Pandas GroupBy计算剖析基础:分割、应用与组合
目录
引言
一、GroupBy对象与延迟计算
1.1 GroupBy返回什么
1.2 延迟计算(lazy evaluation)
1.3 可以对GroupBy对象做些什么
二、分组过程(组合操作)
2.1 一个简单的分割(split)-应用(apply)-组合(combine)示例
2.1.1 分割-应用-组合的通用过程
三、组合之前
3.1 累计
3.1.1 count()
3.1.2 std() 标准差
3.1.3 aggregate() 累计
3.2 过滤
3.2.1 filter()函数 ,但是是GroupBy对象的filter() 函数
3.2.2 也有普通过滤,就是DataFrame的filter
3.3 转换
引言
对较大数据进行分析时,有效的数据累计可以呈现大数据集的特征。由于数据集内部数据的多样性,我们不再形容为对单一类型数据的聚合,而是累计(aggregation),这意味着我们将实现在某个类别里的合并同类项。
对于一维数据的和、最值、均值等系列统计指标在这里不再赘述。对于二维的,有组织的DataFrame你也能通过指定汇总轴轻松得到你想要的结果。
笼统的了解整个数据集是不够的,对某些标签和索引局部的累计分析同样是我们需要的,Pandas里的groupby可以帮助我们做到这一点。但你在分组的时候,中间分割过程并没有显式地暴露出来,你似乎不需要关心底层如何计算,只要把操作看成一个整体就行了。
如果没有达到你想要的分组目的怎么办?或者你想知道你到底可以怎样去分组,让你呈现的数据更有条理,本文将主要讨论groupby的计算过程,以及你可以通过groupby可以实现的功能的简单介绍。
一、GroupBy对象与延迟计算
1.1 GroupBy返回什么
当你对一个DataFrame对象使用groupby方法时,你不会得到一个DataFrame。
你会得到一个DataFrameGroupBy的对象,内部隐藏着若干数据。你可以把它想象成一个元组列表(只是想象 !),在看完下面的阐述后,你也可以把它想象成许多分好组的DataFrame的集合。
在这个列表中有许多的元组。每个元组里有两部分,一部分是你按照你分类的标签分出来的东西,一部分是你的那个标签对应分好的一组DataFrame。
似乎有些难以理解。假设你手里有一张成绩单,如果我们以“等级”作为分组标签。等级下面有“ABCD”四个等级,学生有很多,有很多得A,很多得B,很多得C,很多得D。
那么你以等级为标签,可以分出四组,也就是四个元组,四个元组里的一部分分别是ABCD,另一部分是分别得到ABCD的学生们的四组数据——比如在A等级中,另一个DataFrame的部分就有可能是以 姓名及各科成绩为列标签的DataFrame(也会包含等级这个标签)
如果你感兴趣你可以试试下面这段代码
import pandas as pd
level=['A','C','B','A','B','D','B','A']
name=['小明','小红','小白','小张','小花','小子','小小','小想不出来了']
score=[85,60,78,90,75,32,73,88]
df=pd.DataFrame({'level':level,'name':name,'score':score})
print(df.groupby('level'))
print()
print(list(df.groupby('level')))1.2 延迟计算(lazy evaluation)
简言之,在你没有对这个DataFrameGroupBy对象应用计算时它是不会参加运算的,就像你只有对惰性序列使用next()它才会向下算一步,你只有对groupby()后的东西使用了累计函数,你才能得到相应的结果。
1.3 可以对GroupBy对象做些什么
你可以按列取值。就像对DataFrame那样。按列取值会返回一个被修改的GroupBy对象,然后你可以再对这个组进行累计操作。
df.groupby('level')['score']原来那个分组里,每一组里都含有等级,姓名,分数,但新的组中,只有等级和分数。
你可以按组迭代。GroupBy中有许多的DataFrame,你可以遍历他们。
你可以调用方法。直接让GroupBy对象调用DataFrame或者是Series的方法——理解为对每组使用一次方法,再组合起来。
二、分组过程(组合操作)
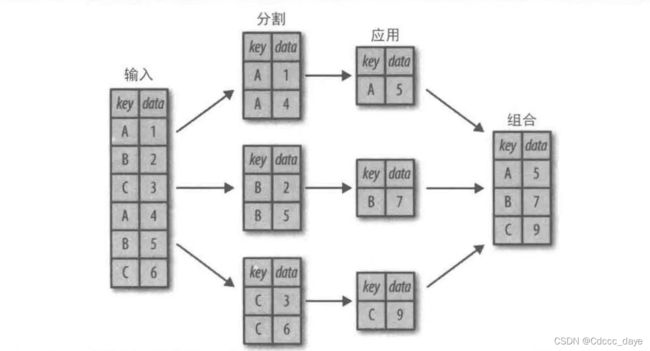
2.1 一个简单的分割(split)-应用(apply)-组合(combine)示例
*在这个例子中,“应用”采取的是求和
2.1.1 分割-应用-组合的通用过程
分割(Split):将DataFrame按指定的键分割成若干组
应用(Apply):对每个组分别应用函数
组合(Combine):将每个组的结果合并成一个输出
可视化结果呈现如下
三、组合之前
3.1 累计
首先,所有的累计操作都不会算入缺失值
| 指标 | 描述 |
|---|---|
| count() | 计数项 |
| first() last() | 第一项与最后一项 |
| mean() median() | 均值与中位数 |
| min() max() | 最小值 最大值 |
| std() var() | 标准差 方差 |
| mad() | 均值绝对偏差 |
| prod() |
所有项的乘积 |
| sum() |
所有项求和 |
在这里用两个例子来说明一些现象
3.1.1 count()
首先,count()不会计数缺失值,因为3.1一开头说过了。
计数就是在你进行分组之后,对每列进行计数
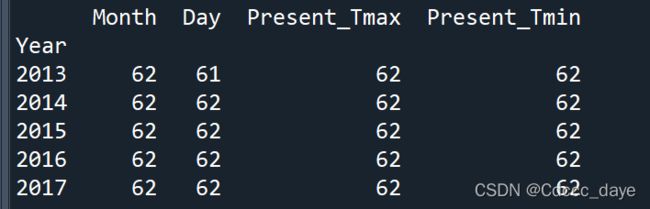
文字很抽象,假设你有一份数据,然后你以年份(Year)作为分组的标签,假设其他还有很多标签比如月份,日期,一些数据,然后你想看看每年各有多少条数据
直接DataFrame.groupby('Year').count()的话,会以计数的结果进行填充,你的月份、日期原有的数据都将被计数值所取代。
每列的计数值是会不一样的——因为计数是对每一列进行的,你不能保证这一列没有计数值。
3.1.2 std() 标准差
这个函数计算的是样本标准差,而非标准差。
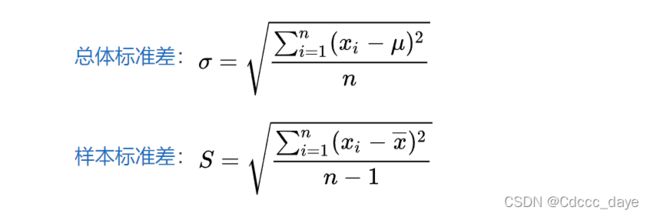
3.1.3 aggregate() 累计
这是一个功能强大的函数。你可以指定对不同的列一次性计算出你想要的(或所有)统计值
这主要和他的func参数有关。
这个参数可以是:
-
函数
-
函数名的str对象
-
一个装着函数的列表,一个装着函数名的数组,或者一个列表里既装了函数又装了函数名 e.g.
[np.sum, 'mean'] -
一个字典,键值对为轴与该轴采用的累计方法的映射
-
这个映射是:对应的轴(作为键) >>> functions, function names or list of such.(作为值)
import pandas as pd df=pd.DataFrame({ 'key':list('ABCABC'), 'data1':range(6) 'data2':range(10,16) }, columns=['key','data1','data2'] ) 在分组后,对每一组同时求出最小值,中位数,最大值 print(df.groupby('key').aggregate(['min','median',max])) 函数不用打括号,指的是上面那个maxdf.groupby('key').aggregate({'data1':min,'data2':max}) 对data1求最小,对data2求最大3.2 过滤
你可以按照分组的属性丢弃若干的数据
3.2.1 filter()函数 ,但是是GroupBy对象的filter() 函数
filter()函数接受一个返回值为布尔类型的函数的函数名作为参数
他不接受布尔数组不接受布尔Series不接受布尔DataFrame,他接受的是一个函数。
所以很大程度上你需要自定义一个返回值为布尔值的函数
import pandas as pd
def filter_func(x):
return x['data2'].std()>4
df=pd.DataFrame({ 'key':list('ABCABC'),
'data1':range(6),
'data2':[5,0,3,3,7,9] },
columns=['key','data1','data2'] )
print(df.groupby('key').filter(filter_func))此外,lamda表达式可以很好的帮助你来传入一个返回为布尔的函数。
3.2.2 也有普通过滤,就是DataFrame的filter
你可以理解成就是对特定的列或者行进行筛选。
可以指定轴(行列),可以有模糊匹配(like参数),不在本篇文章的讨论范围内。
3.3 转换
累计返回的是对分的组内全量数据缩减过的结果,而转换操作将会返回一个新的全量数据。
这是可以想象的:对一个组里的数据们找出最值,每个小标签下面只会有一个——因此他被缩减了
而转换,则是说对分组后的每一个数据进行某种操作,转换成全新的形式,比如让数据标准化,归一化。
3.3.1 transform函数
接受一个函数f,这个函数描述了对每一列数据的操作。且只能是对列操作
接受的这个参数,不能对所分的组有任何修改!
你这个函数 f 可以描述组里元素该怎么变,但 f 内部不能对组有修改的行为。