VSE++: Improving Visual-Semantic Embeddings with Hard Negatives------BMVC 2018
可参考这篇博客:VSE++: Improving Visual-Semantic Embeddings with Hard Negatives_He_YI的博客-CSDN博客
原文翻译与理解,如有错误,欢迎指正。
摘要:我们提出了一种新的学习视觉语义嵌入的跨模态检索技术。受困难负样本挖掘、结构预测中困难负样本的使用以及排序损失函数的启发,我们对用于多模态嵌入的常见损失函数进行了简单的修改。这与微调和使用增强数据相结合,可以显著提高检索性能。我们在MS-COCO和Flickr30K数据集上展示了我们的方法VSE++,使用消融研究并与现有方法进行比较。在MS-COCO上,我们的方法在字幕检索和图像检索方面分别比最先进的方法高8.8%和11.3%(在R@1).
Introduction
联合嵌入可以在图像、视频和语言理解方面实现广泛的任务。示例包括用于形状推理的形状图像嵌入[20]、双语单词嵌入[38]、用于三维姿态推理的人体姿态图像嵌入[19]、细粒度识别[25]、零样本学习[9]和通过合成的模态转换[25,26]。这种嵌入需要从两个(或更多)域映射到一个公共向量空间,其中语义相关的输入(例如文本和图像)映射到相似的位置。因此,嵌入空间表示底层域结构,其中位置和方向通常具有语义意义。
视觉语义嵌入一直是图像字幕检索和生成以及视觉问答[22]的核心。例如,视觉问答的一种方法是,首先用一组标题描述一幅图像,然后根据问题找到最近的标题[1,37]。对于从文本合成图像,可以将文本映射到联合嵌入空间,然后再映射回图像空间。
在这里,我们主要关注用于跨模态检索的视觉语义嵌入;即检索给定标题的图像,或检索查询图像的标题。正如在检索中常见的那样,我们通过R@K,即在嵌入空间中与查询最近的K点中检索到正确项的查询的分数(K通常是一个小整数,通常为1 )。更一般地说,检索是评估图像和语言数据联合嵌入质量的一种自然方式[11]。
基本问题是排序;正确的目标应该比语料库中的其他项目更接近查询,这与学习排序问题(例如[18])和maxmargin结构化预测[3,17]没有什么不同。本文中的公式和模型架构与[15]中的公式和模型架构关系最为密切,后者是通过三元组排序损失学习的。与这项工作相反,我们提出一种新的损失,即使用增强数据和微调,与已知基准数据上的基线排名损失相比,这两者一起可以显著提高字幕检索性能。我们在MS-COCO上的表现比最佳报告结果高出近9%。我们还展示了一个更强大的图像编码器的优势,通过微调,通过使用我们更强的损失函数得到了放大。我们的模型为VSE++。为了确保再现性,我们的代码是公开的。
我们的主要贡献是在损失函数中加入硬负项。这是受到在分类任务中使用硬负样本挖掘[5,7,23],以及使用硬负样本改进人脸识别的图像嵌入[27,33]的启发。使用硬负挖掘最小化损失函数等价于使用均匀采样最小化修改的non-transparent 损失函数。我们扩展了这个想法,在多模态嵌入的损失中明确引入了硬负样本,而没有任何额外的挖掘成本。
我们还注意到,我们的提法是对最近其他文章的补充,这些文章提出了解决此问题的新体系结构或相似函数。为此,我们展示了[31]的改进。在其他可以通过修改损失进行改进的方法中,[32]提出了一种嵌入网络,以完全取代用于排名损失的相似性函数。[24]使用了图像和标题的注意机制,作者顺序地、选择性地关注单词和图像区域的子集,以计算相似度。在[12]中,作者使用了一种多模态上下文调整注意机制来计算图像和字幕之间的相似性。我们提出的损失函数和三元组采样可以推广并应用于其他类似问题。
2 Learning Visual-Semantic Embeddings
对于图像标题检索,查询是一个标题,任务是从数据库中检索最相关的图像。或者,查询可以是图像,任务是检索相关的标题。目标是最大限度地提高K的召回率(R@K),也就是说,在返回的前K个项中,最相关的项所占的查询比例。
设S={(in,cn)}Nn=1是图像标题对的训练集。我们把(in,cn)称为正对,把(in,cm≠n)称为负对;例如,与in中的图像最相关的标题是cn,而对于标题cn,则图像是in。我们定义了一个相似函数s(i,c)∈R。理想情况下,这应该给积极的一对比消极的一对提供更高的相似性分数。在字幕检索中,查询是一幅图像,我们根据相似性函数对字幕数据库进行排序;即 R@K是使用s(I,c)将正标题排在前K名标题中的查询的百分比。图像检索也是如此。接下来,在联合嵌入空间上定义了相似性函数。这与[32]等其他公式不同,后者使用相似性网络将图像标题对直接分类为匹配或不匹配。
2.1 Visual-Semantic Embedding
设φ(I;θφ)∈RDφ是根据图像i计算的基于特征的表示(例如VGG19或ResNet152中logits的表示)。同样,设ψ(c;θψ)∈ RDψ是字幕嵌入空间中字幕c的表示(例如,基于GRU的文本编码器)。这里,θφ和θψ表示到这些初始图像和字幕表示的相应映射的模型参数。
然后,设到联合嵌入空间的映射由线性投影定义:

![]()
我们进一步规一化了f和g,使其位于单位超球面上。最后,我们将联合嵌入空间中的相似性函数定义为通常的内积:
(两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为:a·b=a1b1+a2b2+……+anbn。)
![]()
设θ={Wf,Wg,θψ}为模型参数。如果我们也微调图像编码器,那么我们也会在θ中包含θφ。
训练需要最小化关于θ的经验损失,即训练数据的累积损失S={(in,cn)}Nn=1:

其中,l(in,cn)是单个训练样本的损失函数。受图像检索使用三元组损失的启发,最近的联合视觉语义嵌入方法使用了基于logits的三元组损失

式中,α用作margin参数,[x]+≡ 最大值(x,0)。hinge损失由两个对称项组成。第一个和用于给定查询i的所有负标题ˆc。第二个和用于给定标题c的所有负图像ˆi。每个项与负样本集的预期损失成比例。如果i和c在联合嵌入空间中彼此更接近,而不是任何负值,则根据α,铰链损失为零。在实践中,为了提高计算效率,通常只对小批量随机梯度下降中的负项求和(或随机采样),而不是对训练集中的所有负项求和[13,15,29]。计算这种损失近似值的运行时复杂度是小批量图像标题对数量的二次方。
当然还有其他损失函数可以考虑。一种是成对铰链损失,其中正对元素被鼓励位于联合嵌入空间中半径为ρ1的超球面内,而负对不应小于ρ2>ρ1。这是有问题的,因为它对潜在空间结构的约束比排名损失更大,并且需要使用两个非常难以设置的超参数。另一种可能的方法是使用典型相关分析来学习Wf和Wg,从而试图在联合嵌入中保持文本和图像之间的相关性(例如[6,16])。相比之下,在衡量性能时R@K,对于小K,基于相关的损失不会对正对局部附近的负项嵌入产生足够的影响,这对于R@K是重要的.
2.2 Emphasis on Hard Negatives
受结构化预测中使用的常见损失函数[7,30,35]的启发,我们将重点放在训练的硬负样本上,即最接近每个训练查询的负样本。这一点对于检索尤其重要,因为它是决定成功或失败的最难的负面因素R@1.
给定一个正对(i,c),困难负样本由i'=arg maxj≠is(j,c)和c'=arg maxd≠cs(i,d)给出。为了强调负样本影响,我们将损失定义为
![]()
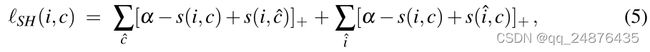
与等式5一样,这种损失包括两个项,一个是i,另一个是c。与公式5不同,这种损失是根据最困难的负样本c'和i'来确定的。我们将公式6中的损失称为最大铰链损失(MH),将公式5中的损失称为铰链损失之和(SH)。从SH损失到MH损失有一系列损失函数。在MH损失中,胜利者获得所有梯度,而我们使用所有三元组的重新加权梯度。我们只讨论MH损失,因为经验证明它表现最好。
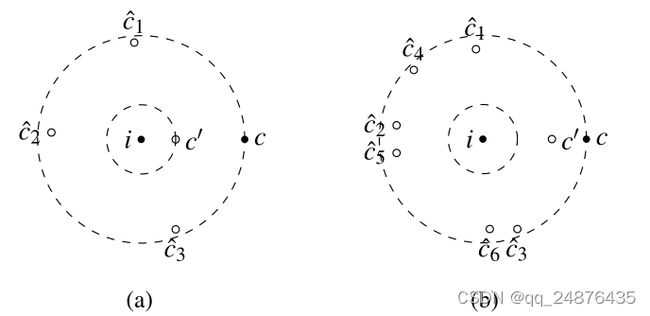
图1:典型正对和最近负样本的图示。这里假设相似性分数是负距离。填充圆显示正对(i,c),而空圆是查询i的负样本。两侧的虚线圆以相同的半径绘制。注意,最困难的负样本c'更接近(a)中的i。假设margin为零,(b)与(a)相比,SH损失的损失更高。MH损失将更高的损失分配给(a)。
MH损失优于SH的一种情况是,多个负对和小violations(妨碍)组合在一起主导SH损失。例如,图1描绘了一个正对和两个负对。在图1(a)中,单个负样本太接近查询,这可能需要对映射进行重大更改。然而,任何将硬负样本推开的训练步骤都可能会导致一些小的violations负样本,如图1(b)所示。使用SH损耗,这些“新”负样本可能会主导损失,因此将模型推回到图1(a)中的第一个示例。这可能会在SH损失中产生局部极小值,而对于MH损失来说,这可能没有那么大的问题,因为MH损失侧重于最严重的负样本影响。
为了提高计算效率,我们没有在整个训练集中找到最难的否样本,而是在每个小批量中找到它们。这与SH损失的复杂性具有相同的二次复杂性。对于小批量的随机抽样,这种近似方法还有其他优点。其中一个原因是,很有可能会出现比整个训练集中至少90%的人都更难接受的硬否样本。此外,由于在整个训练集中对最难的负样本进行抽样的概率较低,因此这种损失对于标记训练数据中的错误具有潜在的鲁棒性。
2.3 Probability of Sampling the Hardest Negative
设S={(in,cn)}Nn=1表示图像标题对的训练集,C={cn}表示标题集。假设我们在一小批中从S中抽取M个样本,Q={(im,cm)}Mm=1。让C上的排列πm表示根据cn的相似函数s(im,cn)对字幕的排名cn∈S\{cm}。我们可以假设排列πm是不相关的。给定一个查询图像im,我们感兴趣的是在小批量中,从πm的第90个百分位中不获得字幕的概率。假设样本IID,这个概率是.9(M-1) ,即小批量中没有来自第90百分位的样本的概率。 这一概率以指数的速度趋于零,对于M≥ 44 来说下降到1%以下.因此,对于足够大的小批量,我们很可能会对负面字幕进行抽样,这些字幕在整个训练集中的难度超过90%。πm的99.9%的概率更慢地趋于零;对于M来说,它低于1%≥ 6905,这是一个相对较大的小批量。
虽然我们通过在小批量中随机采样负样本来获得强信号,但这种采样还提供了一些对异常值的鲁棒性,例如负字幕,与地面真相字幕相比,负字幕更能描述图像。小到128个的小批量可以提供足够强的训练信号和鲁棒性来标记错误。当然,通过增加小批量,我们会得到更难的负样本,可能还有更强的训练信号。然而,通过增加小批量,我们失去了SGD在寻找好的最优解和利用梯度噪声方面的优势。这可能会导致陷入局部最优状态,或者如[27]所观察到的,训练时间非常长。
3 Experiments
下面,我们使用我们的方法VSE++进行实验,将其与具有SH损失的基线公式(表示为VSE0)和其他最先进的方法进行比较。基本上,基线公式VSE0类似于[15]中的公式,表示为UVS。
我们实验了两种图像编码器:VGG19和ResNet152。在下文中,除非另有说明,否则我们使用VGG19。与之前的工作一样,我们直接从倒数第二个完全连接的层FC7中提取图像特征。图像嵌入的维数Dφ对于VGG19是4096,对于ResNet152是2048。更详细地说,我们首先将图像的大小调整为256 × 256,然后使用224 × 224大小的单个裁剪或相似大小的多个裁剪的特征向量的平均值。
明天继续更新!!!