []
print('training start!')
start_time = time.time()
for epoch in range(train_epoch):
D_losses = []
G_losses = []
# learning rate decay
if (epoch+1) == 30:
G_optimizer.param_groups[0]['lr'] /= 10
D_optimizer.param_groups[0]['lr'] /= 10
print("learning rate change!")
if (epoch+1) == 40:
G_optimizer.param_groups[0]['lr'] /= 10
D_optimizer.param_groups[0]['lr'] /= 10
print("learning rate change!")
epoch_start_time = time.time()
for x_, y_ in train_loader:
# train discriminator D
D.zero_grad()
mini_batch = x_.size()[0]
y_real_ = torch.ones(mini_batch)
y_fake_ = torch.zeros(mini_batch)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
x_ = x_.view(-1, 28 * 28)
x_, y_label_, y_real_, y_fake_ = Variable(x_.cuda()), Variable(y_label_.cuda()), Variable(y_real_.cuda()), Variable(y_fake_.cuda())
D_result = D(x_, y_label_).squeeze()
D_real_loss = BCE_loss(D_result, y_real_)
z_ = torch.rand((mini_batch, 100))
y_ = (torch.rand(mini_batch, 1) * 10).type(torch.LongTensor)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
z_, y_label_ = Variable(z_.cuda()), Variable(y_label_.cuda())
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
D_fake_loss = BCE_loss(D_result, y_fake_)
D_fake_score = D_result.data.mean()
D_train_loss = D_real_loss + D_fake_loss
D_train_loss.backward()
D_optimizer.step()
D_losses.append(D_train_loss.data)
# train generator G
G.zero_grad()
z_ = torch.rand((mini_batch, 100))
y_ = (torch.rand(mini_batch, 1) * 10).type(torch.LongTensor)
y_label_ = torch.zeros(mini_batch, 10)
y_label_.scatter_(1, y_.view(mini_batch, 1), 1)
z_, y_label_ = Variable(z_.cuda()), Variable(y_label_.cuda())
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
G_train_loss = BCE_loss(D_result, y_real_)
G_train_loss.backward()
G_optimizer.step()
G_losses.append(G_train_loss.data)
print('G_train_loss:', G_train_loss, 'D_train_loss:', D_train_loss)
epoch_end_time = time.time()
per_epoch_ptime = epoch_end_time - epoch_start_time
print('[%d/%d] - ptime: %.2f, loss_d: %.3f, loss_g: %.3f' % ((epoch + 1), train_epoch, per_epoch_ptime, torch.mean(torch.FloatTensor(D_losses)),
torch.mean(torch.FloatTensor(G_losses))))
fixed_p = 'MNIST_cGAN_results/Fixed_results/MNIST_cGAN_' + str(epoch + 1) + '.png'
show_result((epoch+1), show=True, save=True, path=fixed_p)
train_hist['D_losses'].append(torch.mean(torch.FloatTensor(D_losses)))
train_hist['G_losses'].append(torch.mean(torch.FloatTensor(G_losses)))
train_hist['per_epoch_ptimes'].append(per_epoch_ptime)
end_time = time.time()
total_ptime = end_time - start_time
train_hist['total_ptime'].append(total_ptime)
print("Avg one epoch ptime: %.2f, total %d epochs ptime: %.2f" % (torch.mean(torch.FloatTensor(train_hist['per_epoch_ptimes'])), train_epoch, total_ptime))
print("Training finish!... save training results")
torch.save(G.state_dict(), "MNIST_cGAN_results/generator_param.pkl")
torch.save(D.state_dict(), "MNIST_cGAN_results/discriminator_param.pkl")
with open('MNIST_cGAN_results/train_hist.pkl', 'wb') as f:
pickle.dump(train_hist, f)
show_train_hist(train_hist, save=True, path='MNIST_cGAN_results/MNIST_cGAN_train_hist.png')
# 制作gif动画
images = []
for e in range(train_epoch):
img_name = 'MNIST_cGAN_results/Fixed_results/MNIST_cGAN_' + str(e + 1) + '.png'
images.append(imageio.imread(img_name))
imageio.mimsave('MNIST_cGAN_results/generation_animation.gif', images, fps=5)
到这里,该BB的基本完事了,在代码中都可以看明白,胜过千言。
我觉得比较重要的一点,loss怎么设计的?各位看懂了吗?再啰嗦一段,其实无外乎就三个loss,一个是D的real概率的loss,一个是D的fake概率的loss,最后一个是G的real的loss,因为它要骗过判别器,生成较为逼真的图像,为后续的数据增强做准备。
代码中的体现:
1 D的real概率的loss
x_ = x_.view(-1, 28 * 28)
x_, y_label_, y_real_, y_fake_ = Variable(x_.cuda()), Variable(y_label_.cuda()), Variable(y_real_.cuda()), Variable(y_fake_.cuda())
D_result = D(x_, y_label_).squeeze()
D_real_loss = BCE_loss(D_result, y_real_)
这输入的可是真实的MNIST数据集的图像哦,当然是real了
2 D的fake概率的loss
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
D_fake_loss = BCE_loss(D_result, y_fake_)
这输入的是G生成的假的图像,是fake,要让判别器知道
3 G的real的loss
G_result = G(z_, y_label_)
D_result = D(G_result, y_label_).squeeze()
G_train_loss = BCE_loss(D_result, y_real_)
怎么骗判别器?那就是在做一个real的loss,用的还是G生成的图像数据
完事了!
上几张训练过程的图结果(动态图超了大小),还有一张loss图,各位感受一下吧


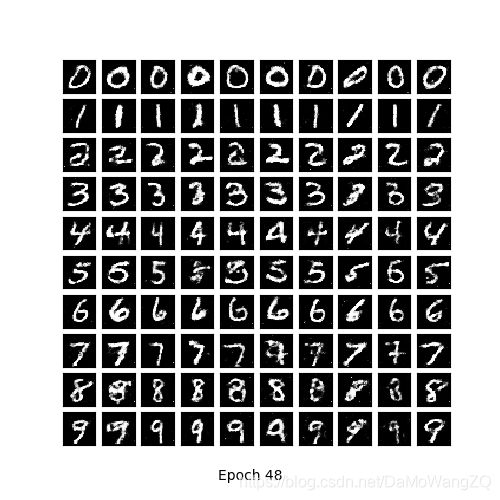

GAN网络很强!
首发于公众号<魔王周琦>