【论文阅读】CVPR2021 跨模态检索-Learning the Best Pooling Strategy for Visual Semantic Embedding(GPO)
由于CSDN的图床和我博客的图床不太匹配,所以懒得码字了。
转载一下我自己的博客
CVPR2021 跨模态检索-Learning the Best Pooling Strategy for Visual Semantic Embedding(GPO) | 陈子强的博客 (czq1999.github.io)
思想
Visual Semantic Embedding(VSE)是跨模态检索中的常见方法。旨在学习一个嵌入空间,具有相同语义的视觉和文本在空间中距离相近。然而现在的VSE方法使用复杂的方法将多模态的信息聚合为整体特征。例:注意力加权,图神经网络,seq2seq。本文发现了使用简单的池化策略进行特征聚合在跨模态检索任务上可以超越复杂模型的性能。池化策略聚合特征具有简单和有效性,但是如何在不同模态的数据上进行聚合特征,本文提出了generalized pooling operator(GPO)自动学习最佳池化策略。
补:跨模态检索中VSE的过程

- Input:输入图像和文本。
- Feature Extractor:提取视觉和文本的特征。对于图像来说,为了加速模型的训练,图像已经被提取为了向量当做数据集。一般分为两种:global和local。对于global,一个图像提取一个4096维向量。对于local一个图片使用RCNN提取36个region,每个region是2048维向量,即张量表示为(batch_size, 36, 2048)。本文暂时不考虑global的视觉当做输入。对于文本来说一般使用LSTM,GRU提取特征,最近两年的文章一般使用BERT提取文本表示即(batch_size, tokens,dim)。
- Aggregator:这一步的本质是将图像的多个region聚合为一个视觉表示。对于文本则是将一句话的多个token聚合为一个文本表示。常见的方法为:注意力,图神经网络。
- Embedding Space:在嵌入空间中度量相似性。大部分方法使用余弦相似度进行度量,同时结合三元损失(思想类似于CV中的facenet,相似的image-text pair在空间中的距离要近,不相似的距离要远)。这就不可避免的需要进行负样本采样,这里需要提一下VSE++提出了困难负样本,即训练的时候考虑拉大困难的负样本之间的距离。大大提高的模型准确率。数学上也比较好理解,如果最容易模型将最容易当成正样本的负样本给识别出来了,那么其他的样本也没问题,即 m a x > = s u m max >= sum max>=sum
模型
三种池化策略
- 最大池化:取最大值
- 均值池化:取均值
- K最大池化:取前k个最大值求平均
从一个例子来看池化策略:
栗子:假设一个班有三个人(一句话有多个token),每个人期末考试的三门分数给定(每个token的特征给定),那么现在怎么用一个三维的向量代表这个班级的成绩呢(如何聚合一句话中多个token的表示)?
一个简单的解法就是:取均值池化来代表这个班级成绩。但是在实际情况中,均值池化往往不一定适用于所有问题。

现在把向量的每一维度按照从大到小排序,然后乘以对应的系数进行加权。
- 若 θ 1 = 1 , θ 2 , . . , n = 0 θ_1=1, θ_2,..,n=0 θ1=1,θ2,..,n=0。等价于max pool
- 若 θ 1 , … , n = 1 N θ_{1,…,n}=\frac{1}{N} θ1,…,n=N1.等价于mean pool
- 若 θ 1 , . . k = 1 k , θ k + 1 , … , N = 0 θ_{1,..k}=\frac{1}{k},θ_{k+1,…,N}=0 θ1,..k=k1,θk+1,…,N=0,等价于K-max pool
可以看到 θ \theta θ取这三种情况时便对应上了最大池化、平均池化、和k最大池化。如果 θ \theta θ取可以任意取值,那么是不是可以说模型能捕获一些我们未知但是更优更适用于特定任务的池化策略呢?GPO便是这个思想。
GPO的池化策略:

三个问题阐述GPO
-
ϕ 1 , . . . , ϕ N \phi_1, ..., \phi_N ϕ1,...,ϕN表示多个local表示(文本中就是token,图像中就是region)。那么问题来了如何计算这个权重系数( θ 1 , . . . , θ k , . . . , θ N \theta_1,...,\theta_k,...,\theta_N θ1,...,θk,...,θN)呢?因为考虑到每次输入的token都是不同长度的,所以必须得考虑用一个能解决输入长度不固定的模型。作者考虑到了使用RNN中的GRU,得益于其结构相对于LSTM简单,故作者选择了GRU让模型的输入权重。
-
GRU的输出搞清楚了,那么输入是什么呢?作者使用的是Transformer中的位置编码作为GRU的输入。
-
还有个问题对于文本来说每个batch输入不同的句子,每个句子的长度是不一样的。那么图像怎么办呢?前面说道,现在用的数据集是一张图片提取36个region,那么对于图像来说每个batch输入不同的图片,每个图片都是36个region。现在看来和文本不一样了呀?作者采用了一个Data Augmentation的方法,就是对于一张图片的36个region,每个region随机赋予初值,只有初值大于0.2的region才被模型输入。换句话说,就是随机选大约80%的region当做输入。以此将图像的region变为不固定的数目。
我的疑惑
GPO中使用Transformer位置编码是什么样的?
GPO的本质是一个Bi-GRU 所以输入为三维的张量
-
对于一般用于处理文本的GRU来说输入为张量 [ b a t c h _ s i z e , m a x _ t o k e n s , d i m ] [batch\_size, max\_tokens, dim] [batch_size,max_tokens,dim]. 代表batch_size个句子作为输入,所有输入中句子的最大长度为max_tokens, 每个token使用dim维来表示
-
对于GPO中用于计算系数的GRU来说输入为张量 [ b a t c h _ s i z e , m a x _ t o k e n s , d i m ] [batch\_size, max\_tokens,dim] [batch_size,max_tokens,dim]. 代表batch_size个句子作为输入,所有输入句子的最大长度为max_tokens,每个token使用dim维来表示。只不过这里每个token的dim维向量使用Transformer中的位置编码进行初始化。
Transformer的位置编码公式如下:

pos代表一句话中的第pos个token, i表示当前这个token中的第i维向量是如何计算的,偶数维使用正弦函数计算,奇数维使用余弦函数计算。 d m o d e l d_{model} dmodel表示位置编码的维度。
例子:
在GPO中位置编码的维度为32,如图所示第一个token的位置编码的pos为0所以位置编码为[0,1,0,…,1]
Transformer位置编码来源 ?(为什么用sin和 1000 0 2 i / d m o d e l 10000^{2i/d_{model}} 100002i/dmodel)
为什么使用sin
总的原因有两点:
-
sin和cos可以建模相对位置信息:
-
有界函数
苏剑林大佬写了一篇很详细的博客说明,Transformer的Sinusoidal位置编码Transformer升级之路:1、Sinusoidal位置编码追根溯源 - 科学空间|Scientific Spaces
位置信息包括绝对位置信息和相对位置信息。Transformer即需要绝对位置信息也需要相对位置信息。
绝对位置信息是代表当前词是第几个token,因为注意力机制没有顺序信息的,即全对称的,例如:如果不加位置信息,(我吃饭, 饭吃我,我饭吃等)对于Transformer来说是一样的。
相对位置信息是指句子中一个token相对于另一个token的位置。引入相对位置信息便于计算上下文相关性。即离得近的token有高的相关性。即远程衰减。
对于transformer的输入为 f ( . . . , x m + p m , . . . , x n + p n , . . . ) f(...,x_m+p_m,...,x_n+p_n,...) f(...,xm+pm,...,xn+pn,...)。希望通过加入位置编码来打破对称性。即 f ~ ( . . . , x m , . . . , x n , . . . ) = f ( . . . , x m + p m , . . . , x n + p n , . . . ) \tilde f(...,x_m,...,x_n,...)=f(...,x_m+p_m,...,x_n+p_n,...) f~(...,xm,...,xn,...)=f(...,xm+pm,...,xn+pn,...). p m , p n p_m, p_n pm,pn为位置编码向量。
为了简化问题,首先只考虑在m和n上加入位置编码,根据泰勒展开, f ~ \tilde f f~ 可以写成:
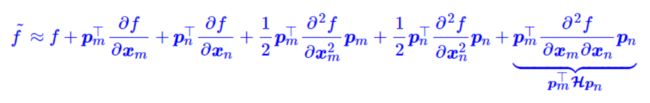
第一项为原始输入,第二项到第五项为单一位置的绝对信息,第六项同时包含 p m , p n p_m,p_n pm,pn,希望第六项包括绝对位置信息。
假设 p m T H p n p_m^THp_n pmTHpn中的 H H H为单位阵,所以 p m T H p n = p m T p n = < p m , p n > p^T_mHp_n=p^T_mp_n=
< p m , p n > = g ( m − n )
这里的 p m , p n p_m,p_n pm,pn都是d维向量,这里从d=2入手。对于二维向量,借助复数来推导, < p m , p n > = R e [ p m ′ p n ∗ ′ ]
p m ′ p n ∗ ′ = q m − n p_m^{'}p_n^{*'}=q_{m-n} pm′pn∗′=qm−n. 根据欧拉公式
a + b i = r e i θ = r c o s θ + r i s i n θ , a = r c o s θ , b i = r i s i n θ a+bi=re^{i\theta}=rcos\theta+risin\theta, \\a=rcos\theta,bi=risin\theta a+bi=reiθ=rcosθ+risinθ,a=rcosθ,bi=risinθp m ′ = r m e i θ m , p n ∗ ′ = r n e − i θ n , q m − n = R m − n e i Θ m − n p_m^{'}=r_me^{i\theta_m},p_n^{*'}=r_ne^{-i\theta_n},q_{m-n}=R_{m-n}e^{i\Theta_{m-n}} pm′=rmeiθm,pn∗′=rne−iθn,qm−n=Rm−neiΘm−n
可以得到
r m r n = R m − n θ m − θ n = Θ m − n r_mr_n=R_{m-n}\\\theta_m-\theta_n=\Theta_{m-n} rmrn=Rm−nθm−θn=Θm−n-
对于第一个式子,为了便于计算,设 r m = r n = 1 r_m=r_n=1 rm=rn=1。对应到位置编码中每个编码的模长为1
-
对于第二个式子,带入 n = 0 n=0 n=0,得 θ m − θ n = Θ m \theta_m-\theta_n=\Theta_m θm−θn=Θm,为了便于计算设 θ 0 = 0 \theta_0=0 θ0=0。对应到位置编码中第一个token的 θ = 0 \theta=0 θ=0
-
对于第二个式子带入 n = m − 1 n=m-1 n=m−1, 可以得到 θ m − θ m − 1 = Θ 1 = θ 1 \theta_m-\theta_{m-1}=\Theta_1=\theta_1 θm−θm−1=Θ1=θ1。 θ m \theta_m θm为等差数列,通解为 m θ m_\theta mθ
所以 p m ′ = ( cos m θ sin m θ ) \boldsymbol{p}_{m}^{'}=\left(\begin{array}{c} \cos m \theta \\ \sin m \theta \end{array}\right) pm′=(cosmθsinmθ)
由于内积满足线性叠加性,所以更高的偶数维位置编码可以表示为多个二维编码的组合

-
在 θ \theta θ的选取时为什么是 θ i = 1000 0 − 2 i / d \theta_i=10000^{-2i/d} θi=10000−2i/d?
原因:选取了这个 θ \theta θ,随着 ∣ m − n ∣ |m-n| ∣m−n∣的增大, < p m , p n >
这里 < p m , p n >
积分结果如下:
 的增加,token之间的 < p m , p n >
的增加,token之间的 < p m , p n >
那么为什么要是10000呢,1000,10000不行吗?事实上,几乎每个 [ 0 , 1 ] [0,1] [0,1]上的光滑函数 θ t \theta_t θt都能是积分具有渐进衰减的趋势

除了 θ = t \theta=t θ=t, 幂函数在短距离降得快一点,而指数函数则在长距离降得快一点。
GPO中位置编码对于计算系数是否有用?
实验组:对位置编码进行打乱(random.shuffle())
对照组:原论文中的位置编码
实验组结果如下:

对照组结果如下:

结论:位置编码对结果没有产生影响甚至在rsum上有0.6的提升。位置编码可以看为GRU的初始化输入,GPO的权重系数是通过GRU学出来的和初始化并无太大的关系。
我的思考
- 位置编码当做GRU的输入更加侧重于输入的初始化,至于权重的学习,则更加倾向于让模型学出来
- 作者在获取图像特征时同时采用region和grid也是一个不错的想法。最后使用ResXNet+BERT把性能跑到了最高,确实很强。