【论文阅读】Probabilistic Embeddings for Cross-Modal Retrieval CVPR 2021 --- 跨模态检索,概率嵌入,一对多,多对多匹配
本博客非论文的逐字逐句翻译,乃博主阅读论文之后根据自己的理解所写,预知详情,请参阅论文原文。
论文题目:Probabilistic Embeddings for Cross-Modal Retrieval;
作者:Sanghyuk Chun1, Seong Joon Oh1, Rafael Sampaio de Rezende2, Yannis Kalantidis2, Diane Larlus2,
论文发表地点:CVPR 2021;
论文下载地址:https://arxiv.org/pdf/2101.05068v1
代码链接:https://github.com/naver-ai/pcme
摘要:
跨模态检索的方法一般是对来自不同模态的样本建立一个公共表示空间(common representation space),通常是语言和视觉两种模态。
对于图像(images)和标题(captions)而言,对应关系的多样性(the multiplicity of the correspondences)使得该问题更加具有挑战性。
给定一张图像(或者一个标题),实际上存在多个有意义的、能够与之对应的标题(或者图像)。而作者认为现有的大多数模型中构建的确定性函数(deterministic functions)不足以捕获这样的一对多的对应关系(one-to-many correspondences)。
所以本文提出了PCME(概率跨模态嵌入,Probabilistic Cross-Modal Embedding),将来自不同模态的样本表示为公共表示空间中的概率分布(probabilistic distributions)。
然而现有的检索数据集也有这样的问题,比如COCO,不能详尽图像-标题配对的注释(就是说对于一张图像只有若干标题确定与之配对,其他标题与该图像配对与否不知道,这是不充足的)。所以本文在另一个较小但是更干净的数据集CUB上进行实验,该数据集中所有可能的图像-标题配对都有注释。
作者进一步对PCME做了消融实验,表明它不仅能够提升检索的性能,同时能够提供不确定的估计,使得学习到的embeddings更具有可解释性。代码已公开:https://github.com/naver-ai/pcme。
本文动机:
- 在image caption任务中,对应关系具有多样性(the multiplicity of correspondences)。如下图1所示,一张图像可能有多个文本描述都符合它的内容,一段文本可能也有多张图像与之匹配。也就是存在一对多、甚至多对多的情况。
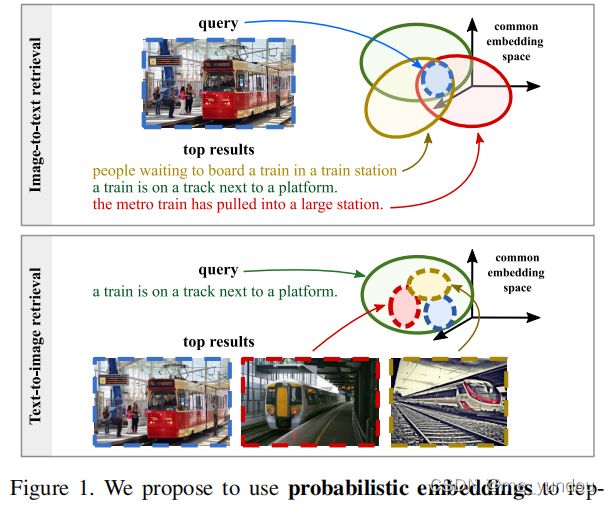
- 现有的多模态检索方法大多是学习确定的函数,只能处理一对一的对应关系,无法处理多对多的问题。
- 也有少量工作尝试解决该问题。如[25]通过预训练的目标识别模型提取图像的region embs,形成region-word匹配,该方法提高了检索性能但是计算量增大。
现存方法的问题:
- 通常的工作是对图像和标题学习一个全局的表示,但是这样的global embedding不能充分表示出图像/标题语义内容的多样性。后来的工作[16,54]尝试使用多个embeddings来表示一张图像/一个标题,以此来区分一对一和多对多这两种关系下的视觉语义特征。
- 最近最成功的方法是用region-level的编码器加上联合的视觉文本推理模块,来处理一对多问题,但是他们大多用了跨模态的attention,计算量大增,不易扩展。(本文直接建立joint emb空间的方法能够适应大规模数据)
本文主要贡献:
- 提出了PCME模型,能够在联合表示空间中映射一对多关系。它使用概率映射,不需要精确地构建多对多match(regions like,计算量太大)。该模型有如下优点:1.不确定的估计使得PCME能够评估检索的困难度,以及失败的概率(也就是辅助可解释性方面了);2.概率模型学到的是richer的emb space,其中集合关系也有作用,而精确space中只有相似性关系有用;3.概率映射是对精确检索系统的一个补充。
- 指出了现有跨模态检索数据集的不足之处,并提出了可替换的解决方案(就是现有数据集标注不完全的问题,不能详细给出数据集中所有pair的image和caption);
- 借助于PCME得到的不确定性估计对联合表示空间进行分析,展示了直观的性质(就是利用概率来分析检索的可解释性)。
针对本文贡献的个人理解:
其他将样本数据表示为一个emb的方法,样本数据映射在向量空间中就是一个个点,而本文实际是将每一个样本数据在向量空间中映射成了一个区域(样本数据的分布),通过计算两块区域(就是image和text样本)的匹配概率,来近似该image-text的匹配概率。对于多对多问题,多个不同区域的重合程度能一定程度上反应不同样本的匹配概率。而emb的表征只能用距离度量不同样本的匹配程度,不够有效。
本文模型和方法:
本文模型总体结构如下图2所示,因为本文做概率嵌入,所以对每一个图像和标题样本,该模型学习到的是一个正态分布(由均值 值和方差
值和方差 值能唯一确定一个正态分布),而不是一个确定的feature representation。
值能唯一确定一个正态分布),而不是一个确定的feature representation。
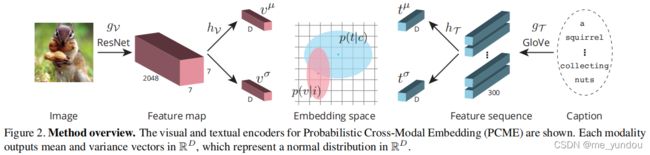
模型有两个关键部分,联合视觉文本嵌入(joint visual-textual embeddings)和概率嵌入(probabilistic embeddings)。
联合视觉文本嵌入:
如上图2和下图3所示,
视觉编码器:对于给定的一张图像,先用ResNet得到它的feature map,该过程定义为函数 g_V 。为了得到样本的正态分布,对一个feature map分别通过下图3中(b)和(c)过程得到它的均值和方差。
对图像,第一个D模块是一个全局均值池化层(GAP,global average pooling layer),再接一个线性层FC。
文本编码器:对于给定的标题c,先用GloVe得到c中所有单词的emb,也就是本文说的feature sequence,该过程定义为函数 g_T 。然后也通过下图3中(b)和(c)过程得到该标题样本所属的正态分布的均值和方差。
对于标题,第一个D模块是双向GRU。
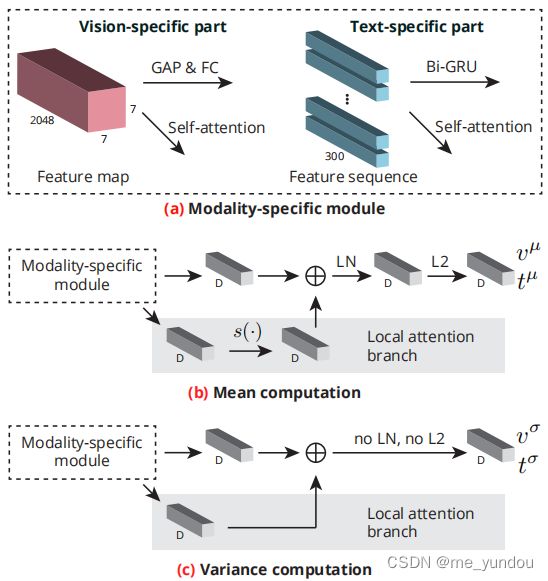

经过上述步骤,作者成功将数据集中每一个图像 i 和标题 c 样本转化为了一个正态分布。

概率嵌入:
为了学习上述正态分布,作者使用了soft跨模态的对比学习(soft corss-modal contrastive loss)来训练模型。HIB[37]中提出的原始的soft 对比学习loss如公式(1)所示,x_a 和 x_b 是一对样本,p_theta 是他俩匹配的概率,![]()
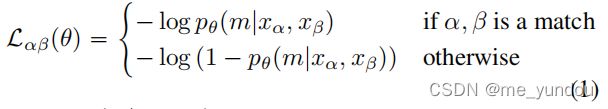
在本文中,上面的匹配概率 p_theta 是基于蒙特卡洛估计来近似的,如下面公式(2).
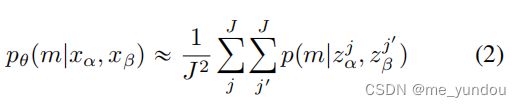
而这个公式(2)里面的每一个样本对的匹配概率 p 是使用样本的embeddings得到的,如下面公式(3)。

最后,在本文模型中,一对图像-标题样本对的匹配概率就用下面的公式计算了:
![]()
其中 v_j 和 t_j^' 来自上面公式(4)得到的正态分布。
额外的正则化技巧:
作者还使用了两个loss来正则化该模型。
- 一个是用KL散度,保证公式(4)所学到的正态分布尽可能靠近标准正态分布 N(0,1)。
- 另一个是uniformity loss [52],控制一个minibatch中的所有embeddings。
如何做测试:
由于本文为每个样本实际是生成了一个正态分布,所以在测试阶段有多种方法。
- 基于采样的方法:该方法就是用公式(2)的蒙特卡洛估计来近似一个image和一个text的匹配概率,如果采样J个样本的话,就需要O(J^2)的时间和空间复杂度。
- 不基于采样的方法:可以直接用样本所属正态分布的均值作为样本的emb(就像一些确定性的方法获取到的图像和文本数据的向量表示),计算不同样本之间的距离值来近似计算匹配概率。还可以用概率分布的距离度量方法,比如ELK,JS散度,2-Wasserstein等来度量本文学到的image和text样本分布之间的距离,作为匹配概率。这类不基于采样的方法因为只需要考虑测试的两个image和text样本,所以空间复杂度较小。
实验:
任务:跨模态检索(图像-标题);
数据集:COCO Captions,CUB;
评估指标:Recall@k(R@k)(作者认为该指标缺乏对检索错误的惩罚,所以又使用了后一个指标),R-Precision(R-P,该指标针对一个query有r个ground-truth检索结果的设定。对于一个query,模型检索出 r 个结果,R-P值计算检索结果中ground-truth结果的比例,该值越高说明模型检索出的groung-truth结果越多);
对比方法:VSE0,PVSE,VSRN;
结果:

上表1展示了使用不同的测试方法的PCME的检索结果差距,从中可以看出只使用均值(第一行)的方法结果比基于采样的方法低一些,但是空间复杂度较低。

上表2展示了PCME与VSE0和PVSE的对比结果,在3个指标中,PCME都取得了最好的结果。
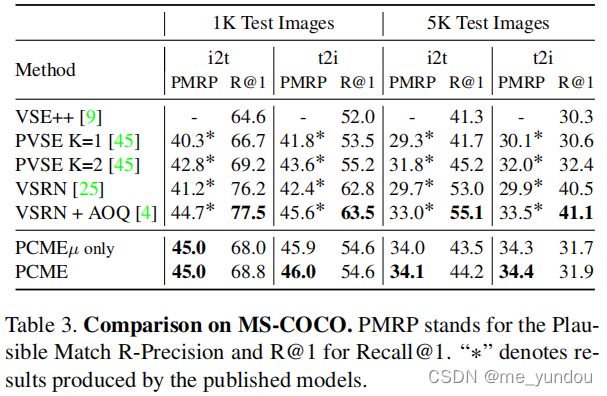
在COCO数据集上的结果如上表3所示。
本文4.4章分析了PCME作为一个概率嵌入模型的有点,不确定估计的好处,预知详情见论文原文,这里不再赘述。
参考文献:
[37] Seong Joon Oh, Kevin Murphy, Jiyan Pan, Joseph Roth, Florian Schroff, and Andrew Gallagher. Modeling uncertainty with hedged instance embedding. In Proc. ICLR, 2019.
[52] Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proc. ICML, 2020.
个人的理解和问题:
1. 目前的预训练语言模型,如Bert,XLNet,GPT等都很成熟且在多个下游任务中表现良好,为什么本文模型对文本的编码依然是用的GloVe和双向GRU呢?没有对比实验说明这个选择更好吗?
感谢评论区@北屿的解答,这个language编码的部分不是论文的主要贡献点,就像visual编码部分作者选择了预训练的ResNet网络一样,所以作者选择哪种语言/视觉编码模型都是可行的,主要看个人意愿了吧。而这里不需要不同语言编码模型的对比实验是因为,不同语言编码模型的对比是提出语言编码模型的文章该干的事情,以证明所提出模型的有效性。并不是本文的必要工作。
2. 看完了全文,我还是没明白,本文究竟是怎么处理多对多的?还需要对概率编码方向做深入理解。
时隔几个月,重读了一遍论文,对本文的理解多了一点。
在训练过程中,本文的image-text多对多关系体现在对比学习算法中,image和text的多个对应关系作为多个正样本参与训练。因此训练出的模型就能在概率空间中反应出样本数据之间的匹配关系(比如,图像-文本一对多关系,在样本的分布概率空间中可能就是,一个image样本的分布区域和多个text样本分布都有重合)。
在测试过程中,作者使用了R-P值来评估模型对多个ground-truth结果的检索能力。
3. 实验结果分析部分,表3中最后两行,本文方法PCME及本文方法的变种PCME-u only两个的结果对比,检索性能差距并不是很大。这是不是说明本文使用概率分布表示image和text样本数据的方式,相比于直接学习确定性的emb表征,差距不大呢?也许本文的效果提升是来自于多对多关系的利用和对比学习的方法?