KDD2022 | 推荐系统通用序列表示模型UniSRec
© 作者|侯宇蓬
机构|中国人民大学
研究方向 | 推荐系统和图机器学习
本文提出一种面向推荐系统的通用序列表示学习方法。已有序列推荐模型通常显示地建模商品 ID,迁移性较差并存在冷启动问题。本文提出基于商品文本学习可迁移的通用商品表示,并在多领域行为序列上预训练来学习通用序列表示。预训练得到的模型可以高效地迁移至新领域和新平台。
前言:当前对序列推荐的研究集中于开发更高效的序列表示学习(SRL)模型。大部分已有方法都是显示地对商品 ID 进行序列建模,然而这些模型难以迁移至新的推荐场景,如新的领域或平台。为了解决建模商品 ID 带来的限制,本文提出了一个新的 SRL 方法 UniSRec。具体的,UniSRec 利用商品的文本信息学习可迁移至不同推荐场景的通用表示。为了学习通用商品表示,我们设计了基于参数白化和混合专家网络(MoE)增强的商品编码架构;为了学习通用序列表示,我们设计了两种基于对比学习的优化目标,在预训练阶段采样多个领域的序列/商品作为负例。预训练后的通用序列表示模型可以参数高效地迁移至新的领域或平台中。在真实数据集上构建的大量实验验证了 UniSRec 的效果。特别的,当把 Amazon 数据集上预训练的 UniSRec 模型迁移至一个新平台(某英国电商)时,也可以观察到效果提升,验证了本文提出的通用序列表示学习方法的强大迁移性。

作者: 侯宇蓬,中国人民大学硕士生二年级,导师为赵鑫教授,研究方向为推荐系统和图机器学习。
论文题目: Towards Universal Sequence Representation Learning for Recommender Systems
论文下载地址:
https://arxiv.org/pdf/2206.05941
论文开源代码:
https://github.com/RUCAIBox/UniSRec
一、背景与动机
序列化推荐模型通常可以归纳为一类序列表示学习(SRL)任务,即先将用户行为形式化为按时序排列的商品序列,然后开发高效的网络架构来捕捉序列交互特征并反映用户偏好,如 RNN、CNN、GNN、Transformer、MLP 等。
然而大多数针对推荐系统的 SRL 方法都依赖于显示的商品 ID 建模,存在迁移性差和冷启动的问题。即使各个推荐场景的数据格式是完全相同的,这些序列推荐模型依然难以迁移至新的领域或平台,严重限制了推荐模型的重用性。面对一个新的推荐场景,我们往往需要重新训练一个模型,这十分繁琐又耗费资源。此外,对于那些在数据中仅仅存在几次交互历史的冷启动商品,由于训练数据较少,现有的基于商品 ID 建模的模型也难以被很好地推荐给合适的用户。
二、思路与挑战
受到预训练语言模型的启发,我们致力于设计一个新的 SRL 方法,打破显示建模 ID 带来的限制,学习更具通用的序列表示。核心想法是利用与商品相关的文本(如商品描述、标题、品牌等)来学习可在不同域之间迁移的商品表示和序列表示。
但我们仍然面对一些主要挑战:
文本表示的语义空间无法直接适用于推荐任务中。直接引入原始文本表征作为额外商品特征往往会带来次优的结果,我们仍需探索如何利用及建模商品文本来提升推荐效果。
利用多个领域的数据来提升目标场景的推荐效果是很困难的事情。学习过程往往会发生跷跷板效应,即从不同的领域特定的模式中学习会导致冲突与震荡。
三、UniSRec 模型
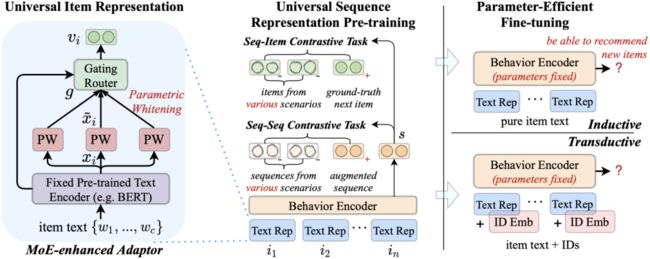
本节我们来介绍本论文提出的 UniSRec 模型。给定多个领域的历史交互序列,UniSRec 致力于学习通用的商品和序列表示。这些通用表示可以参数高效地迁移并泛化至新的推荐场景(新领域 or 新平台)。
1. 输入
用户行为序列可以被形式化为 (按时间顺序排列),其中每个商品
(按时间顺序排列),其中每个商品![]() 都对应着一个独特的商品 ID 和一段描述性的文本(如商品描述、标题或品牌)。商品
都对应着一个独特的商品 ID 和一段描述性的文本(如商品描述、标题或品牌)。商品![]() 的描述文本可以形式化为
的描述文本可以形式化为 ,其中
,其中![]() 来自于共享的词表,
来自于共享的词表,![]() 表示商品文本截断的长度。
表示商品文本截断的长度。
注意这里的每个序列包含了一个用户在某个特定领域的交互行为,而一个用户可以在多个不同领域和平台产生多个行为序列。由于不同领域间存在较大的语义差距,我们没有将一个用户的行为简单地混合为一个序列,而是将它们视为不同的序列,且并不显示地标注一个序列的用户是谁。注意到商品 ID 在本方法中只作为辅助信息,我们主要使用商品文本生成 ID 无关的可泛化的表示。除非特别指定,否则商品 ID 都不会作为 UniSRec 的输入。
2. 通用商品文本表示
通用序列行为建模的第一步即是将不同推荐场景的商品表示为通用语义空间中的向量。之前的方法通常是给商品 ID 分配一个可学习的嵌入表示。由于不同领域的商品 ID 的集合通常不同,这种方法限制了商品表示的可迁移性。
我们的做法是基于商品文本学习可迁移的商品表示,是通过自然语言描述了商品的特性。越来越多的证据显示,自然语言提供了一个通用的数据格式,可以连接不同的任务和领域。受此启发,我们首先使用预训练语言模型(PLM)学习文本表征。进一步,由于不同领域的文本表征可能会形成不同的语义空间(即使文本编码器相同),我们提出使用参数白化网络和混合专家网络(MoE)增强的适配器模块来将原始的文本表示转换至适用于推荐任务的通用的语义空间。
2.1 基于预训练语言模型的商品文本编码
这里我们使用常用的 BERT 模型,给定一个商品对应的商品文本,我们有

其中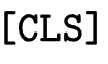 是一个特殊的符号,
是一个特殊的符号,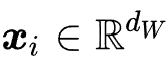 是 BERT 模型最后一层中
是 BERT 模型最后一层中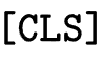 对应位置的隐向量。
对应位置的隐向量。
2.2 基于参数白化的语义转换
尽管我们已经获得了 BERT 编码的语义表征,它们无法直接适用于推荐任务中。已有的研究发现,BERT 生成的表示空间是非平滑且各向异性的。受到白化方法的启发,我们使用了一个简单的线性变换,希望将原始的 BERT 表示转换为各向同性的表示。与使用预设的均值/方差的原始白化方法不同,为了在未知领域上更好地泛化,我们在白化操作中引入了可学习参数

通过这种形式的语义转换,各向异性的问题可以被一定程度上缓解,有利于学习通用表示。
2.3 基于混合专家增强的适配器模块的领域融合与适配
由于不同域之间往往存在较大的语义差距,因此学习通用商品表示时要考虑如何迁移和融合不同域的信息。举例来说,Food 域的高频词有 natural, sweet, fresh 等,而 Movies 域则是 war, love, story 等。如果直接学习一个 BERT 原始表示到某共享语义空间的映射,则可能因为域之间存在 bias 而使模型表达能力不足,无法适配到新的推荐场景。因此我们提出对每个商品学习多个参数白化表示,并自适应融合成通用的商品表示。
具体地,我们使用了混合专家架构(mixture-of-expert, MoE)来实现这个想法。我们引入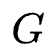 个参数白化网络作为 experts,并基于参数化的路有模块构建了 MoE 增强的适配器(Adaptor)
个参数白化网络作为 experts,并基于参数化的路有模块构建了 MoE 增强的适配器(Adaptor)

其中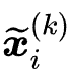 是第
是第![]() 个参数白化网络的输出,
个参数白化网络的输出, 是门控路由模块生成的对应的融合权重,具体计算方式如下
是门控路由模块生成的对应的融合权重,具体计算方式如下
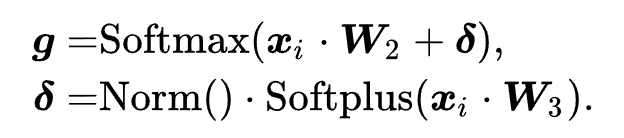
注意我们使用原始的 BERT 表示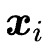 作为路由模块的输入,因为其携带着领域相关的语义偏置。这里的
作为路由模块的输入,因为其携带着领域相关的语义偏置。这里的 是可学习参数。为了 experts 间的负载均衡,我们使用
是可学习参数。为了 experts 间的负载均衡,我们使用 来生成随机高斯噪声。
来生成随机高斯噪声。
MoE 增强的适配器有如下三个优点:
单个商品的表示可以由学习多个参数白化网络而增强;
我们无需在域之间进行直接的语义映射,而是使用一个可学习的门控单元来自适应地建立语义联系,从而可以更好地进行领域融合与适配;
这个轻量化的适配器模块便于后续进行参数高效的微调。
3. 通用序列表示
在我们设计了这种通用商品表示方法后,在架构层面,我们已经可以使用同一个序列模型建模不同推荐场景的商品了。但是由于不同的域通常对应着不同的用户行为模式,简单地把这些不同领域的序列混合起来使用并不会取得很好的效果。这可能会导致跷跷板效应,即多个领域相关的模式可能会是互相冲突的。为此我们提出了两种基于对比学习的任务用于预训练,希望可以进一步促进不同域之间的融合与适配。
3.1 自注意力序列编码
这里我们使用和 SASRec 相似的方式进行行为序列编码,其中商品的表示不是 ID 嵌入表示了,而是我们上一节得到的通用商品编码。
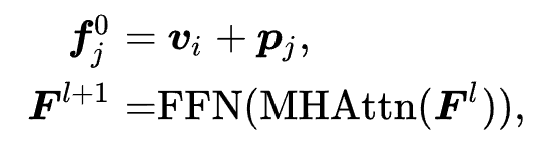
3.2 多领域序列表示预训练
拿到多个领域的商品序列,我们接下来研究如何设计合适的优化目标来使序列编码器的输出落入通用表示空间中。
序列-商品对比任务。简单来讲就是给定序列,预测下一时刻的商品。对于一个给定的序列,它的下一时刻商品为正例。与传统的 next item prediction 任务不同,在本任务中我们使用 in-batch 的多个域的商品作为负例,希望可以增强不同域的通用表示的融合与适配。

序列-序列对比任务。第二个任务我们考虑设计一个序列级别的自监督任务来增强预训练。我们使用两种启发式的数据增强策略,来为一个序列生成负例。具体来说,对于一个商品序列,我们随机丢弃掉原始序列中的商品或者商品文本中的单词来构造正例,而负例则是 in-batch 的多个域的其他序列。

多任务学习。在预训练阶段,我们使用多任务策略来联合优化提出的两种对比损失。
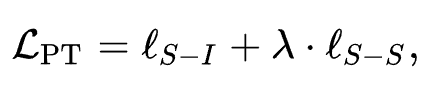
通过上述方法优化的预训练模型可以被微调以适配到新的推荐场景中。
4. 参数高效的微调
鉴于预训练后的 UniSRec 可以生成通用商品序列表示,当我们需要适配一个新的推荐场景时,我们选择只微调模型的一部分参数。具体而言,我们会固定整个行为编码器(本文 3.1 节中的 Transformer Encoder)的参数,只微调 MoE 增强的适配器(本文 2.3 节)的参数。我们发现提出的 MoE 增强的适配器可以快速适配到未见过的领域,将预训练模型与新领域的特征进行融合。根据新的推荐场景中商品 ID 是否可用,我们考虑两种微调设置,命名为归纳(Inductive)与转导(Transductive)。
归纳(Inductive)。对于新商品频繁涌现的推荐场景,传统的基于商品 ID 的模型可能并不适用。由于 UniSRec 天然不依赖于商品 ID,因此其可以为新商品学习通用文本表示。这时我们可以按如下概率预测商品

这里我们在整个候选商品集合上计算下一商品的概率。
转导(Transductive)。对于近乎所有商品都在训练集出现的场景,我们也可以同时学习商品 ID 表示。我们可以简单将通用文本表示和 ID 表示加和并进行预测

其中![]() 代表 ID 表示增强后的通用序列表示。
代表 ID 表示增强后的通用序列表示。
对于这两种设置,我们都使用常用的交叉熵损失进行优化,并更新 MoE 增强的适配器的参数。
四、实验
为了验证 UniSRec 的迁移性,本文采用了跨域和跨平台两种实验设置。具体来说,我们将 Amazon 2018 数据集的 5 个 domain(Food, Home, CDs, Kindle, Movies)用于预训练,并将这一个预训练的 UniSRec 模型在各个下游数据集上微调。
下游数据集分为两类:
跨域:我们将 Amazon 2018 数据集中另 5 个规模较小的 domain(Pantry, Scientific, Instruments, Arts, Office)视作新 domain 并测试 UniSRec 的效果。
跨平台:我们使用某英国电商数据集 Online Retail 作为新平台进行测试。
注意预训练数据与下游的六个数据集均可以看作没有用户 / 商品重叠。
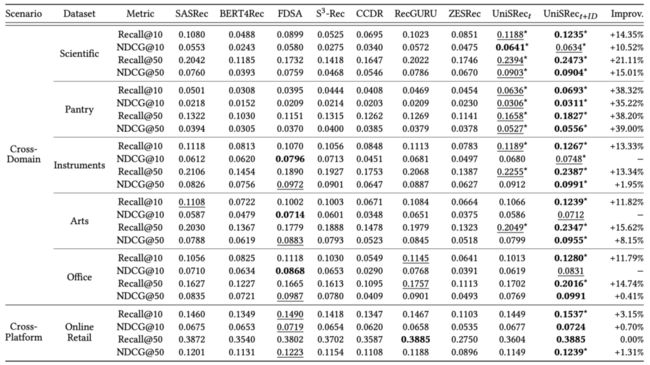
可以发现在各个下游数据集上,UniSRec 都取得了不错的效果。尤其对于 Online Retail 数据集来说,使用没有用户/商品重叠的另一个平台的交互数据来帮助本平台的推荐效果在之前是很难做到的。
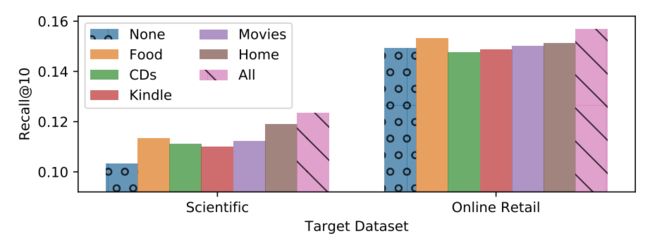
本文还构建了实验分析了预训练数据集的选择,发现使用多个领域的数据预训练会比单一数据预训练取得更好的效果。
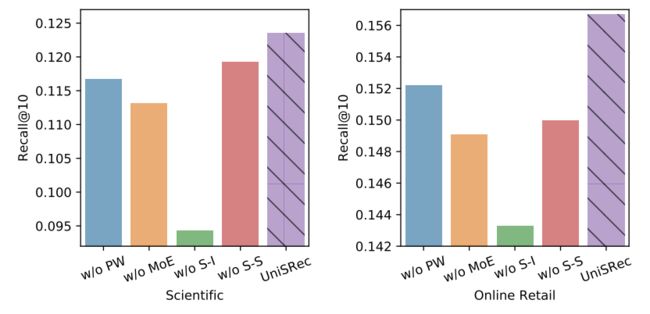
消融实验也验证了提出的各个模块的有效性,并证明多领域上的预训练确实会带来提升。

针对冷启动商品的实验,我们可以看到 UniSRec 在那些交互次数较少的组别上,可以获得较大的效果提升。其他更详细的实验分析请参考我们的原论文。
五、总结
传统序列推荐模型因为商品 ID 在域/平台间不共享而存在着迁移性差和商品冷启动的问题。本文提出一种新的序列表示学习方法 UniSRec,希望打破显示建模商品 ID 带来的限制,编码商品文本并生成迁移性强的通用商品表示,并进一步在多个域上预训练来学习到通用序列表示。预训练后的 UniSRec 模型可以参数高效地在新的域/平台上微调。在跨域/跨平台数据集上进行的大量实验验证了 UniSRec 的效果,尤其是通过本文提出的预训练方法,Amazon 数据集上的行为序列可以提升英国电商平台数据集上的推荐效果,验证了 UniSRec 的强大迁移性。