FCN源码解读之solve.py
转载自 https://blog.csdn.net/qq_21368481/article/details/80636932
solve.py是FCN中解决方案文件,即通过执行solve.py文件可以实现FCN模型的训练和测试过程。以下拿voc-fcn32s文件夹里的solve.py举例分析。
一、源码及分析如下:
-
#coding=utf-8
-
import caffe
-
import surgery, score
-
-
import numpy
as np
-
import os
-
import sys
-
-
try:
-
import setproctitle
-
setproctitle.setproctitle(os.path.basename(os.getcwd()))
-
except:
-
pass
-
#加载网络模型的参数信息
-
weights =
'../ilsvrc-nets/vgg16-fcn.caffemodel'
-
-
# init 初始化(选择要执行此代码训练的GPU)
-
caffe.set_device(int(sys.argv[
1]))
-
caffe.set_mode_gpu()
-
#使用caffe中的随机梯度下降法解决方案(SGDSolver,也即FCN模型训练时每次迭代只训练一张图片)
-
solver = caffe.SGDSolver(
'solver.prototxt')
-
solver.net.copy_from(weights)
#直接从上述加载的模型中拷贝参数初始化网络
-
-
# surgeries 由于Vgg16模型是没有上采样层的,所以遇到上采样层(即含有'up'字眼的层),需要利用surgery.py中的interp()函数进行
-
#这些层的初始化,所采用的初始化方法是双线性插值,详见我的另一篇博客https://blog.csdn.net/qq_21368481/article/details/80289350
-
interp_layers = [k
for k
in solver.net.params.keys()
if
'up'
in k]
-
surgery.interp(solver.net, interp_layers)
-
-
# scoring val中保存测试集的索引号
-
val = np.loadtxt(
'../data/segvalid11.txt', dtype=str)
-
#总训练次数为25*4000=100000次(注:这里不修改的话,直接在solve.prototxt中修改max_iter是没有用的)
-
for _
in range(
25):
-
solver.step(
4000)
#每训练4000次,进行一次测试,并保存一下模型参数(对应solve.prototxt中的snapshot: 4000)
-
score.seg_tests(solver,
False, val, layer=
'score')
但是直接执行上述代码是无法运行的,会报很多错误,需要进行修改才能运行,具体修改后的代码如下(读者可以和上述源码对比一下,做出相应的修改):
-
#coding=utf-8
-
import sys
-
sys.path.append(
'D:/caffe/caffe-master/python')
#加载caffe中的python文件所在路径(以免报错),注意要加载自己的
-
import caffe
-
import surgery, score
-
-
-
import numpy
as np
-
import os
-
-
-
try:
-
import setproctitle
-
setproctitle.setproctitle(os.path.basename(os.getcwd()))
-
except:
-
pass
-
'''
-
加载Vgg16模型参数(原因在于FCN中FCN32s是在Vgg16模型上fine-tune来的,而
-
FCN16s是在FCN32s的基础上训练的,所以在FCN16s的solve.py文件中要加载FCN32s
-
训练完后的模型(例如caffemodel-url中给的fcn32s-heavy-pascal.caffemodel,
-
caffemodel-url文件在每个FCN模型文件夹都有,例如voc-fcn32s文件夹,直接
-
复制里面的网址下载即可),FCN8s的加载FCN16s训练好的模型参数。
-
Vgg16模型参数和其deploy.prototxt文件可从我提供的百度云链接上下载:
-
'''
-
vgg_weights =
'vgg16-fcn.caffemodel'
-
vgg_proto =
'vgg16_deploy.prototxt'
#加载Vgg16模型的deploy.prototxt文件
-
#weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
-
-
-
# init 初始化
-
#caffe.set_device(int(sys.argv[1]))
-
caffe.set_device(
0)
-
caffe.set_mode_gpu()
#如果是CPU训练修改为caffe.set_mode_cpu(),但是好像CPU带不起FCN这个庞大模型(内存不够)
-
-
-
-
solver = caffe.SGDSolver(
'solver.prototxt')
-
#solver.net.copy_from(weights)
-
vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN)
#利用上述加载的vgg_weights和vgg_proto初始化Vgg16网络
-
#将上述网络通过transplant()函数强行复制给FCN32s网络(具体复制方法仍可参见我的
-
#另一篇博客https://blog.csdn.net/qq_21368481/article/details/80289350)
-
surgery.transplant(solver.net, vgg_net)
-
del vgg_net
#删除Vgg16网络
-
-
-
# surgeries
-
interp_layers = [k
for k
in solver.net.params.keys()
if
'up'
in k]
-
surgery.interp(solver.net, interp_layers)
-
-
-
#此处训练集的路径需要换成自己的,其中的seg11valid.txt里存放的是训练集每张图片的文件名(不包含扩展名)
-
#可以自行设置哪些图片作为训练集(个人建议直接拿Segmentation文件夹中的val.txt里的当做训练集)
-
val = np.loadtxt(
'D:/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str)
-
-
-
for _
in range(
25):
-
solver.step(
4000)
-
score.seg_tests(solver,
False, val, layer=
'score')
1.1 运行
在修改完上述文件的情况下,如果是windows下(装了Anaconda的话直接打开Anaconda Prompt,如果没装的话直接cmd打开命令提示符窗口),直接在voc-fcn32s文件路径下输入以下语句即可进行训练。
python solve.py
如下图所示:

如果在linux下,打开终端,也在voc-fcn32s文件路径下输入以下语句:
sudo python solve.py

1.2 常见错误
(1)ImportError: No module named surgery
将与voc-fcn32s文件夹同一根目录下的surgery.py文件复制到voc-fcn32s文件夹中,并在开头添加如下代码:
-
from __future__
import division
-
import sys
-
sys.path.append(
'D:/caffe/caffe-master/python')
#添加自己caffe中的python文件夹路径
-
import caffe
-
import numpy
as np
如果还报No module named score等,同理解决。
(2)路径错误
训练前,还需要修改一下train.prototxt和val.prototxt中的data层中数据集加载路径,拿train.prototxt为例,'sbdd_dir'后的路径修改为自己数据集的路径。
-
layer {
-
name:
"data"
-
type:
"Python"
-
top:
"data"
-
top:
"label"
-
python_param {
-
module:
"voc_layers"
-
layer:
"SBDDSegDataLayer"
-
param_str:
"{\'sbdd_dir\': \'D:/VOC2012\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
-
}
-
}
同时也要修改一下voc_layers.py文件,因为这里面也有训练集和测试集的加载路径,且在训练过程中是会时时通过这个文件下的代码加载训练图片(原因在于上述train.prototxt中是data层中的module:"voc_layers",所代表的意思就是通过voc_layers.py自行定义的训练集和测试集加载方式来加载),测试图片加载同理。
主要修改其中的class SBDDSegDataLayer(caffe.Layer)类中的setup(self, bottom, top)函数中的路径和load_label(self, idx)函数中的数据集格式以及class VOCSegDataLayer(caffe.Layer)类中的setup(self, bottom, top)函数的路径,都修改为自己的。
详细可参见我的另一篇博客:https://blog.csdn.net/qq_21368481/article/details/80246028。
二、实时绘制loss-iter曲线
caffe中的loss分两种,一种是本次单次迭代输出的loss,一种是多次迭代的平均loss,具体可以参见caffe中的src文件夹下的solver.cpp中的Step(int iters) 函数和UpdateSmoothedLoss(Dtype loss, int start_iter, int average_loss) 函数。
如下所示,Iteration 20, loss = 390815中的loss为20次迭代输出的平均loss,而rain net output #0: loss = 151572为本次单次迭代输出的loss,也即为何两者是不同的(只有在Iteration 0时两者才会相同,因为平均loss是从0开始累加求平均计算出来,第0次迭代输出的平均loss就是第0次迭代输出的loss)。
平均loss的好处的更加平滑,当然不用loss直接用单次的loss都是一样的,两者都能反映训练过程中loss的变化趋势。
-
I0611
22:
14:
55.219404
6556 solver.cpp:
228] Iteration
0, loss =
557193
-
I0611
22:
14:
55.219404
6556 solver.cpp:
244] Train net output
#0: loss = 557193 (* 1 = 557193 loss)
-
I0611
22:
14:
55.233840
6556 sgd_solver.cpp:
106] Iteration
0, lr =
1e-010
-
I0611
22:
15:
03.114138
6556 solver.cpp:
228] Iteration
20, loss =
390815
-
I0611
22:
15:
03.114138
6556 solver.cpp:
244] Train net output
#0: loss = 151572 (* 1 = 151572 loss)
-
I0611
22:
15:
03.115141
6556 sgd_solver.cpp:
106] Iteration
20, lr =
1e-010
-
I0611
22:
15:
11.631978
6556 solver.cpp:
228] Iteration
40, loss =
299086
-
I0611
22:
15:
11.632982
6556 solver.cpp:
244] Train net output
#0: loss = 22125.5 (* 1 = 22125.5 loss)
-
I0611
22:
15:
11.634985
6556 sgd_solver.cpp:
106] Iteration
40, lr =
1e-010
-
I0611
22:
15:
19.864284
6556 solver.cpp:
228] Iteration
60, loss =
238765
-
I0611
22:
15:
19.865325
6556 solver.cpp:
244] Train net output
#0: loss = 154152 (* 1 = 154152 loss)
-
I0611
22:
15:
19.866287
6556 sgd_solver.cpp:
106] Iteration
60, lr =
1e-010
1.Step(int iters) 函数
-
template <
typename Dtype>
-
void Solver
::Step(
int iters) {
-
const
int start_iter = iter_;
//起始迭代点
-
const
int stop_iter = iter_ + iters;
//终止迭代点
-
int average_loss =
this->param_.average_loss();
//平均loss=(前average_loss-1次迭代的loss总和+本次迭代的loss)/average_loss
-
losses_.clear();
//清楚用来保存每次迭代所输出的loss
-
smoothed_loss_ =
0;
//smoothed_loss即平均loss(注:每次调用Step()函数平均loss就会清零,即从本次迭代开始重新开始累计求平均)
-
-
while (iter_ < stop_iter) {
-
// zero-init the params
-
net_->ClearParamDiffs();
-
if (param_.test_interval() && iter_ % param_.test_interval() ==
0
-
&& (iter_ >
0 || param_.test_initialization())
-
&& Caffe::root_solver()) {
-
TestAll();
-
if (requested_early_exit_) {
-
// Break out of the while loop because stop was requested while testing.
-
break;
-
}
-
}
-
-
for (
int i =
0; i < callbacks_.size(); ++i) {
-
callbacks_[i]->on_start();
-
}
-
const
bool display = param_.display() && iter_ % param_.display() ==
0;
-
net_->set_debug_info(display && param_.debug_info());
-
// accumulate the loss and gradient
-
Dtype loss =
0;
-
for (
int i =
0; i < param_.iter_size(); ++i) {
//这里的param_.iter_size()对于FCN来说,对应solver.prototxt中的iter_size这个参数
-
loss += net_->ForwardBackward();
//前向计算+后向传播(从中可以看出每次迭代过程中其实是param_.iter_size()次前向计算和后向传播)
-
}
-
loss /= param_.iter_size();
//求平均
-
// average the loss across iterations for smoothed reporting
-
UpdateSmoothedLoss(loss, start_iter, average_loss);
//更新平均loss
-
if (display) {
//一般而言都设置display=average_loss,这里可以看看FCN中是设置
-
LOG_IF(INFO, Caffe::root_solver()) <<
"Iteration " << iter_
-
<<
", loss = " << smoothed_loss_;
//输出平均loss
-
const
vector
*>& result = net_->output_blobs();
-
int score_index =
0;
-
for (
int j =
0; j < result.size(); ++j) {
-
const Dtype* result_vec = result[j]->cpu_data();
-
const
string& output_name =
-
net_->blob_names()[net_->output_blob_indices()[j]];
-
const Dtype loss_weight =
-
net_->blob_loss_weights()[net_->output_blob_indices()[j]];
-
for (
int k =
0; k < result[j]->count(); ++k) {
-
ostringstream loss_msg_stream;
-
if (loss_weight) {
//只有loss层的loss_weight=1,其他层都是0
-
loss_msg_stream <<
" (* " << loss_weight
-
<<
" = " << loss_weight * result_vec[k] <<
" loss)";
-
}
-
LOG_IF(INFO, Caffe::root_solver()) <<
" Train net output #"
-
<< score_index++ <<
": " << output_name <<
" = "
-
<< result_vec[k] << loss_msg_stream.str();
//输出单次迭代的loss值
-
}
-
}
-
}
-
for (
int i =
0; i < callbacks_.size(); ++i) {
-
callbacks_[i]->on_gradients_ready();
-
}
-
ApplyUpdate();
-
-
// Increment the internal iter_ counter -- its value should always indicate
-
// the number of times the weights have been updated.
-
++iter_;
-
-
SolverAction::Enum request = GetRequestedAction();
-
-
// Save a snapshot if needed.
-
if ((param_.snapshot()
-
&& iter_ % param_.snapshot() ==
0
-
&& Caffe::root_solver()) ||
-
(request == SolverAction::SNAPSHOT)) {
-
Snapshot();
-
}
-
if (SolverAction::STOP == request) {
-
requested_early_exit_ =
true;
-
// Break out of training loop.
-
break;
-
}
-
}
-
}
-
void Solver
::UpdateSmoothedLoss(Dtype loss,
int start_iter,
-
int average_loss) {
-
if (losses_.size() < average_loss) {
//如果losses_中还未存储完average_loss次迭代输出的loss,则直接求平均
-
losses_.push_back(loss);
-
int size = losses_.size();
-
smoothed_loss_ = (smoothed_loss_ * (size -
1) + loss) / size;
//求前size次迭代输出的loss的平均值
-
}
else {
//如果losses_中已经存在average_loss次迭代输出的loss,则取离本次迭代最近的average_loss-1次迭代输出的loss与本次loss求平均
-
int idx = (iter_ - start_iter) % average_loss;
-
smoothed_loss_ += (loss - losses_[idx]) / average_loss;
-
losses_[idx] = loss;
//将本次迭代输出的loss存入losses_中的相应位置
-
}
-
}
3.修改后的solve.py文件如下(实现实时绘制loss-iter曲线)
-
#coding=utf-8
-
import sys
-
sys.path.append(
'D:/caffe/caffe-master/python')
-
import caffe
-
import surgery, score
-
-
import numpy
as np
-
import os
-
import sys
-
-
#plot 加载绘制图像所需要的python库
-
import matplotlib.pyplot
as plt
-
from matplotlib.patches
import Circle
-
import math
-
//根据上述UpdateSmoothedLoss()函数修改为python语言而来,目的就是更新平均loss
-
def UpdateSmLoss(loss,losses_,iterval,average_loss,sm_loss):
-
sizel = len(losses_)
-
listloss=loss.tolist()
#array转化为list
-
if sizel < average_loss:
-
losses_.append(listloss)
-
sm_loss = (sm_loss*sizel+listloss)/(sizel+
1)
-
else:
-
idx = iterval % average_loss
-
sm_loss += (listloss-losses_[idx]) / average_loss
-
losses_[idx] = listloss
-
return sm_loss,losses_
-
-
try:
-
import setproctitle
-
setproctitle.setproctitle(os.path.basename(os.getcwd()))
-
except:
-
pass
-
-
vgg_weights =
'vgg16-fcn.caffemodel'
-
vgg_proto =
'vgg16_deploy.prototxt'
-
#weights = 'vgg16-fcn.caffemodel'
-
-
# init
-
#caffe.set_device(int(sys.argv[1]))
-
caffe.set_device(
0)
-
caffe.set_mode_gpu()
-
-
#solver = caffe.SGDSolver('solver.prototxt')
-
#solver.net.copy_from(weights)
-
solver = caffe.SGDSolver(
'solver.prototxt')
-
-
#parameter 实时绘制所需要的一些参数
-
niter =
100000
#对应solver.prototxt中的max_iter: 100000
-
display =
20
#对应solver.prototxt中的display: 20
-
snapshotnum =
4000
#对应solver.prototxt中的snapshot: 4000
-
ave_loss =
20
#对应solver.prototxt中的average_loss: 20
-
#losses_用于存储当前迭代次数的前average_loss次迭代所产生的loss
-
losses_ = []
-
sm_loss =
0
#平均loss
-
#train_loss 用于存储每次的sm_loss,以便画折线图
-
train_loss = np.zeros(np.ceil(niter *
1.0 / display))
-
-
-
-
vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN)
-
surgery.transplant(solver.net, vgg_net)
-
del vgg_net
-
-
# surgeries
-
interp_layers = [k
for k
in solver.net.params.keys()
if
'up'
in k]
-
surgery.interp(solver.net, interp_layers)
-
-
# scoring
-
val = np.loadtxt(
'D:/VOC2012/ImageSets/Segmentation/seg11valid.txt', dtype=str)
-
-
#for _ in range(25):
-
#solver.step(4000)
-
#score.seg_tests(solver, False, val, layer='score')
-
-
plt.close()
-
fig=plt.figure()
-
ax=fig.add_subplot(
1,
1,
1)
-
plt.grid(
True)
-
plt.ion()
#开启交互式绘图(实现实时绘图的关键语句)
-
for it
in range(niter):
-
solver.step(
1)
#python下的step()函数,对应于上述Step()函数
-
_train_loss = solver.net.blobs[
'loss'].data
#取出每次迭代输出的loss
-
[sm_loss,losses_] = UpdateSmLoss(_train_loss,losses_,it,ave_loss,sm_loss)
#更新
-
if it % display ==
0
and it !=
0:
#满足条件时展示平均loss
-
ax.scatter(it,sm_loss,c =
'r',marker =
'o')
#绘制loss的散点图
-
train_loss[it // display -
1] = sm_loss
#存储平均loss
-
if it > display:
-
ax.plot([it
-20,it],[train_loss[it // display -
2],train_loss[it // display -
1]],
'-r')
#绘制折线图
-
plt.pause(
0.0001)
-
if it % snapshotnum ==
0
and it !=
0:
#对应原solve.py文件中的最后两句代码,每snapshotnum次迭代进行一次测试
-
score.seg_tests(solver,
False, val, layer=
'score')
-
losses_ = []
#测试后需要清空losses_以及平均loss,对应于每次进入Step()函数都需要对这两者清空
-
sm_loss =
0
效果图如下:
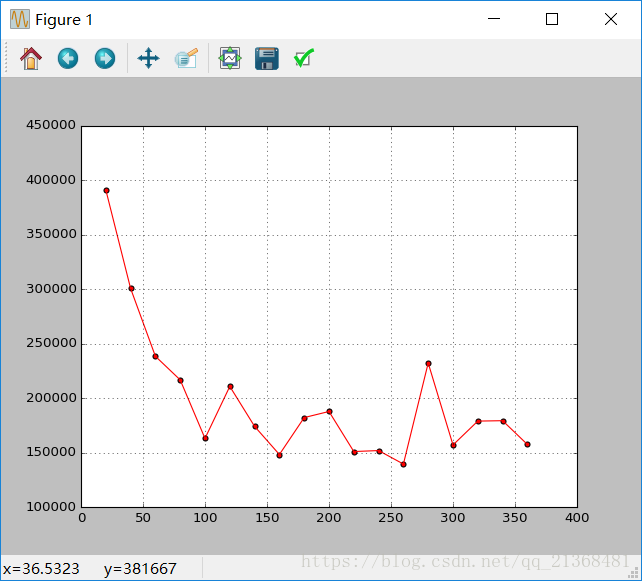
注:可以发现在训练过程中输出的本次单次迭代loss和多次迭代的平均loss是一样的,原因在于每次进入到Step()函数都需要对losses_ 和smoothed_loss清空导致每次进入Step()函数后losses_的大小总为0,也就只会进入if (losses_.size() < average_loss)这个条件里,导致两种loss相同。
-
I0611
22:
08:
17.291122
8428 solver.cpp:
228] Iteration
160, loss =
63695.3
-
I0611
22:
08:
17.291122
8428 solver.cpp:
244] Train net output
#0: loss = 63695.3 (* 1 = 63695.3 loss)
-
I0611
22:
08:
17.292124
8428 sgd_solver.cpp:
106] Iteration
160, lr =
1e-010