Yolov5添加注意力机制
一、在backbone后面引入注意力机制
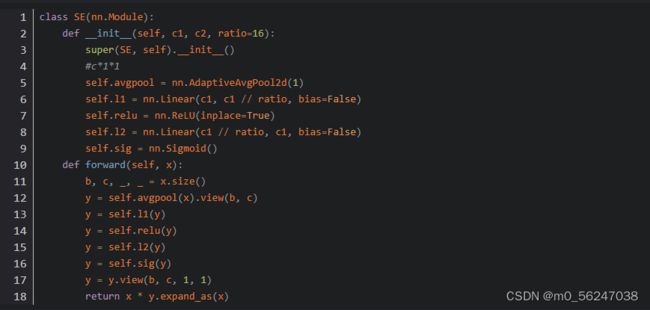
1、先把注意力结构代码放到common.py文件中,以SE举例,将这段代码粘贴到common.py文件中
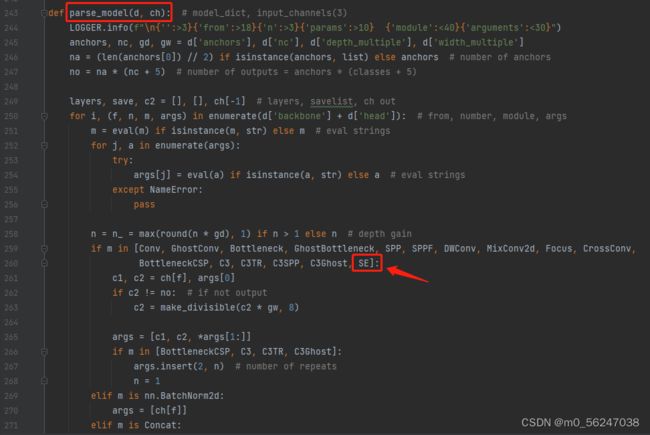
2、找到yolo.py文件里的parse_model函数,将类名加入进去
3、修改配置文件(我这里拿yolov5s.yaml举例子),将注意力层加到你想加入的位置;常用的一般是添加到backbone的最后一层,或者C3里面,这里是加在了最后一层
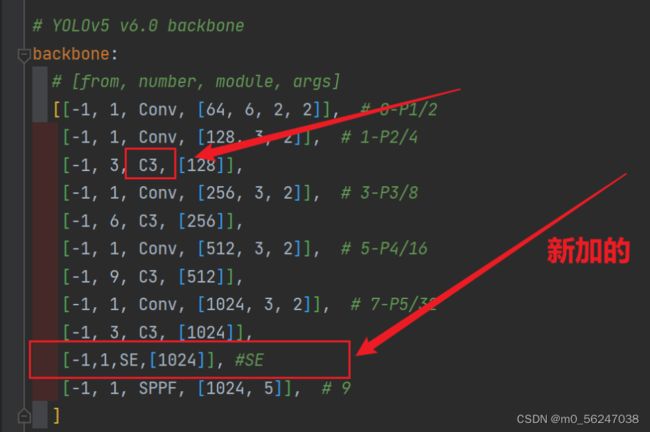
当在网络中添加了新的层之后,那么该层网络后续的层的编号都会发生改变,看下图,原本Detect指定的是[ 17 , 20 , 23 ]层,所以在我们添加了SE注意力层之后也要Detect对这里进行修改,即原来的17层变成了18 层;原来的20层变成了21 层;原来的23层变成了24 层;所以Detecet的from系数要改为[ 18 , 21 , 24 ]
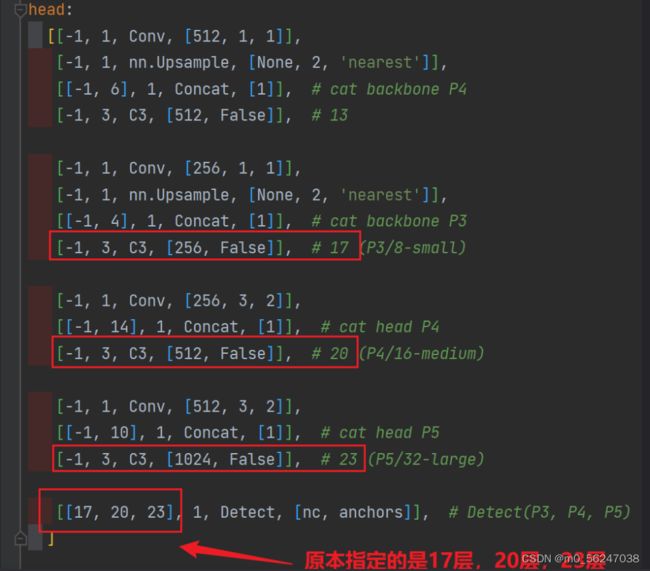
同样的,Concat的from系数也要修改,这样才能保持原网络结构不发生特别大的改变,我们刚才把SE层加到了第9层,所以第9层之后的编号都会加1,这里我们要把后面两个Concat的from系数分别由[ − 1 , 14 ] , [ − 1 , 10 ]改为[ − 1 , 15 ] , [ − 1 , 11 ]

二、在残差模块Bottleneck中引入注意力机制(SimAM/CA)
SimAM
1、将SimAM代码加入到common.py文件中,
#SimAM
class simam_module(torch.nn.Module):
def __init__(self, channels=None, e_lambda=1e-4):
super(simam_module, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)2、在common.py的残差结构中引入SimAM,即重新定义一个含有SimAM的类Bottleneck_SimAM

#将SimAM注意力机制加在bottleneck里面
class Bottleneck_SimAM(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck_SimAM, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
self.attention = simam_module(channels=c2)
def forward(self, x):
return x + self.attention(self.cv2(self.cv1(x))) if self.add else self.cv2(self.cv1(x))
3、然后找到yolo.py文件里的parse_model函数,将类Bottleneck_SimAM加入进去并将原类名Bottleneck删除,这样就把注意力SimAM引入的残差结构中了

CA
1、将CoordAtt代码加入到common.py文件中,
# CoordAtt注意力机制
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
# c*1*W
x_h = self.pool_h(x)
# c*H*1
# C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
# C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out2、在common.py的残差结构中引入CA,即重新定义一个含有SimAM的类Bottleneck_CA,
# 将CA注意力机制加在bottleneck里面
class Bottleneck_CA(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck_CA, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
self.attention = CoordAtt(inp=c2)
def forward(self, x):
return x + self.attention(self.cv2(self.cv1(x))) if self.add else self.cv2(self.cv1(x))
3、然后找到yolo.py文件里的parse_model函数,将类Bottleneck_CA加入进去并将原类名Bottleneck删除,这样就把注意力CA引入的残差结构中了
三、在YOLOV5的Backbone、Neck、Head模块中分别引入注意力机制
1、Backbone


2、Neck

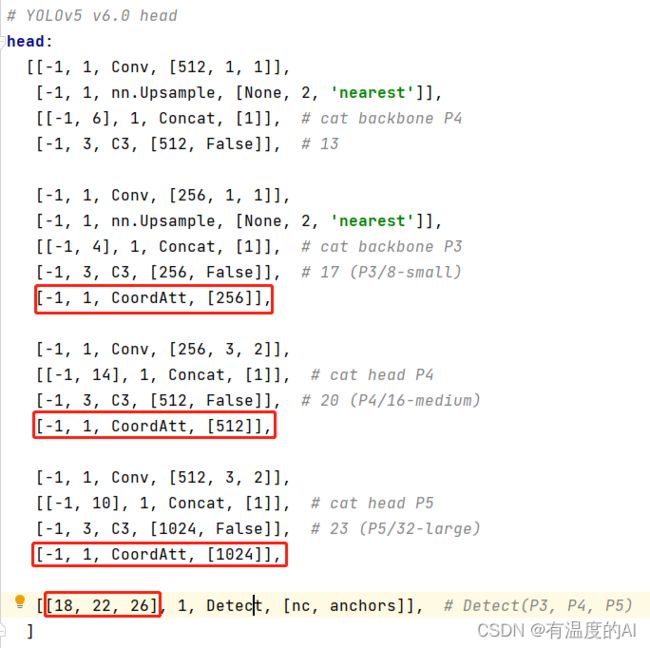
3、Head

reference
手把手带你Yolov5 (v6.1)添加注意力机制(一)(并附上30多种顶会Attention原理图)_迪菲赫尔曼的博客-CSDN博客_yolov5添加注意力机制 https://blog.csdn.net/weixin_43694096/article/details/124443059
https://blog.csdn.net/weixin_43694096/article/details/124443059
注意力机制(SE、Coordinate Attention、CBAM、ECA,SimAM)、即插即用的模块整理_吴大炮的博客-CSDN博客_se注意力机制https://blog.csdn.net/weixin_44645198/article/details/122102201#comments_21981724