Python数据分析入门笔记3——数据预处理之缺失值
系列文章目录
Python数据分析入门笔记1——学习前的准备
Python数据分析入门笔记2——pandas数据读取
Python数据分析入门笔记
- 系列文章目录
- 前言
- 一、数据清理概述
-
- 1.缺失值的处理方式
- 2.重复值的处理方式
- 3.异常值的处理方式
- 二、缺失值的检测
-
- 1.缺失值
- 2.缺失值的检测
- 三、缺失值的处理
-
- 1.删除缺失值——dropna()
- 2.填充缺失值——fillna()
- 3.插补缺失值——interpolate()
- 四、缺失值实用处理流程
-
- 1. 文件中有缺失值,加载时如何处理?
- 2. 观察缺失数据占比,能否直接删除缺失值?(最好不要删除)
- 3. 能否直接采用填充缺失值的方式处理?
- 总结
- 上文答案
前言
学习目标:- 认识何为数据清理,为什么要进行数据清理,及常见数据问题的清理方式。
- 掌握缺失值的检测与处理方式。
一、数据清理概述
在数据分析的过程中,我们经常会发现有缺失的数据,比如上一篇博文中用到的excel文件,
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan,他们都一样
缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串,
数据清理是数据预处理的一个关键环节。通俗的说,就是检测到数据中的异常部分,如数据的缺失、重复和异常等,然后将这些“脏”数据清理成质量较高的“干净”数据。
常遇到的数据问题:
- 数据缺失
- 数据重复
- 数据异常
先简单介绍一下针对这三种情况的处理方式:
1.缺失值的处理方式
缺失值是指样本数据中,某个或某些属性的值不全。
产生原因:机械故障、人为因素。
影响:若使用存在缺失值的数据进行分析,会降低预测结果的准确率,需通过合适的方式予以处理。
常用处理方式:
- 删除缺失值——缺失数据占比较低的时候,可以尝试使用删除缺失值。
- 填充缺失值——适用于样本数量较大的情况。一般将平均数、中位数、众数、缺失值前后的数填充至空缺位置。
- 插补缺失值——线性插值:简单理解成两个点连线,在连线中间位置取一点加进去;最邻近插值:用于缺失值相邻的值作为插补的值。
2.重复值的处理方式
重复值是指样本数据中某个或某些数据记录完全相同。
产生原因:人工录入、机械故障导致部分数据重复录入,比如录入的时候卡了,或者不小心多录了一个。
常用处理方式:
- 保留重复值——在分析演变规律、样本不均衡处理、业务规则等场景中,重复值是有价值的,需要保留。
- 删除重复值——最普遍的处理方式。
3.异常值的处理方式
异常值是指样本数据中处于特定范围之外的个别值,这些值明显偏离它们所属样本的其余观测值。比如,学生成绩单里面,突然出现一个学生的语文成绩是1000分,明显不合常理,那么这个样本数据就属于异常值。
产生原因:人为疏忽、失误或仪器异常。
影响:异常值有可能是真的异常,也有可能是伪异常,需要根据实际情况处理。
常用处理方式:
- 保留异常值。
- 删除异常值。
- 替换异常值——最常用的方式,用指定的值,或根据算法计算出来的值,替换检测出的异常值。
二、缺失值的检测
1.缺失值
Pandas 中的缺失值来自于NumPy,NumPy中缺失值有几种表示形式:NaN,NAN,nan。
缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串。特别注意:NaN,NAN和nan也是互不相等的。
2.缺失值的检测
| 方法 | 简介 | 说明 |
|---|---|---|
| isnull() | 是空吗? | 若返回的值为True,说明存在缺失值 |
| notnull() | 没有空的吗? | 若返回的值为False,说明存在缺失值 |
| isna() | 是空吗? | 若返回的值为True,说明存在缺失值 |
| notna() | 没有空的吗? | 若返回的值为False,说明存在缺失值 |
import pandas as pd
import numpy as np #要使用NaN,NAN或nan都必须导入Numpy库
# 手动创建一个DataFrame或者用上篇方式读取文件
# 注意:手动创建的时候,空值必须用Numpy中的NaN、NAN或者nan占位
df=pd.DataFrame({'序号':['S1','S2','S3','S4'],
'姓名':['张三','李四','王五','赵六'],
'性别':['男','男','女','男'],
'年龄':[15,16,15,14],
'住址':[np.nan,np.nan,np.nan,np.nan]})
# 判断DataFrame中的缺失值,用isna()方法,True代表这个格子数值为空
df.isna()
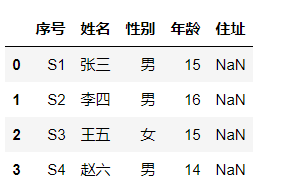
对如上DataFrame执行isna()操作后得到如下结果:
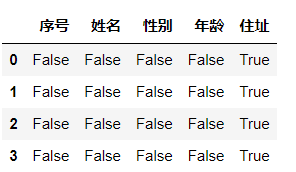
我们可以看到,通过isna()方法我们很方便地找到了原有数据中的空值,并且能根据True值的位置定位到NaN值所在的位置。
三、缺失值的处理
为避免包含缺失值的数据对分析预测结果产生一定的影响,缺失值被检测出来后一般不建议保留。
常见处理方法:
- 删除缺失值dropna()
- 填充缺失值fillna()
- 插补缺失值interpolate()
1.删除缺失值——dropna()
pandas中提供了删除缺失值的方法dropna()。
dropna()方法用于删除缺失值所在的一行或一列数据,并返回一个删除缺失值后的新对象。
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数说明:
| 参数 | 说明 | 取值及解释 |
|---|---|---|
| axis | 表示是否删除包含缺失值的行或列 | 0或’index’,代表按行删。 1或’columns’,代表按列删。 |
| how | 表示删除缺失值的方式 | any,当任何值为NaN值时便删除整行或整列。 all,当所有值都为NaN值时便删除整行或整列。 |
| thresh | 表示保留至少有N个非NaN值的行或列 | 数值,如thresh=3,那么只要这行或这列有3个及以上的非空值,就不删除。 |
| subset | 表示删除指定列的缺失值 | |
| inplace | 表示是否操作原数据 | True,会直接修改原数据文件。 False,会修改原数据的副本。 |
用法演示:
import pandas as pd
import numpy as np #要使用NaN,NAN或nan都必须导入Numpy库
# 手动创建一个DataFrame或者用上篇方式读取文件
# 注意:手动创建的时候,空值必须用Numpy中的NaN、NAN或者nan占位
df=pd.DataFrame({'序号':['S1','S2','S3','S4'],
'姓名':['张三','李四','王五','赵六'],
'性别':['男','男','女','np.nan'],
'年龄':[15,16,15,14],
'住址':['苏州','南京',np.nan,np.nan]})
# 判断DataFrame中的缺失值,用isna()方法,True代表这个格子数值为空
df.isna()
# 保留至少有3个非空值的行
df.dropna(thresh=3)
# 删除缺失值所在的列
df.dropna(axis='columns')
2.填充缺失值——fillna()
pandas中提供了填充缺失值的方法fillna()。一般会将平均数、中位数、众数、缺失值前后的数填充至空缺位置。
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
参数说明:
| 参数 | 说明 | 取值及解释 |
|---|---|---|
| value | 表示填充的数据 | 可以为变量、字典、Series或DataFrame对象 |
| method | 表示填充的方式,默认为None | None ’pad’或’ffill’,将最后一个有效值向后传播,也就是使用缺失值前面的有效值填充缺失值。 ‘backfill’或’bfill’,将最后一个有效值向前传播,也就是使用缺失值后面的有效值填充缺失值。 比如,连续的学号,中间有空缺,可以尝试用向前或者向后填充的方式。 |
| axis | 表示是否填充包含缺失值的行或列 | 0或’index’,填充包含缺失值的行 1或’columns’,填充包含缺失值的列 |
| limit | 表示连续填充的最大数量 | 取值应该为数值,例如limit=5 |
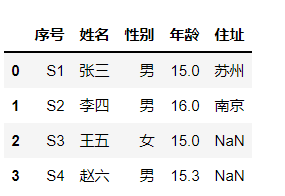
【例】年龄值有缺失,想用平均年龄来填充,用法演示:
import pandas as pd
import numpy as np
df=pd.DataFrame({'序号':['S1','S2','S3','S4'],
'姓名':['张三','李四','王五','赵六'],
'性别':['男','男','女','男'],
'年龄':[15,16,15,np.nan],
'住址':['苏州','南京',np.nan,np.nan]})
# 计算年龄列的平均数,并保留一位小数
col_age=np.around(np.mean(df['年龄']),1)
# 将计算的平均数填充到指定列
df.fillna({'年龄':col_age})
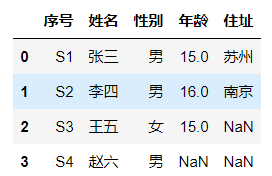
原数据:
年龄列填充后的结果:
3.插补缺失值——interpolate()
pandas中提供了插补缺失值的方法interpolate()。
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=None, **kwargs)
参数说明:
| 参数 | 说明 | 取值和解释 |
|---|---|---|
| method | 表示使用的插值方法。 | ‘linear’,默认值,代表采用线性插值法。 ‘time’,表示根据时间长短进行填充,适用于索引为日期时间的对象。 ‘index’或’values’,代表采用索引的实际数据进行填充。 ‘nearest’,表示采用最邻近插值法进行填充。 ‘barycentric’,代表采用重心坐标插值法进行填充。 |
| limit | 表示连续填充的最大数量 | |
| limit_direction | 表示按照指定方向对连续的NaN值进行填充。 | ‘forward’,向前填充。 ‘backforword’,向后填充。 ‘both’,同时向前、向后填充 |
插补缺失值这里,需要弄明白常用的几种插值方法的含义。
四、缺失值实用处理流程
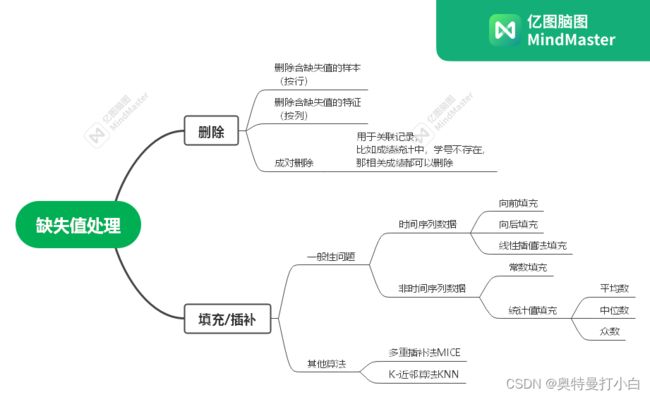
缺失值的来源有两个:
- 原始数据包含缺失值
- 数据整理过程中产生缺失值
1. 文件中有缺失值,加载时如何处理?
如果数据是从文件中加载的,会默认将’-1.#IND’, ‘1.#QNAN’, ‘1.#IND’, ‘-1.#QNAN’, ‘#N/A N/A’,’#N/A’, ‘N/A’, ‘NA’, ‘#NA’, ‘NULL’, ‘NaN’, ‘-NaN’, ‘nan’, ‘-nan’ 这些字符判定为缺失值,从而转换为NaN。
若不想自动转换,可以加一个参数keep_default_na = False。
若想将指定内容转换为NaN,如,上文景区名录文件中的“无”我们也想作为缺失值处理,那可以再加一个参数na_values=[“无”],代表我们读取的时候会将所有的’无’都处理成’NaN’。
示例代码如下:
import pandas as pd
# 加载数据,keep_default_na代表用自定义的方式来检测缺失值,na_values这里设置为“无”和空都视为缺失值
df=pd.read_excel('D://Projects/2019年底江苏省A级景区名录.xlsx',na_values=["无",""],keep_default_na = False)
df #输出得到的DataFrame
df.isna() #输出缺失值判断结果,对比
2. 观察缺失数据占比,能否直接删除缺失值?(最好不要删除)
- 当缺失数据占比较低的时候,可以尝试按行删除包含缺失值的整条记录。(但不建议)
- 当一列包含太多缺失值的时候(如超过80%),可以直接删除此列。(但不建议)
统计缺失数据占比,有两种方式,一种是用自定义函数,一种是用missnigno库来对缺失情况进行可视化处理。
(1) 用自定义函数生成表格,来显示各属性中缺失值的具体比例。
首先写一个missing_values_table,用于检测DataFrame中各列缺失值的比例,作为后续缺失值处理方法的选择依据:
def missing_values_table(df):
# 计算所有的缺失值
mis_val = df.isnull().sum()
# 计算缺失值比例
mis_val_percent = 100 * df.isnull().sum() / len(df)
# 将结果拼接成dataframe
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# 将列重命名
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : '缺失值', 1 : '占比(%)'})
# 按照缺失值降序排列,并把缺失值为0的数据排除
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'占比(%)', ascending=False).round(1)
# 打印信息
print ("传入的数据集中共 " + str(df.shape[1]) + " 列.\n"
"其中 " + str(mis_val_table_ren_columns.shape[0]) +
"列包含缺失值")
# 返回缺失值信息的dataframe
return mis_val_table_ren_columns
然后调用刚刚写的方法,生成一个表格,直观看到每列缺失比例
# 调用刚刚写的方法,来检测名为train的这个DataFrame中,每一列缺失比例
train_missing= missing_values_table(train)
train_missing
输出结果如下:

(2)使用missingno库进行缺失数据可视化。
推荐扩展阅读:九命猫幺-Python可视化查看数据集完整性: missingno库(用于数据分析前的数据检查)
使用missingno很简单,pip install missingno 安装,然后在代码中用import missingno as msno 导入模块。
import missingno as msno
# 使用条形图来展示缺失情况
msno.bar(df)
# 使用矩阵图来展示缺失情况
msno.matrix(df)
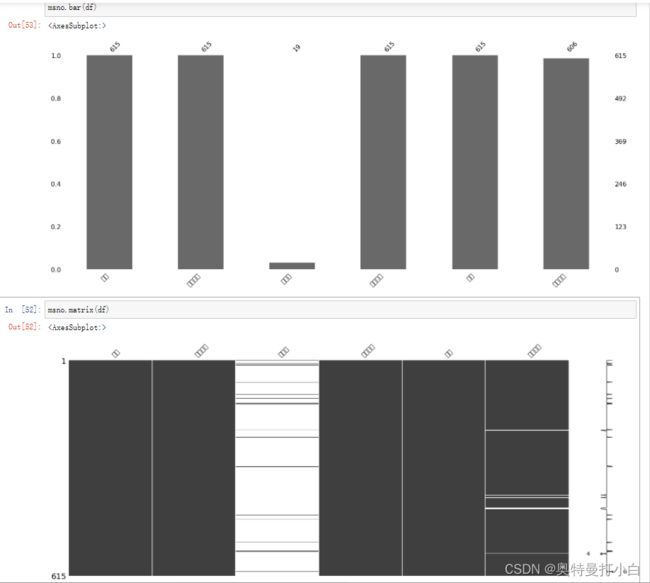
不懂就问:
- 如果不引用matplotlib库,能不能直接在missingno这里处理中文字符?现在的图表中中文显示不正常
3. 能否直接采用填充缺失值的方式处理?
对于非时间序列数据,可以用一个估算的值来替代缺失值,直接填充。
常用填充方式:
- 使用常量来替换(默认值)
- 使用统计量替换(缺失值所处列的平均值、中位数、众数)
对于时间序列类型数据缺失值,推荐使用线性插值法来插补缺失数据。
线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,并利用相邻数据点中的非缺失值来计算缺失数据点的值。
总结
这一篇主要是缺失值的检测与处理。
上文答案
参考代码:
import pandas as pd
df=pd.read_excel("D://Projects/2019年底江苏省A级景区名录.xlsx",sheet_name=0,index_col=0)
df.columns #输出表头
df['所在地市'].value_counts() #数每个地市有多少条数据,也就是每个地市各多少个景点入选
df.groupby('所在地市')['等级'].value_counts() #先按所在地市分组,然后根据等级分类计数
df.groupby('等级')['所在地市'].value_counts() #先按等级分组,然后根据所在地市分类计数